

Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation;OCRNet
Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation
* Authors: [[Yuhui Yuan]], [[Xiaokang Chen]], [[Xilin Chen]], [[Jingdong Wang]]
初读印象
comment:: (OCRnet)聚焦于语义分割中的上下文聚合问题,利用物体类别的表示来个构造单个像素的表示。code:https://git.io/openseg 和 https://git.io/HRNet.OCR.
动机
- 过去的文章:
- 多尺度上下文:pspnet、deeplabv3,没有考虑上下文和具体点的位置。
- 关系型上下文:DANet、CFNet和OCNet只考虑了所有点和具体点的关系,没有考虑一个区域的上下文和具体点的关系。
- 这篇文章:
探究一个点和其上下文(该点周围的点)之间的关系:一个点所属的类别是这个点所属的物体的类别。
方法
Object-contextual representation scheme
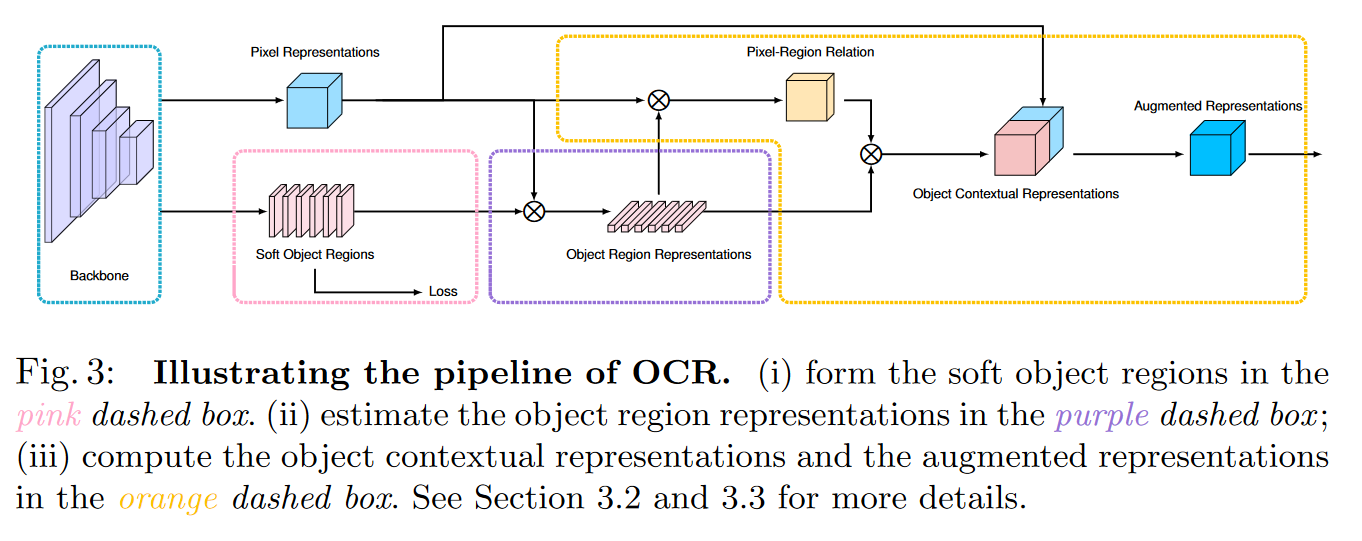
- 根据网络中间层的特征表示估测一个粗略的语义分割结果作为 OCR 方法的一个输入 ,即软物体区域(Soft Object Regions)
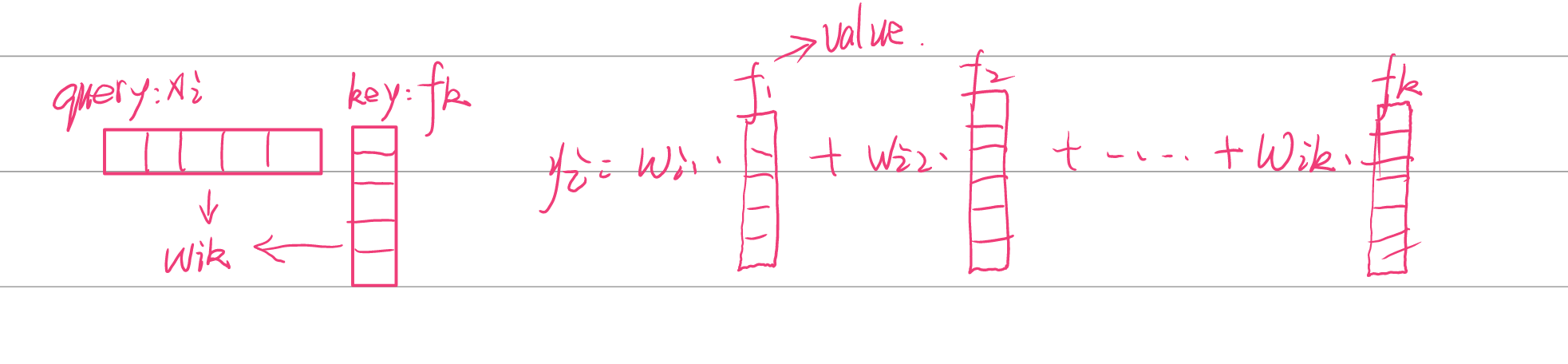
