
说一说从输入URL到页面呈现发生了什么?
说一说从输入URL到页面呈现发生了什么?(知识点)
这个题可以说是面试最常见也是一道可以无限难的题了,一般面试官出这道题就是为了考察你的前端知识的深度与广度。
1.浏览器接受URL开启网络请求线程(涉及到:浏览器机制,线程与进程等)
2.开启网络线程到发出一个完整的http请求(涉及到:DNS解析,TCP/IP请求,5层网络协议等)
3.从服务器接收到请求到对应后台接受到请求(涉及到:负载均衡,安全拦截,后台内部处理等)
4.后台与前台的http交互(涉及到:http头,响应码,报文结构,cookie等)
5.缓存问题(涉及到:http强缓存与协商缓存等)(请看上一篇文章这些浏览器面试题,看看你能回答几个?)
6.浏览器接受到http数据包后的解析流程(涉及到html词法分析,解析成DOM树,解析CSS生成CSSOM树,合并生成render渲染树。然后layout布局,painting渲染,复合图层合成,GPU绘制,等)
在浏览器地址栏输入URL
当我们在浏览器地址栏输入URL地址后,浏览器会开一个线程来对我们输入的URL进行解析处理。
浏览器中的各个进程及作用:(多进程)
- 浏览器进程:负责管理标签页的创建销毁以及页面的显示,资源下载等。
- 第三方插件进程:负责管理第三方插件。
- GPU进程:负责3D绘制与硬件加速(最多一个)。
- 渲染进程:负责页面文档解析(HTML,CSS,JS),执行与渲染。(可以有多个)
DNS域名解析
为什么需要DNS域名解析?
因为我们在浏览器中输入的URL通常是一个域名,并不会直接去输入IP地址(纯粹因为域名比IP好记),但我们的计算机并不认识域名,它只知道IP,所以就需要这一步操作将域名解析成IP。
URL组成部分
- protocol:协议头,比如http,https,ftp等;
- host:主机域名或者IP地址;
- port:端口号;
- path:目录路径;
- query:查询的参数;
- hash:#后边的hash值,用来定位某一个位置。
解析过程
-
首先会查看浏览器
DNS缓存,有的话直接使用浏览器缓存 -
没有的话就查询计算机本地
DNS缓存(localhost) -
还没有就询问递归式
DNS服务器(就是网络提供商,一般这个服务器都会有自己的缓存) -
如果依然没有缓存,那就需要通过 根域名服务器 和
TLD域名服务器 再到对应的 权威DNS服务器 找记录,并缓存到 递归式服务器,然后 递归服务器 再将记录返回给本地
