
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows详解
初读印象
comment:: (Swin-transformer)代码:https://github. com/microsoft/Swin-Transformer
动机
将在nlp上主流的Transformer转换到cv上。存在以下困难:
- nlp中单词标记是一个基本单元,但是视觉元素在尺度上有很大的变化。
- 图像分辨率高,自注意力操作计算复杂度是图像大小的二次方
提出了一种通用的Transformer主干,称为Swin Transformer,它构造了分层的特征映射,并且具有与图像大小相关的线性计算复杂度。Swin Transformer通过从小尺寸的补丁,并在更深的Transformer层中逐渐合并相邻的补丁来构造分层表示。通过这些分层特征图,Swin Transformer模型可以方便地利用先进的密集预测技术,如特征金字塔网络( FPN )或U - Net。线性计算复杂度是通过在划分图像(用红色勾画)的非重叠窗口内局部计算自注意力来实现的。每个窗口中的补丁数量是固定的,因此复杂度与图像大小成线性关系。
方法
总体架构(以简易版本Swin-T为例)
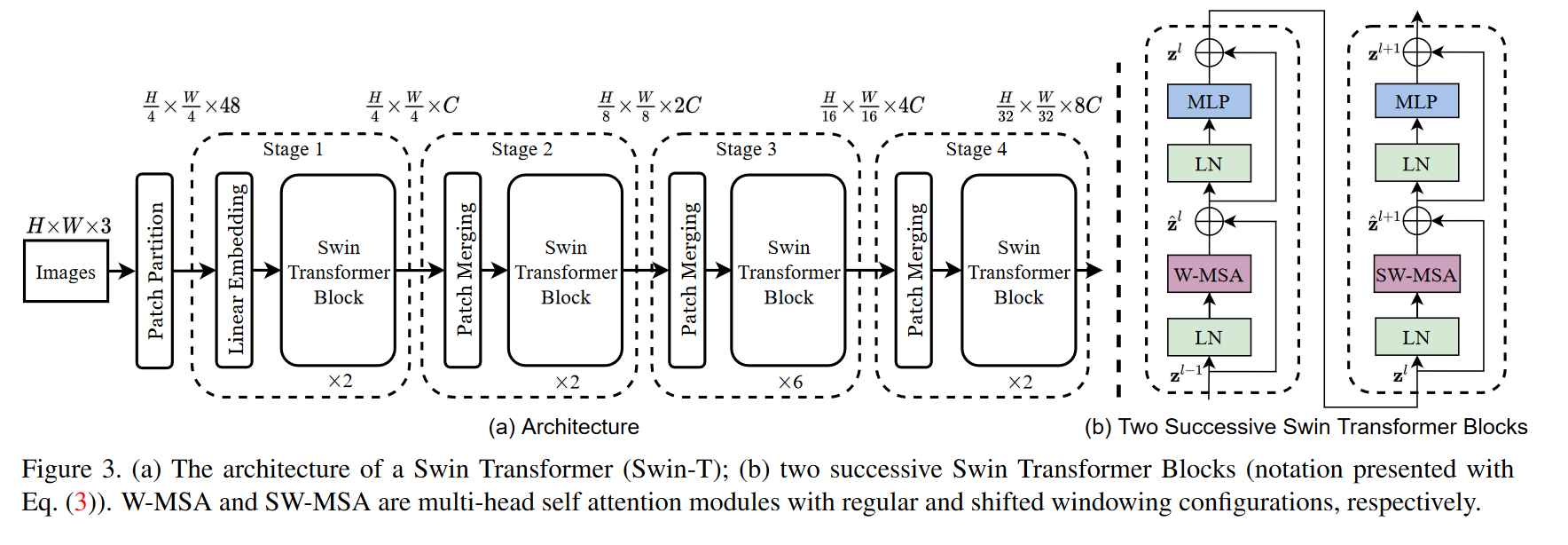
- Patch Parition:将整张图片切片,此处切成
- Stage1:将token经过一个线性嵌入层变为长度为C的特征向量,整张图变成
- Stage2: 一个Patch Merging再加上两个Swin Transformer Block。
- Patch Merging:为了产生层次化的表示,随着网络的加深,通过补丁合并层来减少token的数量。合并相邻的
- Patch Merging:为了产生层次化的表示,随着网络的加深,通过补丁合并层来减少token的数量。合并相邻的
- stage3:同stage2,整张图变为
- stage4:同stage2,整张图变为
Swin Trasformer Block
将Transformer中的多头注意力模块换成了窗口多头注意力(WIndow-MSA)和移动窗口多头注意力(Shifted Window-MSA)