- 根据粗略的语义分割结果和网络最深层的特征表示计算出 K 组向量,即物体区域表示(Object Region Representations),其中每一个向量对应一个语义类别的特征表示\(f_k\)
- 聚合K个对象区域表示并考虑其与所有对象区域的关系来增强每个像素的表示
Objection region representations(对象区域表示)
第k个区域的对象区域表示:
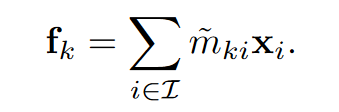 其中\(x_i\)是像素i的表示,前面的是权重(由后面提到的decodercross-attention得到)。
其中\(x_i\)是像素i的表示,前面的是权重(由后面提到的decodercross-attention得到)。
Objection contextual representations (对象上下文表示)
每个像素和每个区域之间的相关性
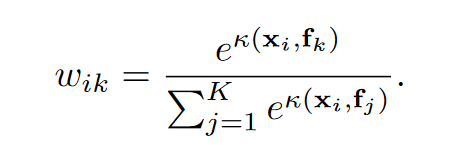
其中
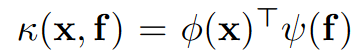 \(\phi(x)\)和\(\psi(f)\)是分别对\(x,f\)做1×1卷积+BN+Relu。
\(\phi(x)\)和\(\psi(f)\)是分别对\(x,f\)做1×1卷积+BN+Relu。
像素i的对象上下文表示\(y_i\):
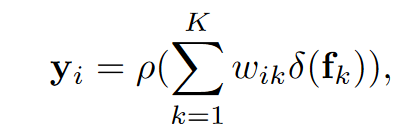
\(\rho,\delta\)是1×1卷积+BN+Relu。
