Local Relation Networks for Image Recognition: LRNet
Local Relation Networks for Image Recognition
* Authors: [[Han Hu]], [[Zheng Zhang]], [[Zhenda Xie]], [[Stephen Lin]]
@inproceedings{Hu2019,
doi = {10.1109/iccv.2019.00356},
url = {https://doi.org/10.1109/iccv.2019.00356},
year = {2019},
month = oct,
publisher = {{IEEE}},
author = {Han Hu and Zheng Zhang and Zhenda Xie and Stephen Lin},
title = {Local Relation Networks for Image Recognition},
booktitle = {2019 {IEEE}/{CVF} International Conference on Computer Vision ({ICCV})}
}
初读印象
comment:: (LR-Net)提出了一种新的图像特征提取器,称为局部关系层,它根据局部像素对的组合关系自适应地确定聚合权重。
动机
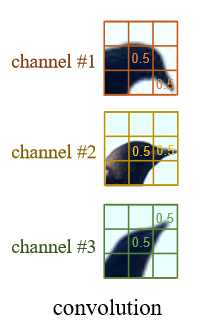
- 卷积(Convolution)的缺点:卷积在将低层特征构造成高层特征的概念推理十分低效,它只是充当一个滤波器对元素进行空间聚合。当某个物体拥有多种几何形变时,很难推理出一个合适的滤波器(如不同形状的鸟嘴),即可组合性不强。
![Pasted image 20221016151333]() *胶囊网络(Capsule networks):通过迭代的路由过程来计算可组合性。在每个路由步骤中,如果聚合前和聚合后的向量彼此接近,则会放大聚合权重,否则会减小聚合权重。但是这种方法不能使用反向传播来迭代,适用性不强。
*胶囊网络(Capsule networks):通过迭代的路由过程来计算可组合性。在每个路由步骤中,如果聚合前和聚合后的向量彼此接近,则会放大聚合权重,否则会减小聚合权重。但是这种方法不能使用反向传播来迭代,适用性不强。 - 自注意力(self-attention):应用于图像识别中的自注意力通常只是作为卷积层的补充,而非寻找一种新的拥有更强空间合成能力的图像特征提取器。
