

Context Prior for Scene Segmentation带上下文先验的分割
Context Prior for Scene Segmentation
* Authors: [[Changqian Yu]], [[Jingbo Wang]], [[Changxin Gao]], [[Gang Yu]], [[Chunhua Shen]], [[Nong Sang]]
初读印象
comment:: (CPNet)使了Affinity损失,构造亲和力矩阵,直接监督特征聚合来取费类间语义和类内语义。Code:https://git.io/ContextPrior
Why
- 金字塔结构的模型获取了同质化的语义信息,忽视了不同类别的上下文依赖。
- 注意力不对关系描述进行正则化,会选择不必要的上下文依赖
以上两种方法都对上下文依赖不做区分,导致类别间的混淆。
What
类内上下文的同一性和类间上下文的差异性可以使得特征表示更加鲁棒,因此将类别关系设为先验。对于特征图中的每个像素,先验图可以有选择地突出属于同一类别的其他像素来聚合类内上下文,而反转先验可以聚合类间上下文。
How
Affinity Loss
亲和力损失迫使网络考虑相同类别的像素不同类别之间的像素。
- 亲和力矩阵:
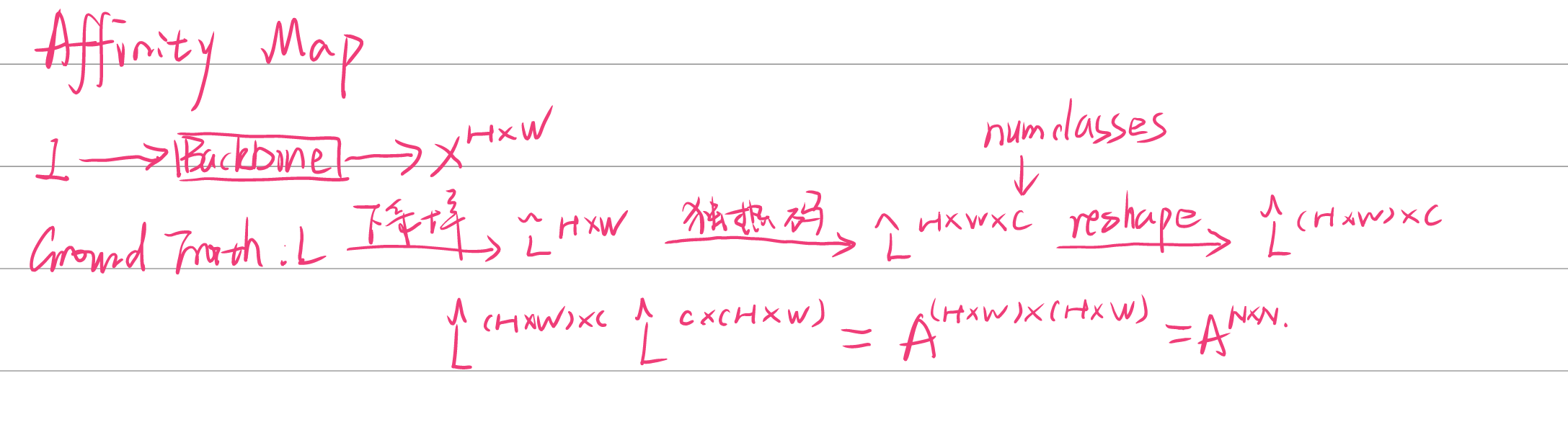

预测先验矩阵和亲和力矩阵大小相同。对于先验矩阵中的一个点\(p_n\),它和亲和力矩阵中的点\(a_n\) 的交叉熵损失为:
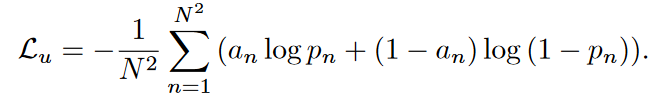 但是以上损失只考虑孤立的点,综合考虑组间和组内点的关系得到的损失函数:
但是以上损失只考虑孤立的点,综合考虑组间和组内点的关系得到的损失函数:
其中三个损失函数分别为组间预测准确率、组间预测召回、组内预测召回。
最终得到的损失为
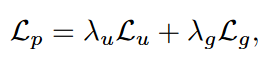 ####Context Prior Layer(上下文先验层)
####Context Prior Layer(上下文先验层)
其中N是\(N\times C_1\)。