⚠️注意:
DNS解析是非常耗时的,如果页面中需要解析的域名过多,是非常影响页面性能的。考虑使用dns与加载或减少DNS解析进行优化。
发送HTTP请求
拿到了IP地址后,就可以发起HTTP请求了。HTTP请求的本质就是TCP/IP的请求构建。建立连接时需要3次握手进行验证,断开链接也同样需要4次挥手进行验证,保证传输的可靠性。
3次握手
- 第一次握手:客户端发送位码为 SYN = 1(SYN 标志位置位),随机产生初始序列号 Seq = J 的数据包到服务器。服务器由 SYN = 1(置位)知道,客户端要求建立联机。
- 第二次握手:服务器收到请求后要确认联机信息,向客户端发送确认号Ack = (客户端的Seq +1,J+1),SYN = 1,ACK = 1(SYN,ACK 标志位置位),随机产生的序列号 Seq = K 的数据包。
- 第三次握手:客户端收到后检查 Ack 是否正确,即第一次发送的 Seq +1(J+1),以及位码ACK是否为1。若正确,客户端会再发送 Ack = (服务器端的Seq+1,K+1),ACK = 1,以及序号Seq为服务器确认号J 的确认包。服务器收到后确认之前发送的 Seq(K+1) 值与 ACK= 1 (ACK置位)则连接建立成功。