- 目标:提出一种方法,能够自适应地对局部区域内的像素进行组合以建立更有效和高效的组合层次结构。
 *胶囊网络(Capsule networks):通过迭代的路由过程来计算可组合性。在每个路由步骤中,如果聚合前和聚合后的向量彼此接近,则会放大聚合权重,否则会减小聚合权重。但是这种方法不能使用反向传播来迭代,适用性不强。
*胶囊网络(Capsule networks):通过迭代的路由过程来计算可组合性。在每个路由步骤中,如果聚合前和聚合后的向量彼此接近,则会放大聚合权重,否则会减小聚合权重。但是这种方法不能使用反向传播来迭代,适用性不强。方法
一种新的信息聚集方法,类似于卷积核,但是同一个卷积核在不同点上的权重是固定的,该方法的权重是自适应的,而且比卷积核有更大的聚集范围(kernel size)
Local Relation Layer
-
聚合方法
![Pasted image 20221017101629]()
-
目标像素:\(p'\)
-
目标像素位置范围内的点:\(p\)
-
\(\phi(f_{{\theta}_q}(x_{p'}),f_{\theta{_k}}(x_p))\):转换后的\(p'\)点和\(q\)点之间的可组合性的度量,最优做法为乘法:
![Pasted image 20221017105126]() *\(f_{\theta{_q}}\)和\(f_{\theta{_p}}\)分别使用一个\(1\times 1\)卷积将目标元素转换成query和key。此处使用的key和value是标量(即通道数为1)。
*\(f_{\theta{_q}}\)和\(f_{\theta{_p}}\)分别使用一个\(1\times 1\)卷积将目标元素转换成query和key。此处使用的key和value是标量(即通道数为1)。 -
几何先验\(f_{\theta{_g}}\):两个\(1\times 1\)卷积,中间夹着ReLU。
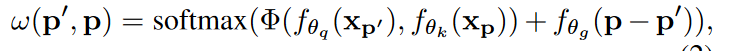
 *
*局部关系层的网络结构
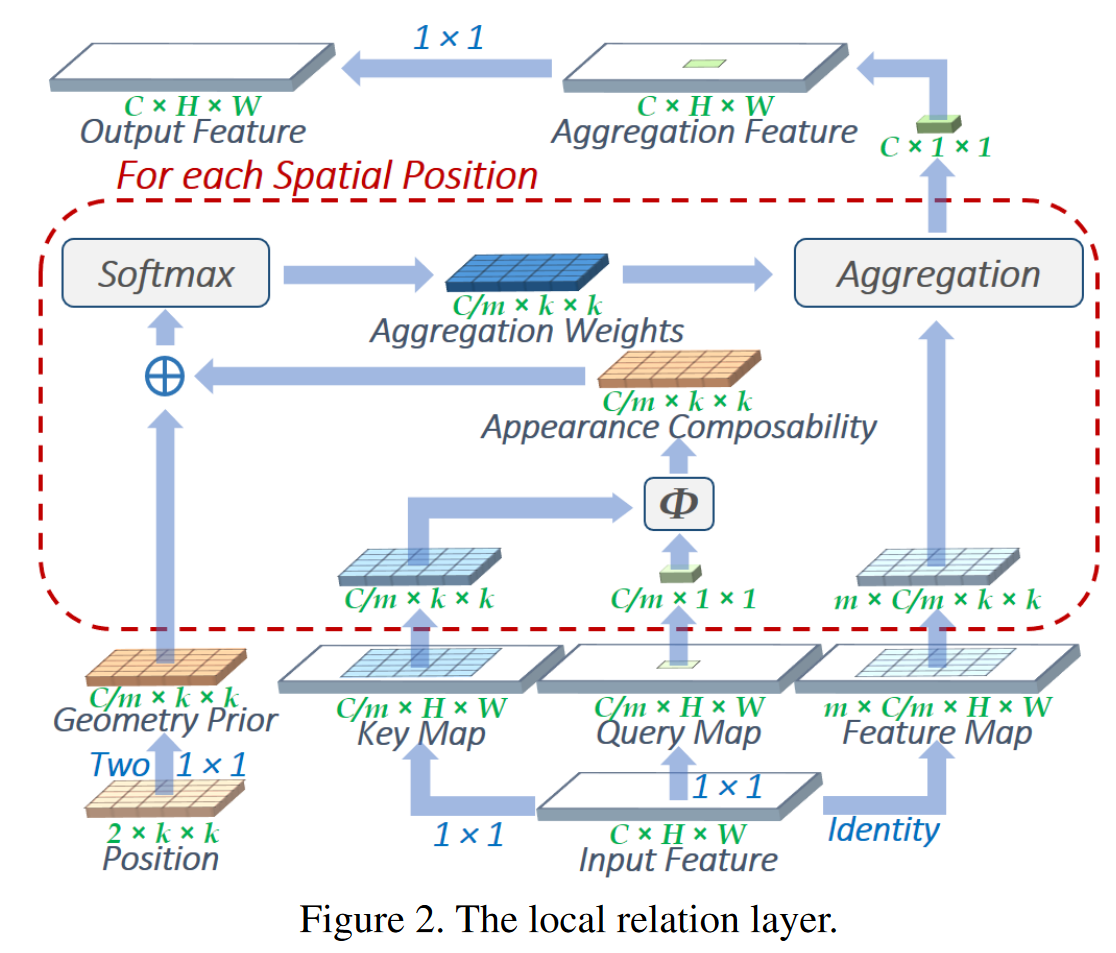
- Input Feature分别经过\(1\times 1\)卷积得到K和Q,通道数为C//m(多通道权重共享,此处m为8),以下以Q、K中一个通道的数据为例做说明。
