

Non-local Neural Networks 第一次将自注意力用于cv
Non-local Neural Networks
* Authors: [[Xiaolong Wang]], [[Ross Girshick]], [[Abhinav Gupta]], [[Kaiming He]]
初读印象
comment:: (NonLocal)过去的网络注重处理局部关系,本篇网络研究了长程依赖。
Why
过去的网络,长程依赖都是依靠大量堆叠卷积得到的大感受野所建立的。
- 计算效率低。
- 难以优化。
- 难以多跳依赖性建模。
相关工作
- 非局部处理:非局部平均、BM3D
- CRF
- 使用深度1-D卷积的前馈网络
- 自注意力,本文可以视为对自注意力在cv的推广
- 交互网络(Interaction Networks)
What
提出一种非局部操作:一个点的值是所有其他位置的点的带权重的和。
- 直接、显式地计算任意两个点之间的关系,而非通过重复卷积。
- 效率高、计算量小。
- 不改变输入特征的尺寸,且易与其他操作结合。
How
非局部操作:
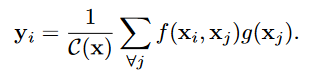
- \(x\)是输入特征,\(y\)是和\(x\)相同大小的输出,\(x_i\)可以是一个标量,也可以是一个向量
- \(f\)是\(x_i\)和\(x_j\)之间的关系函数(标量),\(g\)是输入\(x_j\)的一元函数,\(C(x)\)用于正则化