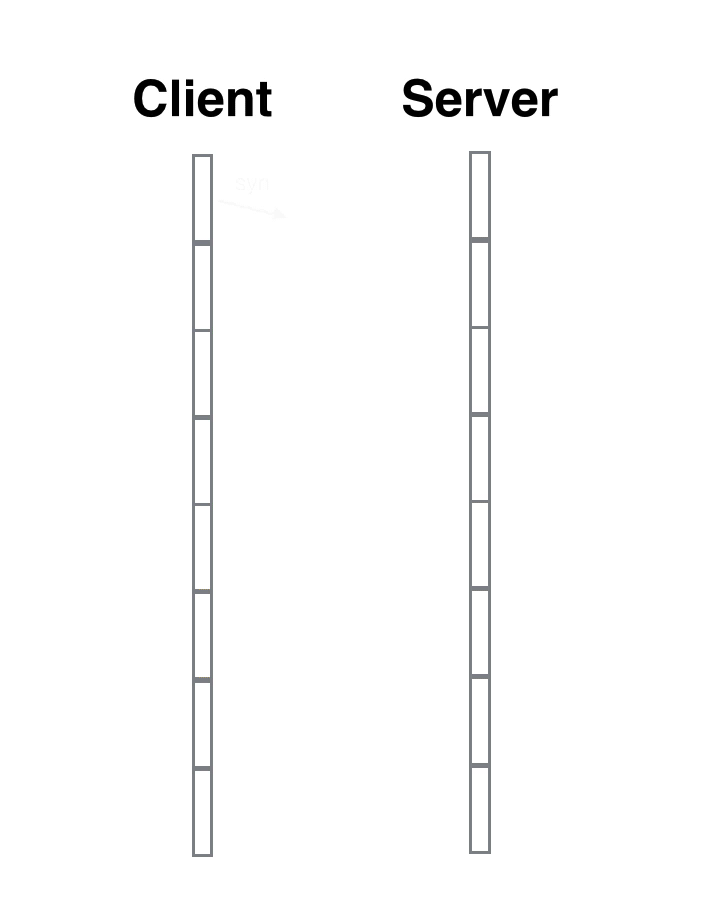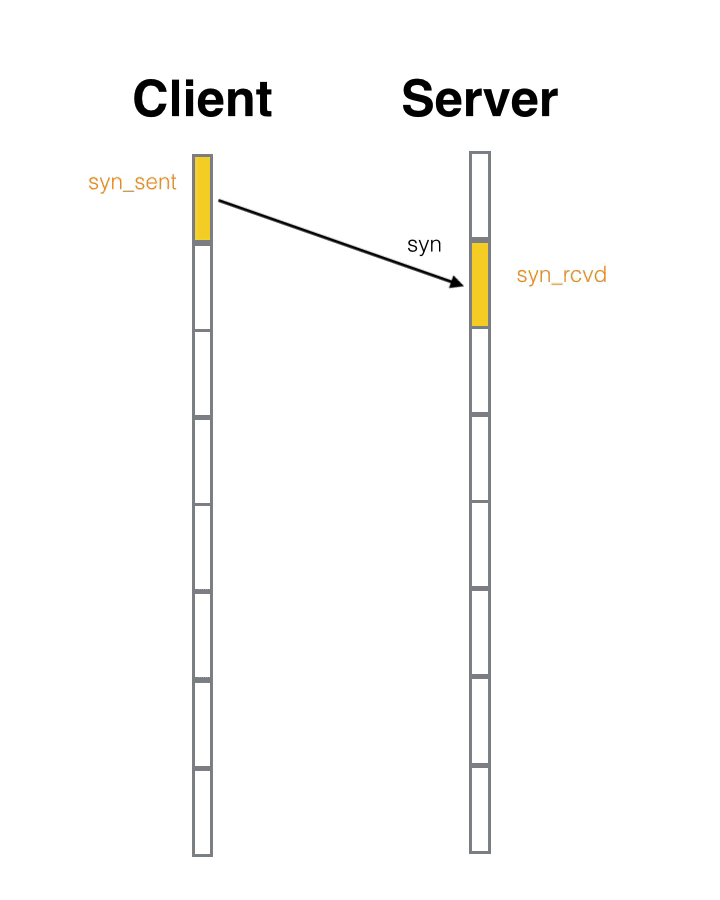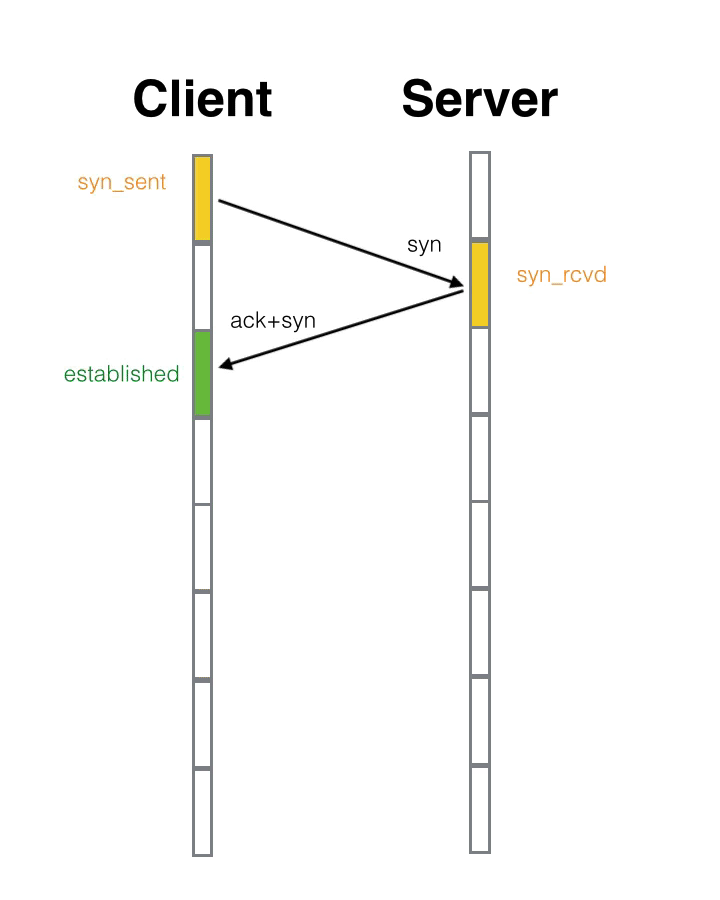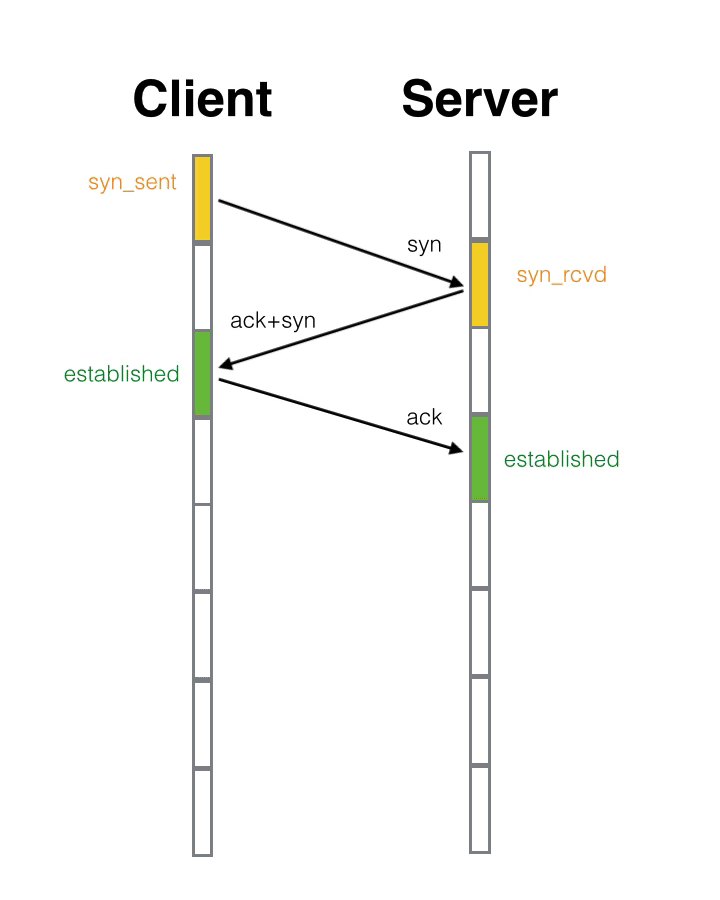
直白理解:
(客户端:hello,你是server么?服务端:hello,我是server,你是client么 客户端:yes,我是client 建立成功之后,接下来就是正式传输数据。)
4次挥手
- 客户端发送一个FIN Seq = M(FIN置位,序号为M)包,用来关闭客户端到服务器端的数据传送。
- 服务器端收到这个FIN,它发回一个ACK,确认序号Ack 为收到的序号M+1。
- 服务器端关闭与客户端的连接,发送一个FIN Seq = N 给客户端。
- 客户端发回ACK 报文确认,确认序号Ack 为收到的序号N+1。