- 从Q中取出目标点p'的特征向量,K中取出以p'为中心的大小为\(k\times k\)的特征矩阵,前者以广播的形式与后者相乘,得到Appearance Composability。
- Position(文中没有给出该矩阵是如何得到的,同时本文也没有提供官方代码)经过两个\(1\times 1\)卷积得到Geometry Prior,将其与Appearance Composability相加。相加后的矩阵经过softmax得到Aggregation Weights。
- 在原Input Feature中取出以p'为中心的m个通道大小为\(k\times k\)的矩阵,将其与Aggregation Weights相乘并相加得到加权和(权重共享),即得到m层的目标像素p’的经过局部关系块加强后的点。
改造自Resnet的LR-Net
将Resnet中的各个结构换成LR结构。
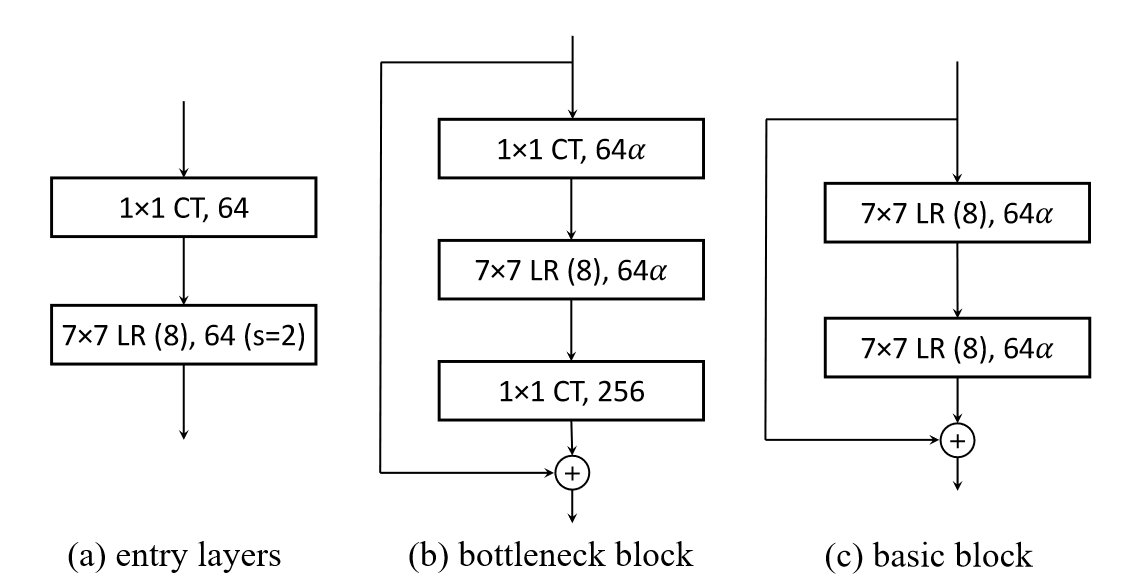 (a)Resnet的\(7\times7\)卷积,可以代替为一个输出通道为64的\(1\times1\)卷积,并加一个kernel size=7的LR,共享层数为8,步长为2。
(a)Resnet的\(7\times7\)卷积,可以代替为一个输出通道为64的\(1\times1\)卷积,并加一个kernel size=7的LR,共享层数为8,步长为2。
(b) 有Bottleneck的残差块。
(c) 无Bottleneck的残差块。
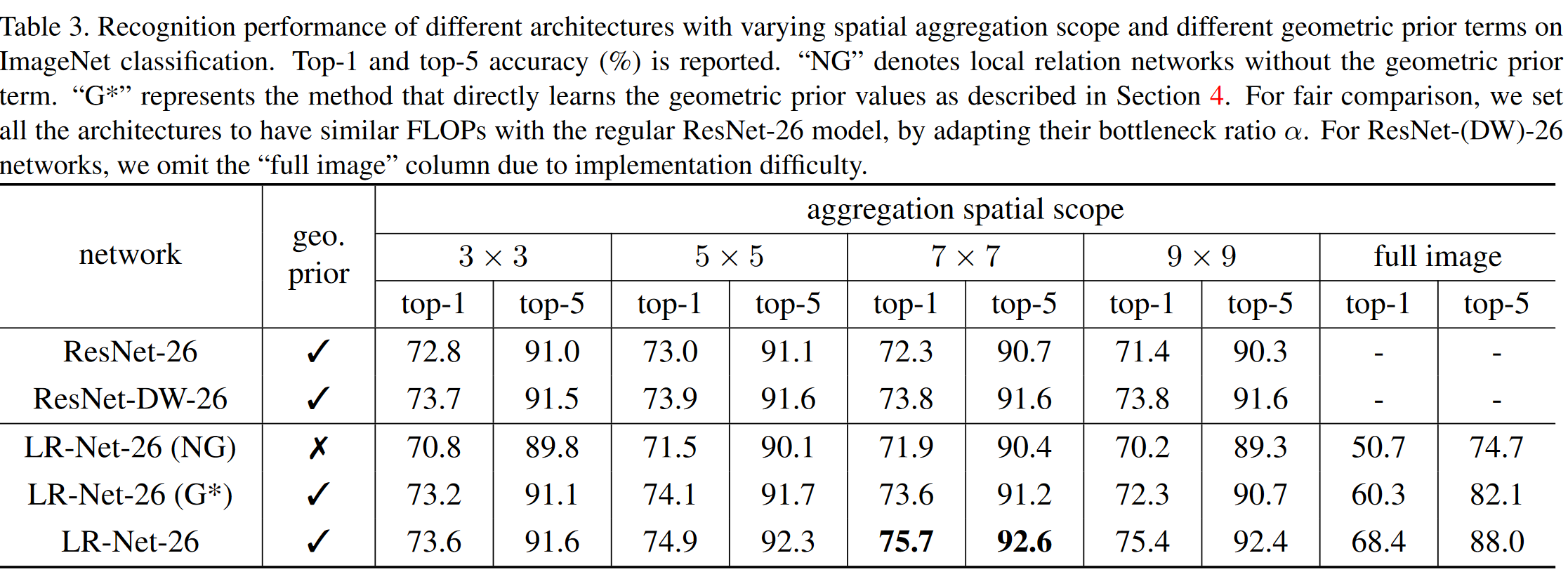
模型表现
在ImageNet上 的表现,当参数量与计算量和Resnet差不多时,模型表现更好。
输入输出
图像分类:输入一张图片,得到对这张图片的分类。
局限
局部关系块只关心了同一通道的特征图的各像素之间的关系,不同通道之间关系只通过\(1\times1\)卷积来构建,可以考虑使用SENet或LANet中对通道注意力的使用,将不同通道之间的像素信息聚合到一个点上。
启示
在卷积中,卷积核的权重是学习到的。该文提出的局部关系块的权重是算出来的,这也是文中所说的权重是“自适应”的原因。本文还对不同通道的特征图使用了权重共享,这也是一种能够在不降低模型性能下减少模型参数量和计算量的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号