Augmented representations(增强表示)
最终表示
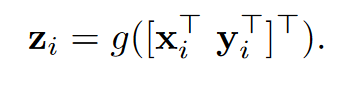 其实就是将\(x_i\)和\(y_i\)拼接起来并做个1×1卷积+BN+Relu#### OCRmodule
其实就是将\(x_i\)和\(y_i\)拼接起来并做个1×1卷积+BN+Relu#### OCRmodule
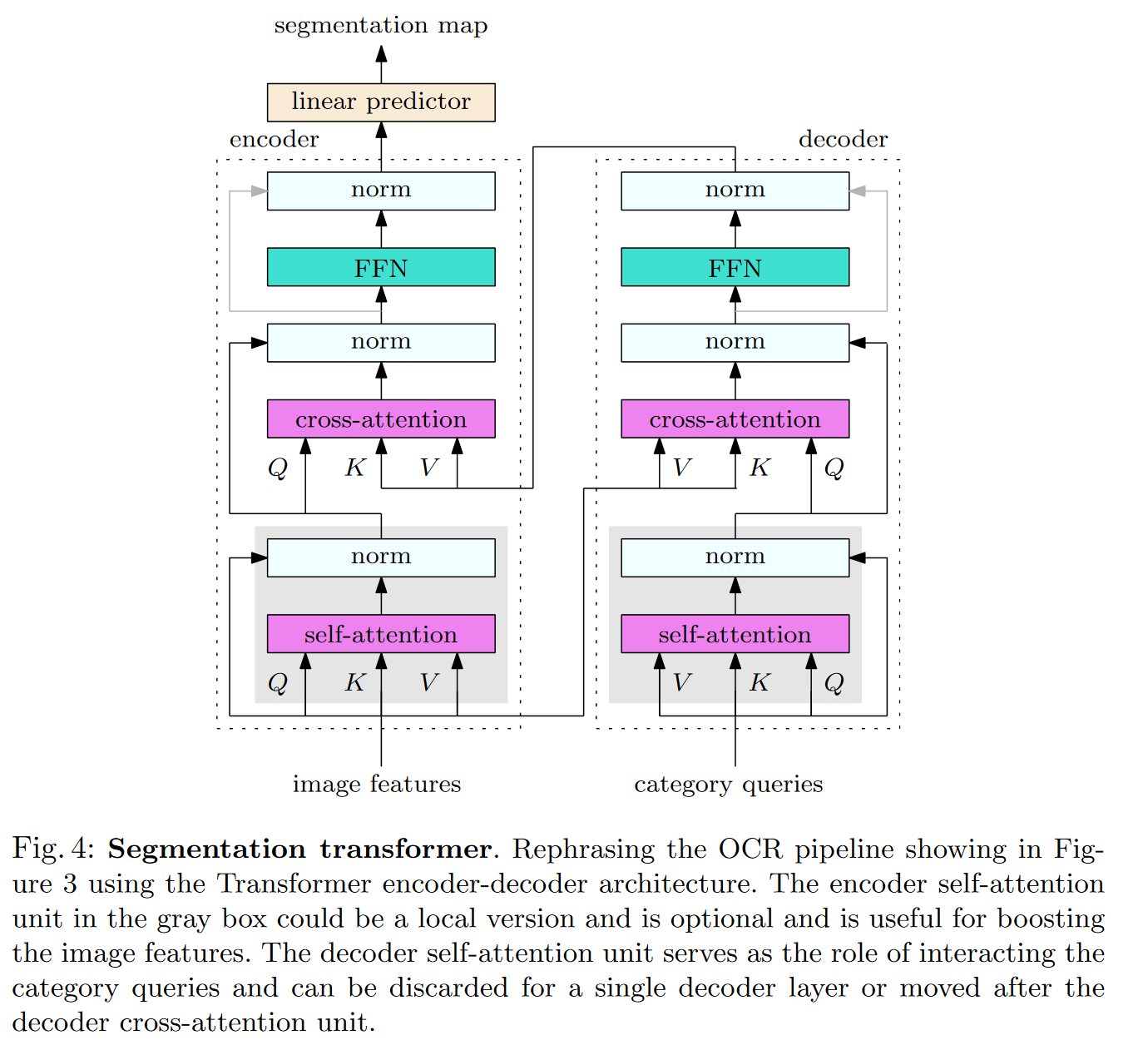
网络中每一个模块代表上述策略的一个子策略。
-
self-attention:普通的注意力模块,加强\(x_i\)和\(f_k\)的特征
-
decoder cross-attention:用于获得Objection region representations(对象区域表示)\(f_k\),其中\(q_k\)代表类别k(将某个阶段输出的粗糙feature map做个粗糙的语义分割。分割得到的结果中每个点就是一个区域,每个向量就是\(q_k\))

-
encoder cross-attention:和后面的FNN一起用于获得Objection contextual representations (对象上下文表示)。
输入输出
输入一张图片,得到其语义分割结果。
局限
只是将下采样后得到的feature map中的每一个点都作为一个区域来进行学习,但是图片中每样物体的大小通常是多变的,有没有可能通过改变区域大小或者在大块区域中随机采样来得到更加丰富的区域表示?
启示
学到了中间结果也可以作为模型的输入。