不同的\(f\)实例(\(g(x_j) = W_gx_j\)):
- 高斯函数\(f(x_i,x_j) = e^{{x_i}^Tx_j}\),其中\(x_i^Tx_j\)为点积。\(C(x)=\sum_{\forall j} f(x_i,x_j)\)
- 嵌入高斯\(f(x_i,x_j) = e^{\theta(x_i)^T \phi(x_j)}\),其中\(\theta(x_i)=W_\theta x_i\),\(\phi(x_j)=W_\phi x_j\)。\(C(x)=\sum_{\forall j} f(x_i,x_j)\)
- 点积:\(f(x_i,x_j) = \theta(x_i)^T \phi(x_j)\),其中\(\theta(x_i)=W_\theta x_i\),\(\phi(x_j)=W_\phi x_j\),\(C(x)=N\)
- 拼接:\(f(x_i,x_j) = ReLU(W^T_f[\theta(x_i),\phi(x_j)]\),其中\(W^T_f\)维度和后者的拼接相同。\(C(x)=N\)
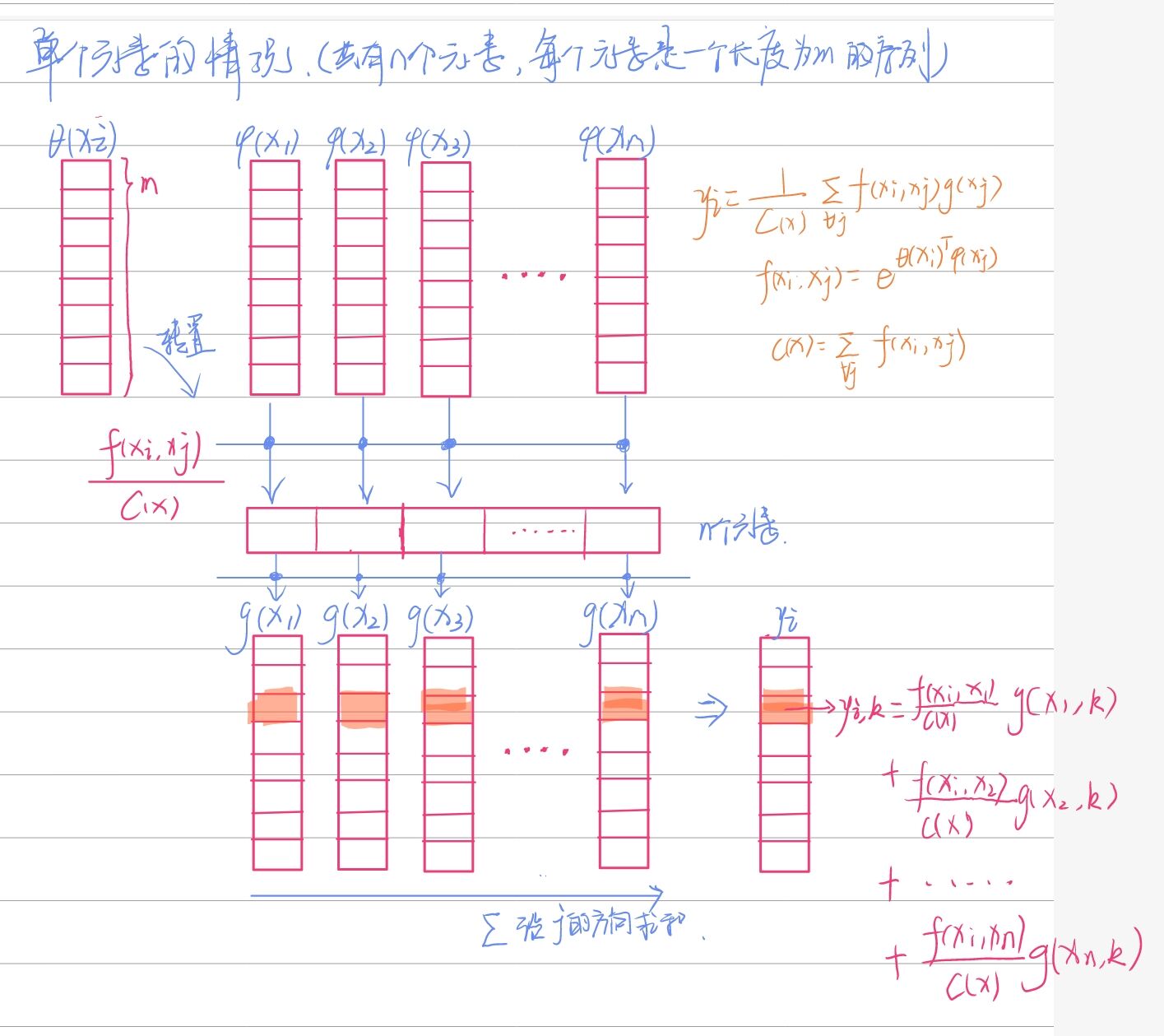
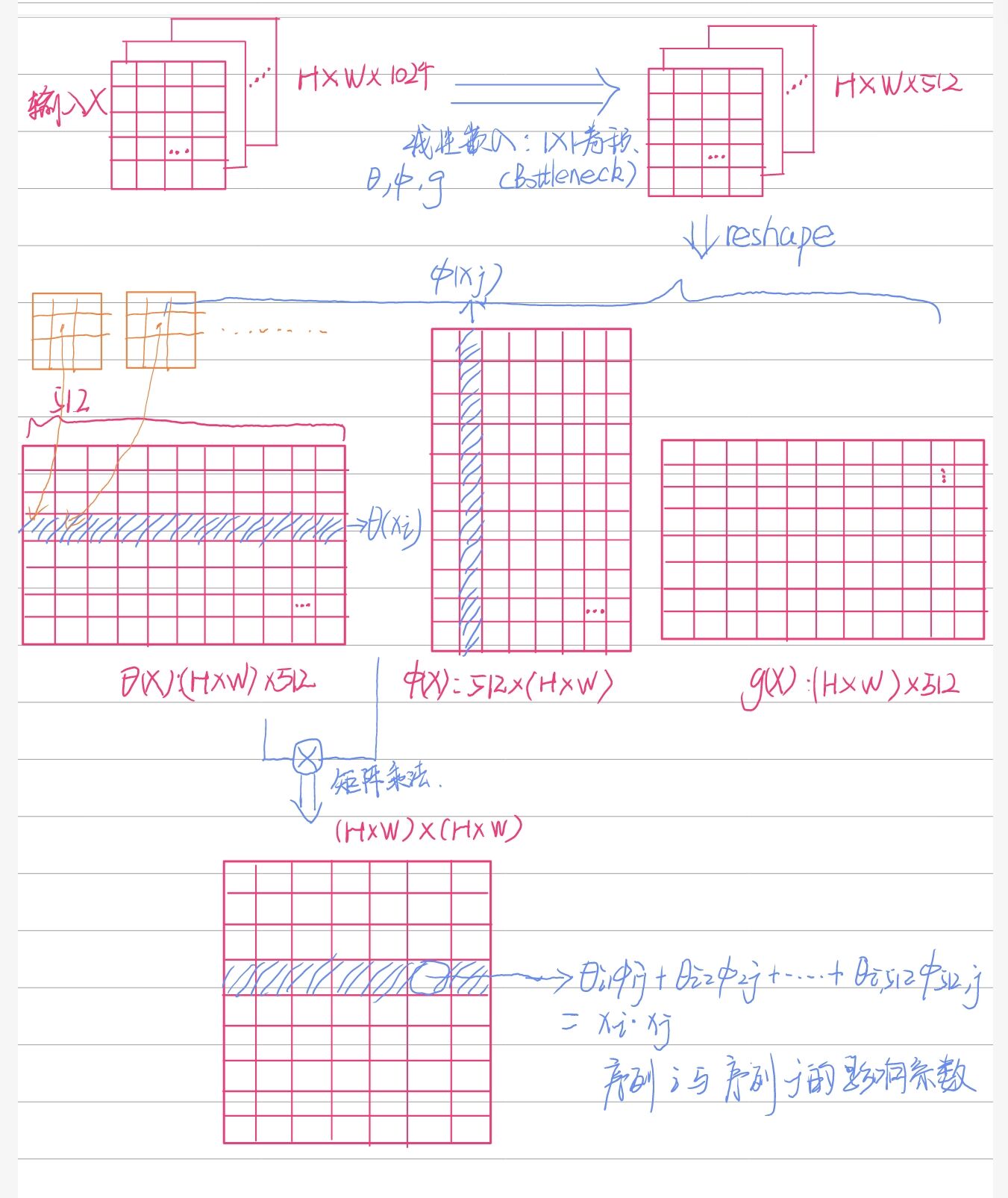
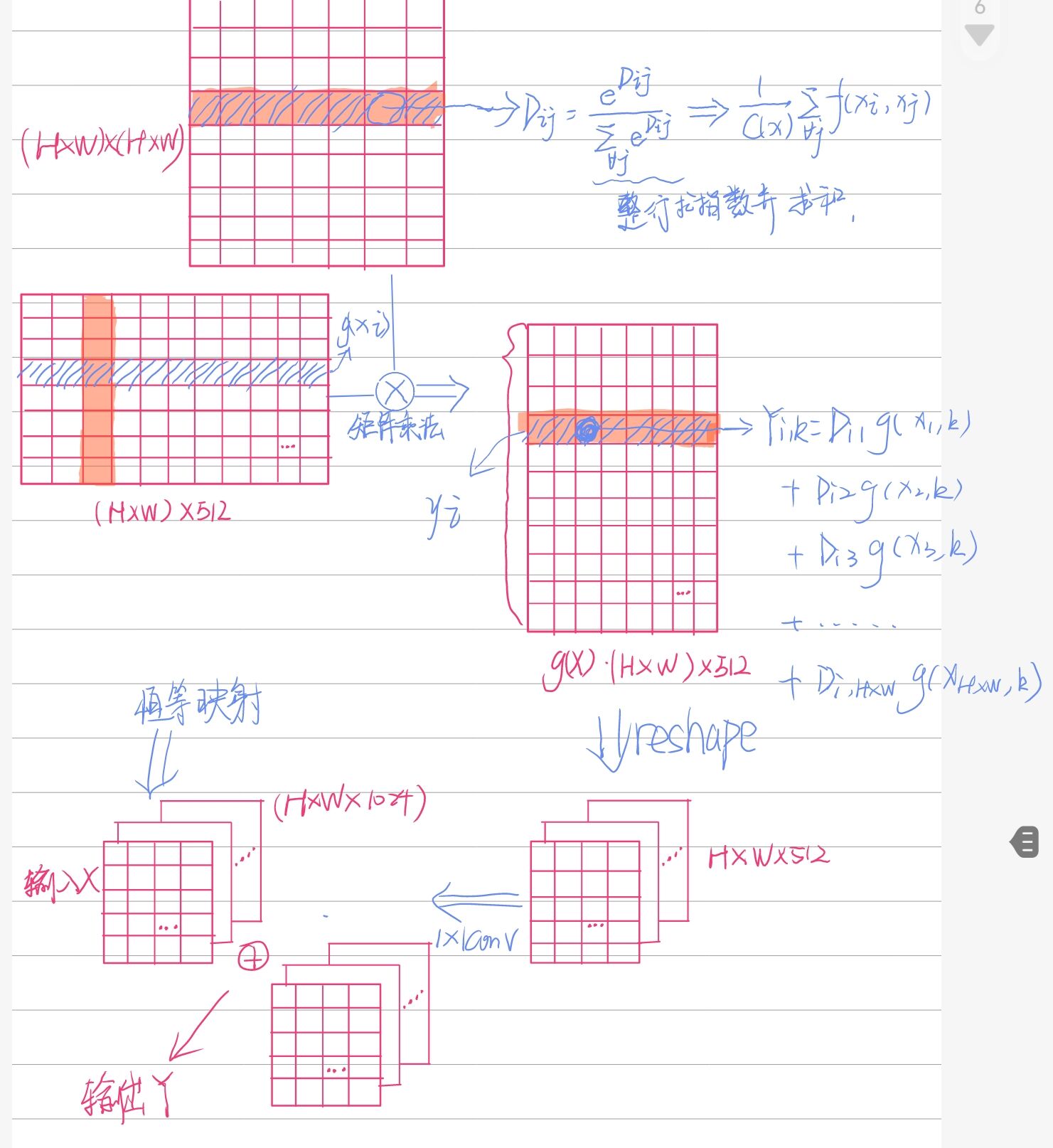
非局部块(从左到右分支名分别为a、b、c、d):


- 分支a是一个恒等映射;