Aggregation
使用全分离(空间+深度)卷积来先聚合一些空间信息。
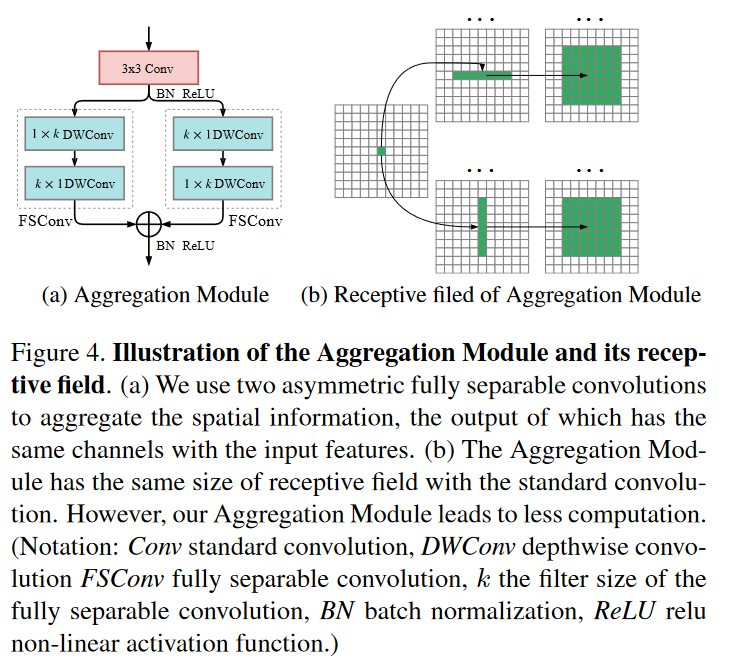 *空间可分离卷积:对于\(k \times k\) 的卷积,先让\(k\times 1\)卷积先扫全图一遍,然后\(1\times k\)再扫全图一遍。
*空间可分离卷积:对于\(k \times k\) 的卷积,先让\(k\times 1\)卷积先扫全图一遍,然后\(1\times k\)再扫全图一遍。
- 深度可分离卷积:每个通道应用一个卷积核。
总体架构
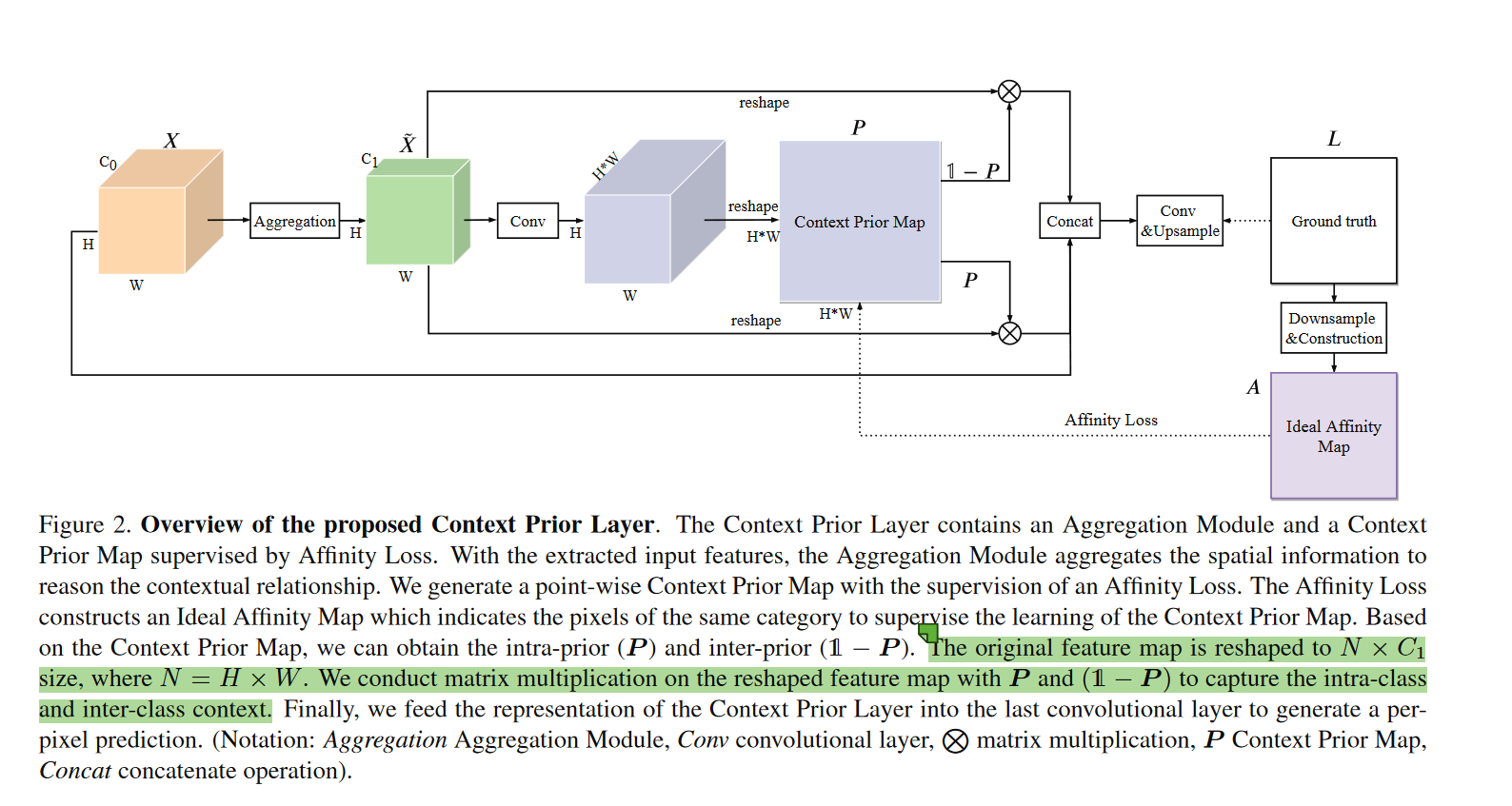
- backbone:用空洞卷积的ResNet
- 在resnet_stage_4使用辅助损失
- 总损失为
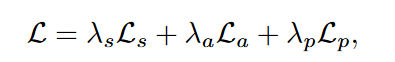
其中三个损失分别为分割损失、辅助损失和亲和力损失,权重使用1\0.4\1。
Experiment
先验矩阵的可视化,其中注意力矩阵是没有Affinity Loss监督得到的。

Conclusion
用Affinity Loss来监督先验矩阵很有创意。