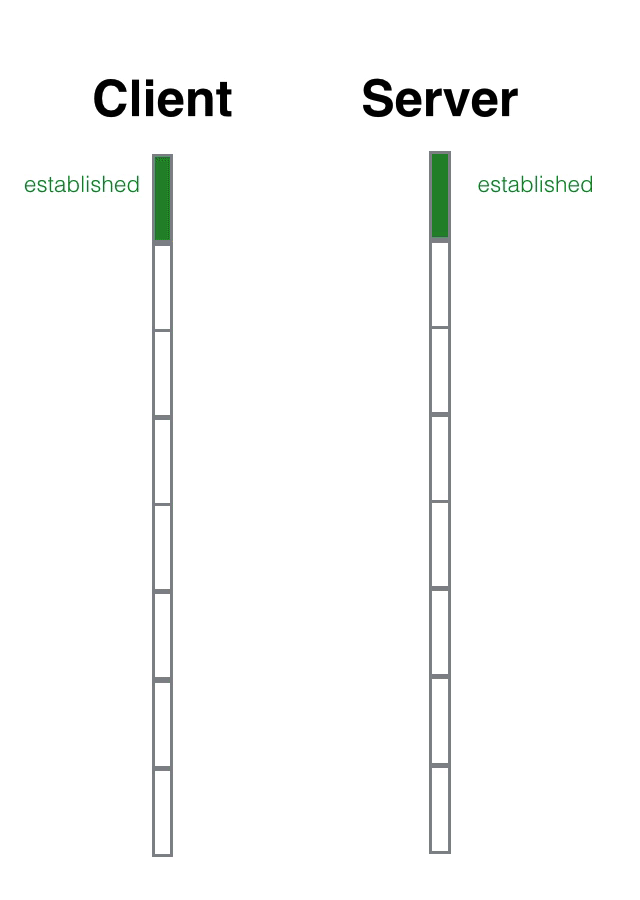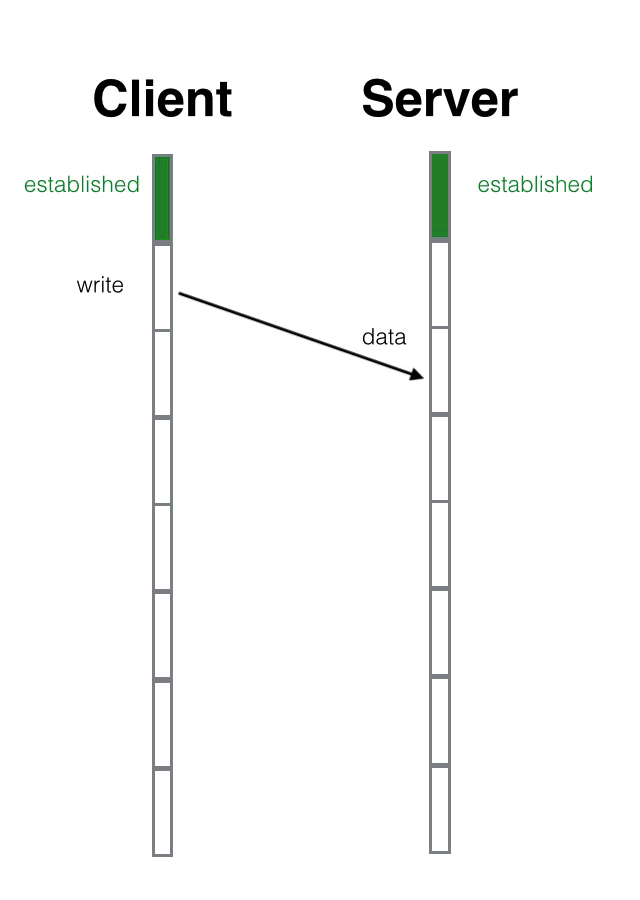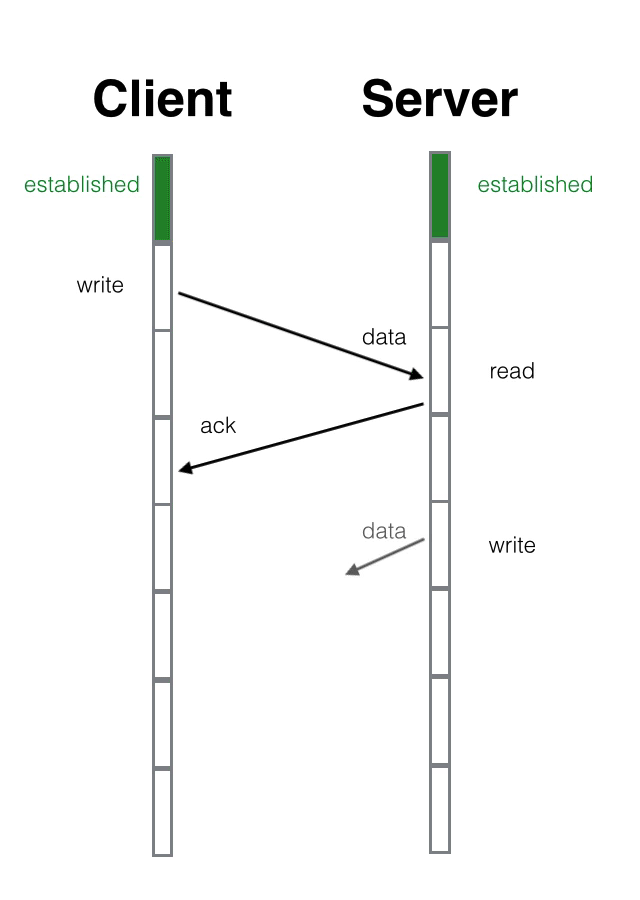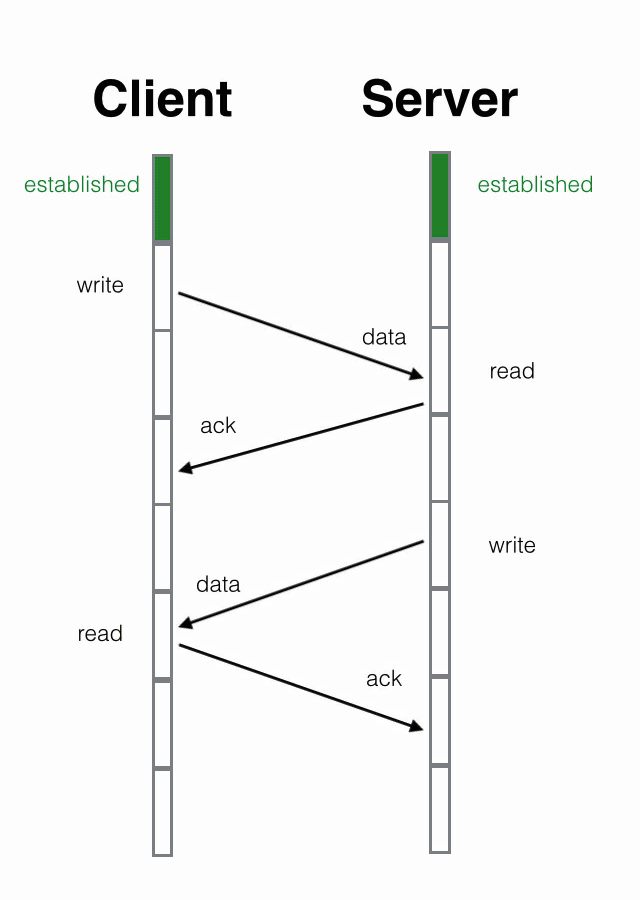
直白理解:
(主动方:我已经关闭了向你那边的主动通道了,只能被动接收了 被动方:收到通道关闭的信息 被动方:那我也告诉你,我这边向你的主动通道也关闭了 主动方:最后收到数据,之后双方无法通信)
五层网络协议
1、应用层(DNS,HTTP):DNS解析成IP并发送http请求;
2、传输层(TCP,UDP):建立TCP连接(3次握手);
3、网络层(IP,ARP):IP寻址;
4、数据链路层(PPP):封装成帧;
5、物理层(利用物理介质传输比特流):物理传输(通过双绞线,电磁波等各种介质)。
OSI七层框架:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层
服务器接收请求做出响应
HTTP 请求到达服务器,服务器进行对应的处理。 最后要把数据传给浏览器,也就是返回网络响应。
跟请求部分类似,网络响应具有三个部分:响应行、响应头和响应体。
响应完成之后怎么办?TCP 连接就断开了吗?