- 分支b、c、d分别使用1×1卷积作为\(\theta,\phi,g\)运算,将通道数减少到512(Bottleneck),并对输入特征reshape,变为THW×512的矩阵。该矩阵中每一行为一个基本元素(一行中的所有点对应的是所有通道中的相同的那个点)。
- b与转置后的c进行矩阵乘法,得到关联矩阵,关联矩阵沿着行进行softmax。
- 关联矩阵与d进行矩阵乘法,reshape并1×1卷积(\(W_z\))增加通道数。
- 与恒等映射相加。
代码
import torch
from torch import nn
from torch.nn import functional as F
class _NonLocalBlockND(nn.Module):
"""
调用过程
NONLocalBlock2D(in_channels=32),
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, sub_sample=sub_sample,
bn_layer=bn_layer)
"""
def __init__(self,
in_channels,
inter_channels=None,
dimension=3,
sub_sample=True,
bn_layer=True):
super(_NonLocalBlockND, self).__init__()
assert dimension in [1, 2, 3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
# 进行压缩得到channel个数
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels,
out_channels=self.in_channels,
kernel_size=1,
stride=1,
padding=0), bn(self.in_channels))
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels,
out_channels=self.in_channels,
kernel_size=1,
stride=1,
padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
self.phi = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)
def forward(self, x):
'''
:param x: (b, c, h, w)
:return:
'''
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1)#[bs, c, w*h]
g_x = g_x.permute(0, 2, 1)
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
theta_x = theta_x.permute(0, 2, 1)