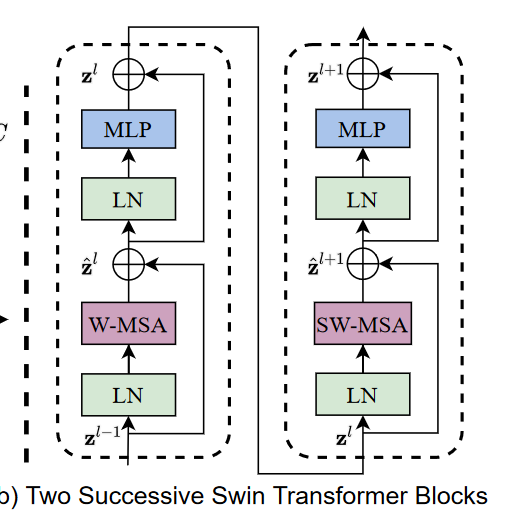 只在窗口中做自注意力能够减少计算复杂度,但是这将减少跨窗口的连接,减少模型建模能力,因此在两个利纳许的SwinTransformer Blocks中交替使用两种划分的移动窗口。
只在窗口中做自注意力能够减少计算复杂度,但是这将减少跨窗口的连接,减少模型建模能力,因此在两个利纳许的SwinTransformer Blocks中交替使用两种划分的移动窗口。
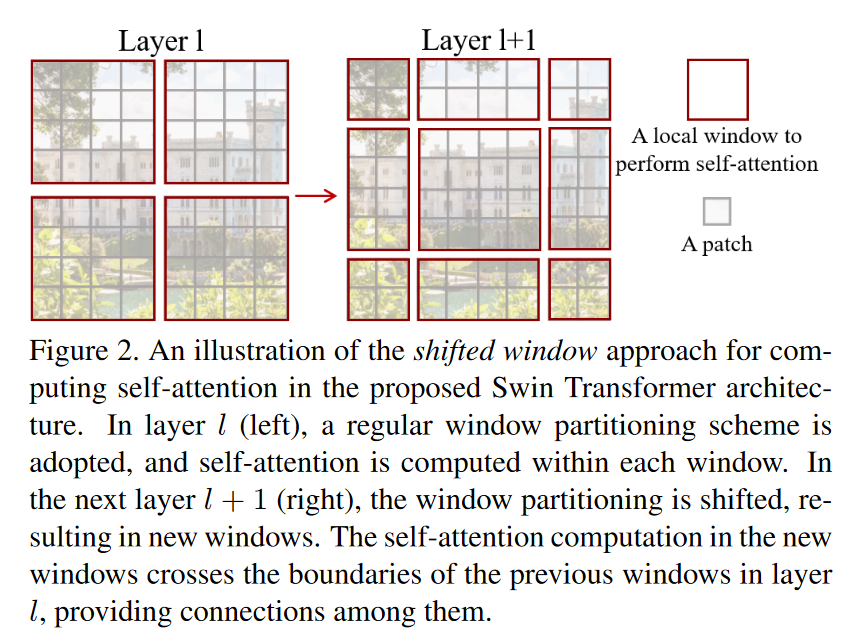
- 第l层:使用规则的大小为
- 第l+1层:将l层的规则窗口移位
相对位置编码
在每个窗口中使用相对位置编码
 其中
其中
模型变种

输入输出
输入为一张图片,输出根据任务的不同而不同。
表现
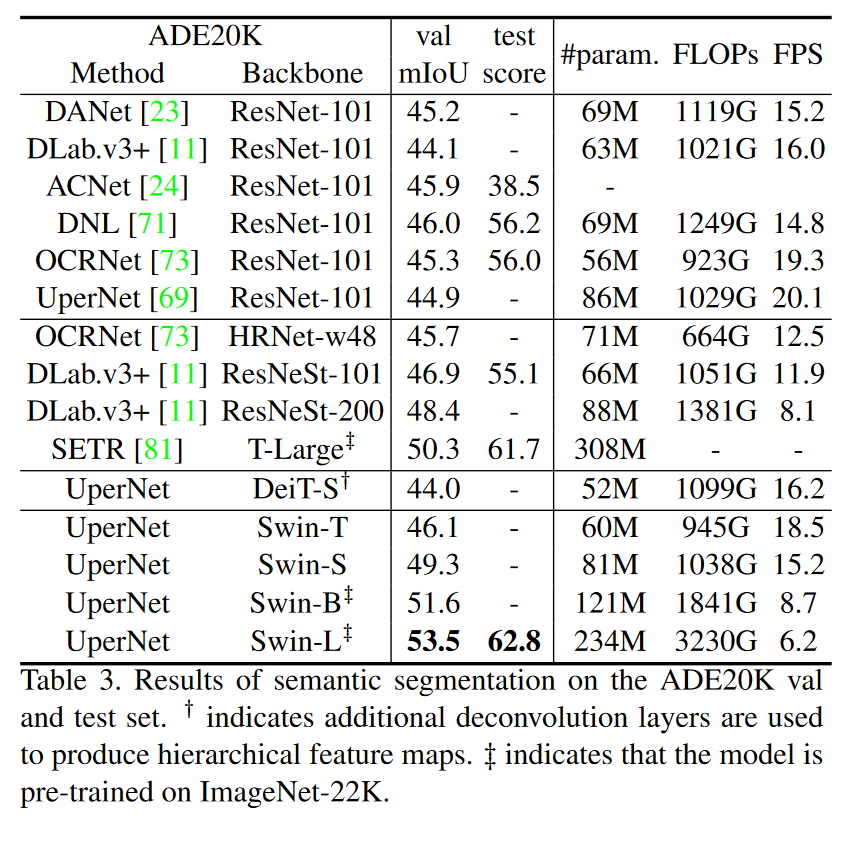
在语义分割上 的表现:
 消融实验:
消融实验: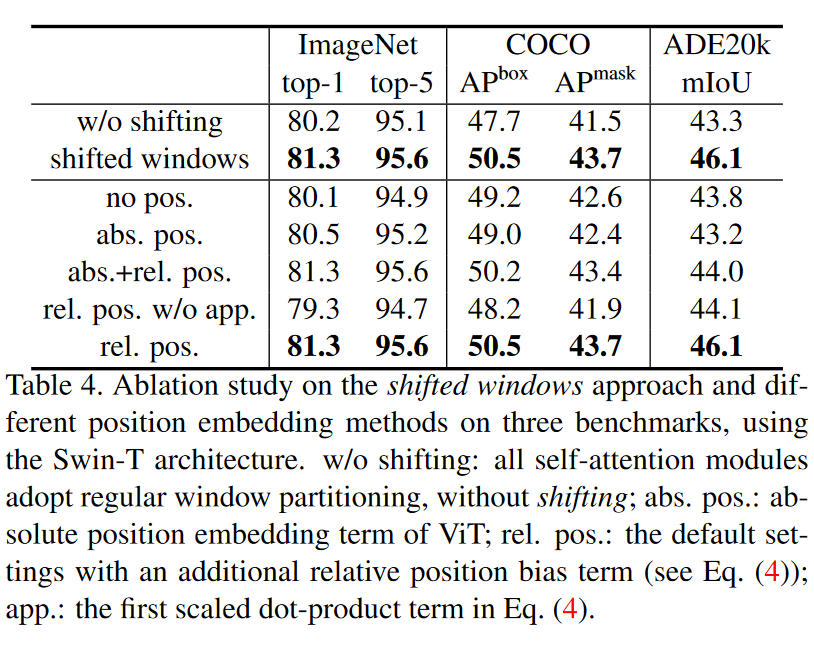
启发
- 通过改变窗口的位置,将局部的注意力扩充到全局;
- 在局部块内使用了相对位置信息。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现