不一定。这时候要判断Connection字段, 如果请求头或响应头中包含Connection: Keep-Alive,
表示建立了持久连接,这样TCP连接会一直保持,之后请求统一站点的资源会复用这个连接。否则断开TCP连接, 请求-响应流程结束。
状态码
状态码是由3位数组成,第一个数字定义了响应的类别,且有五种可能取值:
- 1xx:指示信息–表示请求已接收,继续处理。
- 2xx:成功–表示请求已被成功接收、理解、接受。
- 3xx:重定向–要完成请求必须进行更进一步的操作。
- 4xx:客户端错误–请求有语法错误或请求无法实现。
- 5xx:服务器端错误–服务器未能实现合法的请求。
平时遇到比较常见的状态码有:200, 204, 301, 302, 304, 400, 401, 403, 404, 422, 500(分别表示什么请自行查找)。
服务器返回相应文件
请求成功后,服务器会返回相应的网页,浏览器接收到响应成功的报文后便开始下载网页,至此,网络通信结束。
浏览器解析渲染页面
浏览器在接收到HTML,CSS,JS文件之后,它是如何将页面渲染在屏幕上的?
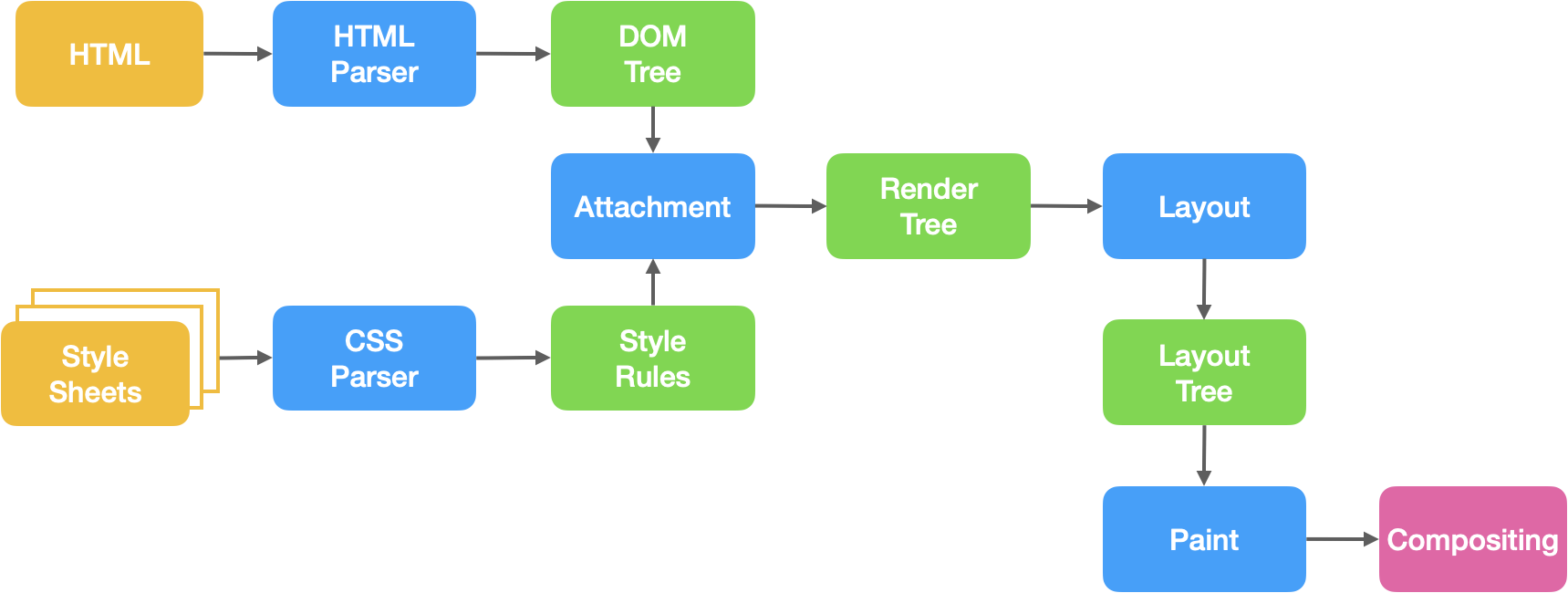
解析HTML构建DOM Tree
浏览器在拿到服务器返回的网页之后,首先会根据顶部定义的DTD类型进行对应的解析,解析过程将被交给内部的GUI渲染线程来处理。
DTD(Document Type Definition)文档类型定义
常见的文档类型定义
//HTML5文档定义
<!DOCTYPE html>
//用于XHTML 4.0 的严格型
<!DOCTYPE HTMLPUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
//用于XHTML 4.0 的过渡型
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
//用于XHTML 1.0 的严格型
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
//用于XHTML 1.0 的过渡型
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
HTML解释器的工作就是将网络或者本地磁盘获取的HTML网页或资源从字节流解释成DOM树🌲结构

通过上图可以清楚的了解这一过程:首先是字节流,经过解码之后是字符流,然后通过词法分析器会被解释成词语(Tokens),之后经过语法分析器构建成节点,最后这些节点被组建成一颗 DOM 树。
对于线程化的解释器,字符流后的整个解释、布局和渲染过程基本会交给一个单独的渲染线程来管理(不是绝对的)。由于 DOM 树只能在渲染线程上创建和访问,所以构建 DOM 树的过程只能在渲染线程中进行。但是,从字符串到词语这个阶段可以交给单独的线程来做,Chrome 浏览器使用的就是这个思想。在解释成词语之后,Webkit 会分批次将结果词语传递回渲染线程。