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
f = torch.matmul(theta_x, phi_x)
print(f.shape)
f_div_C = F.softmax(f, dim=-1)
y = torch.matmul(f_div_C, g_x)
y = y.permute(0, 2, 1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)
z = W_y + x
return z
- 减少运算量:
- 使用了Bottleneck
- 可以在\(\phi,g\)后面增加pooling层下采样。
Experiment
3D卷积:卷积核为3D,并且能够沿着深度方向卷积(2D的卷积核只能沿着平面卷积)。下图中每个立方体表示一个通道,多出的一维是因为增加了时间。
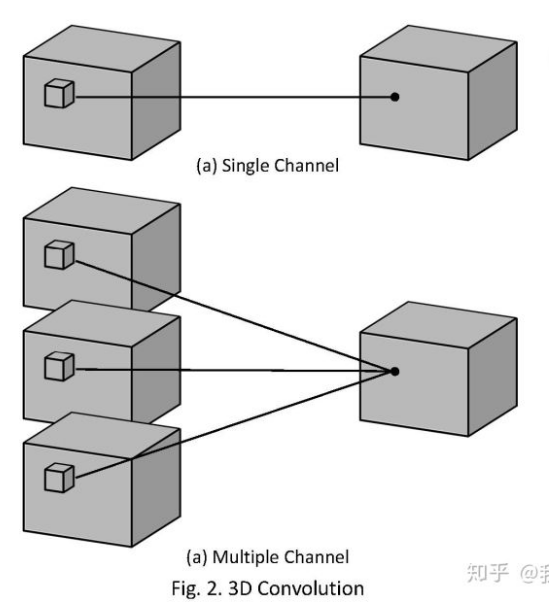
视频分类模型
- 实验模型:
-
C2D:增加了3D池化的resnet
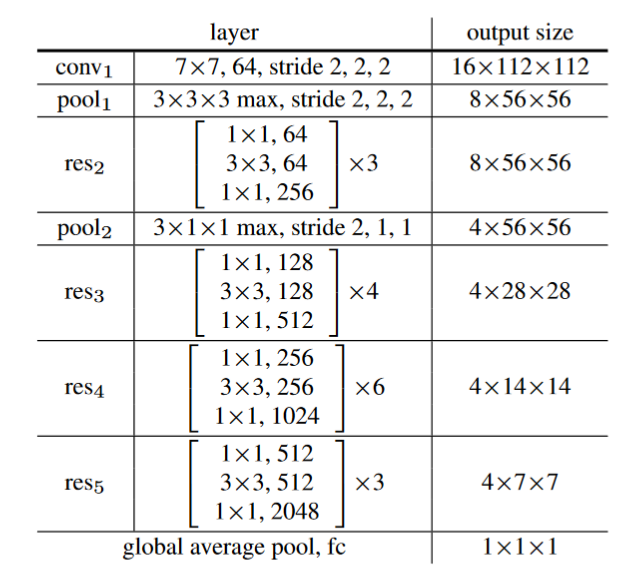
-
I3D3×3×3:将残差结构中的3×3卷积膨胀成了3D的(conV1为5×7×7)
-
I3D3×1×1:将残差结构中的第一个1×1卷积膨胀成了3D的(conV1为5×7×7)
-
Non-local network:将non-local块插入以上三个网络中
- 实现细节:
- 训练
- non-local块中的参数被初始化为0,保证刚开始训练时该结构为一个恒等映射,使其能够从任何预训练网络上开始训练。
- 训练
Kinetics
video数据集,包含400种人类动作。
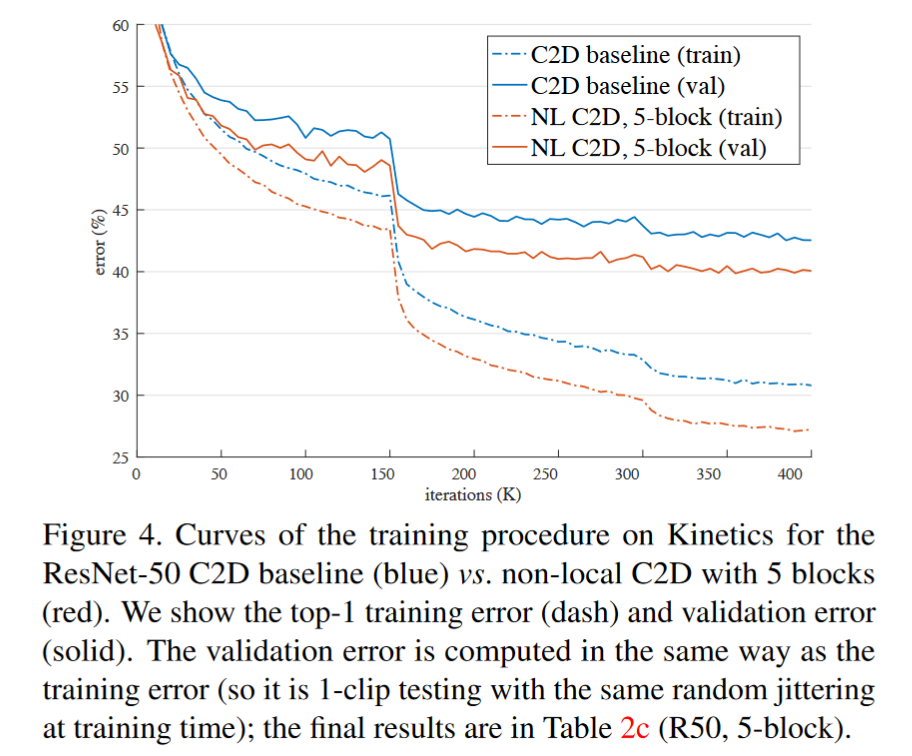
C2D和nonlocal-C2D比较,nonlocal明显更优
 *消融实验:
*消融实验:
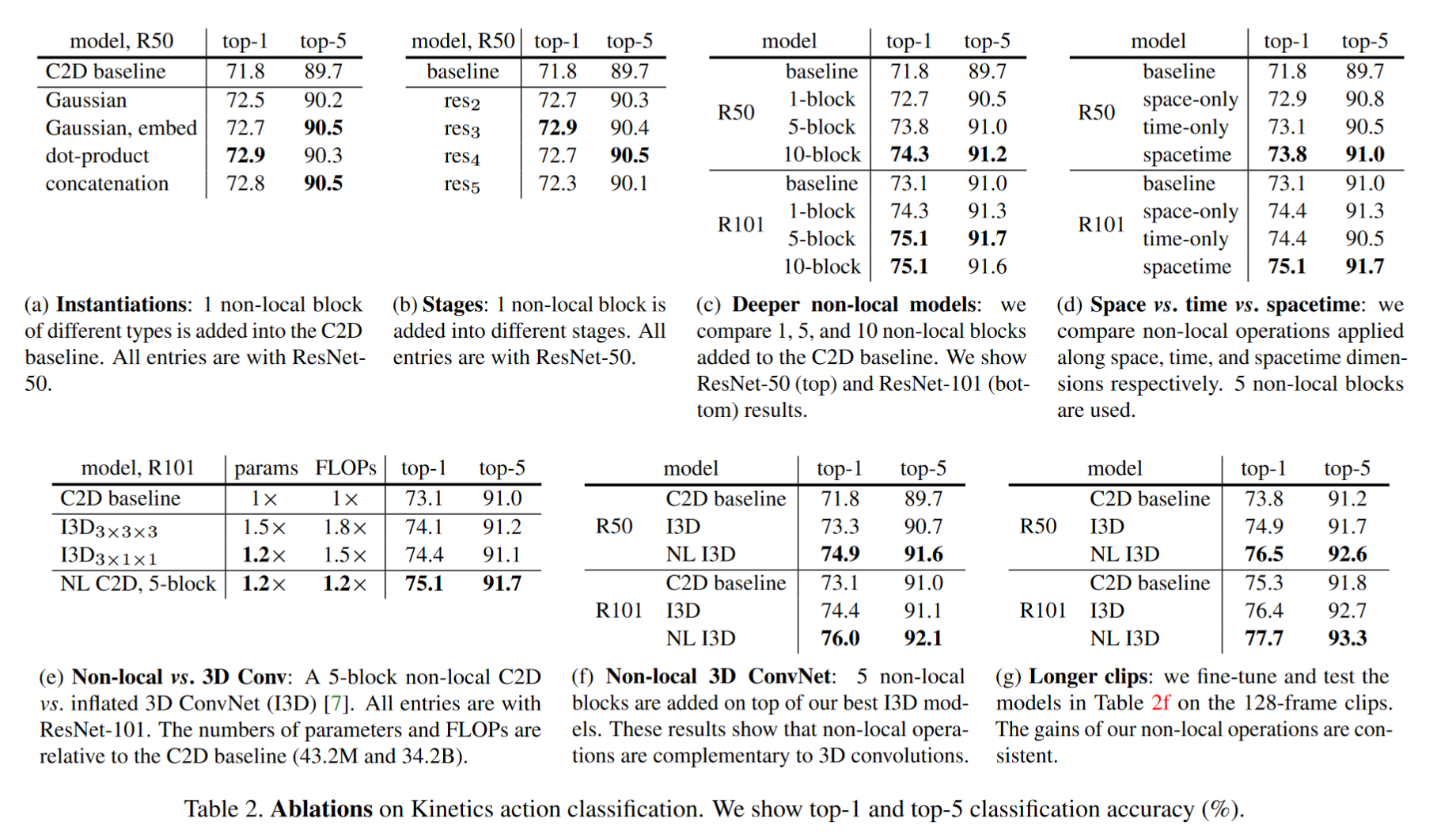
(a)增加不同的nonlocal块,最少也有1%提升。
(b)不同stage加入nonlocal块的效果,stage5效果较差,可能是因为尺寸太小空间信息不明显。
(c)增加不同数量的局部块的效果,越多效果越好。5-block resnet50比resnet101效果好,证明效果提升不单纯是因为深度的提升。
(d)时间、空间和时空下的不同测试,仅在时间、空间下分别使用nonlocal,效果提升,但是不如在时空环境下同时使用。
(e)2Dnonlocal和3D相比,2Dnonlocal准确率更高且计算量更小。
(f)将nonlocal插入I3D3×1×1,两者是互补的(3D注重局部,nonlocal注重长程依赖)。
(g)研究在长视频的效果,结果表明,在128帧视频上的效果比在32帧上效果更好。
不需要任何其他处理效果就很好

Conclusion
不再将计算局限于一个小的卷积核内,而是显式地计算所有点之间的相关性。可以作为和卷积互补的操作。