这个过程中,如果遇到的节点是 JS 代码,就会调用 JS引擎 对 JS代码进行解释执行,此时由于 JS引擎 和 GUI渲染线程 的互斥,GUI渲染线程 就会被挂起,渲染过程停止,如果 JS 代码的运行中对DOM树进行了修改,那么DOM的构建需要从新开始
如果节点需要依赖其他资源,图片/CSS等等,就会调用网络模块的资源加载器来加载它们,它们是异步的,不会阻塞当前DOM树的构建
如果遇到的是 JS 资源URL(没有标记异步),则需要停止当前DOM的构建,直到 JS 的资源加载并被 JS引擎 执行后才继续构建DOM
解析CSS构建CSSOM Tree
CSS解释器会将CSS文件解释成内部表示结构,生成CSS规则树,这个过程也是和DOM解析类似的,CSS 字节转换成字符,接着词法解析与法解析,最后构成 CSS对象模型(CSSOM) 的树结构
构建渲染树(Render Tree)
等DOM Tree与CSSOM Tree都构建完毕后,接着将它们合并成渲染树(Render Tree),渲染树 只包含渲染网页所需的节点,然后用于计算每个可见元素的布局,并输出给绘制流程,将像素渲染到屏幕上。
渲染(布局,绘制,合成)
- 计算CSS样式 ;
- 构建渲染树 ;
- 布局,主要定位坐标和大小,是否换行,各种
position overflow z-index属性 ; - 绘制,将图像绘制出来。
这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
这里Reflow和Repaint的概念是有区别的:
(1)Reflow:即回流。一般意味着元素的内容、结构、位置或尺寸发生了变化,需要重新计算样式和渲染树。
(2)Repaint:即重绘。意味着元素发生的改变只是影响了元素的一些外观之类的时候(例如,背景色,边框颜色,文字颜色等),此时只需要应用新样式绘制这个元素就可以了。
回流的成本开销要高于重绘,而且一个节点的回流往往回导致子节点以及同级节点的回流, 所以优化方案中一般都包括,尽量避免回流。
回流一定导致重绘,但重绘不一定会导致回流
合成(composite)
最后一步合成( composite ),这一步骤浏览器会将各层信息发送给GPU,GPU将各层合成,显示在屏幕上
普通图层和复合图层
可以简单的这样理解,浏览器渲染的图层一般包含两大类:普通图层以及复合图层
首先,普通文档流内可以理解为一个复合图层(这里称为默认复合层,里面不管添加多少元素,其实都是在同一个复合图层中)
其次,absolute布局(fixed也一样),虽然可以脱离普通文档流,但它仍然属于默认复合层。
然后,可以通过硬件加速的方式,声明一个新的复合图层,它会单独分配资源
(当然也会脱离普通文档流,这样一来,不管这个复合图层中怎么变化,也不会影响默认复合层里的回流重绘)
可以简单理解下:GPU中,各个复合图层是单独绘制的,所以互不影响,这也是为什么某些场景硬件加速效果一级棒
可以Chrome源码调试 -> More Tools -> Rendering -> Layer borders中看到,黄色的就是复合图层信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号