
python接口自动化(十一)--发送post【data】(详解)
简介
前面登录博客园的是传 json 参数,由于其登录机制的改变没办法演示,然而在工作中有些登录不是传 json 的,如 jenkins 的登录,这里小编就以jenkins 登录为案例,传 data 参数,给各位童鞋详细演练一下。
一、登录jenkins抓包
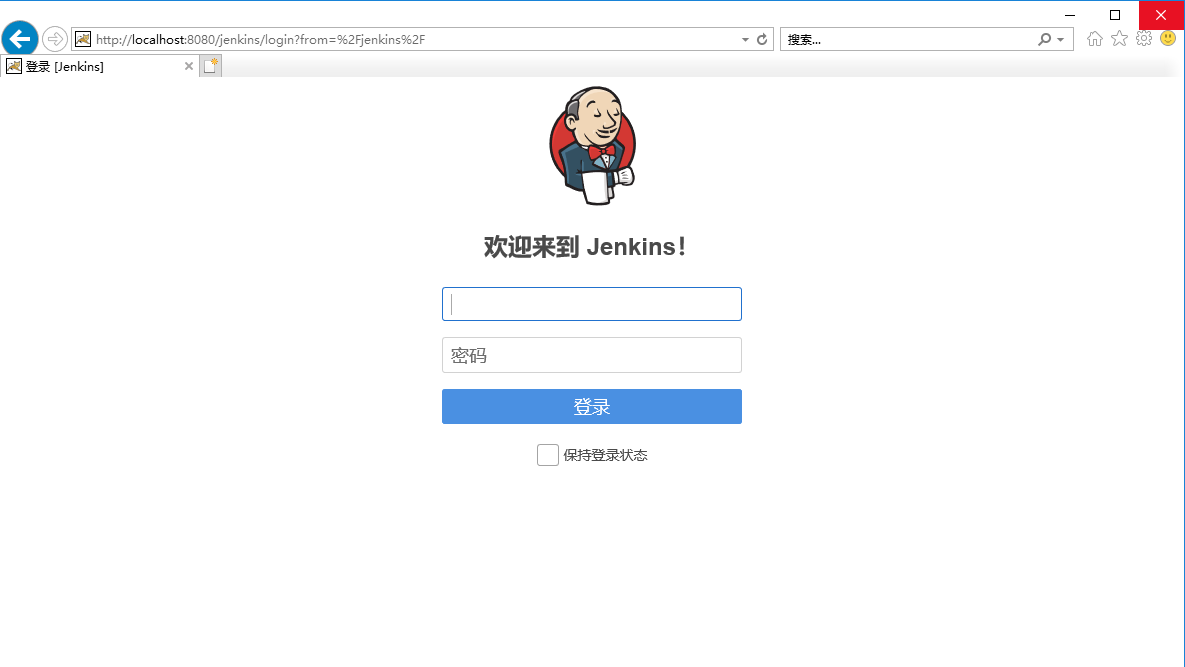
1、浏览器上登录jenkins,输入账号和密码,点击登录
2、fiddler抓包工具抓取jenkins登录的过程
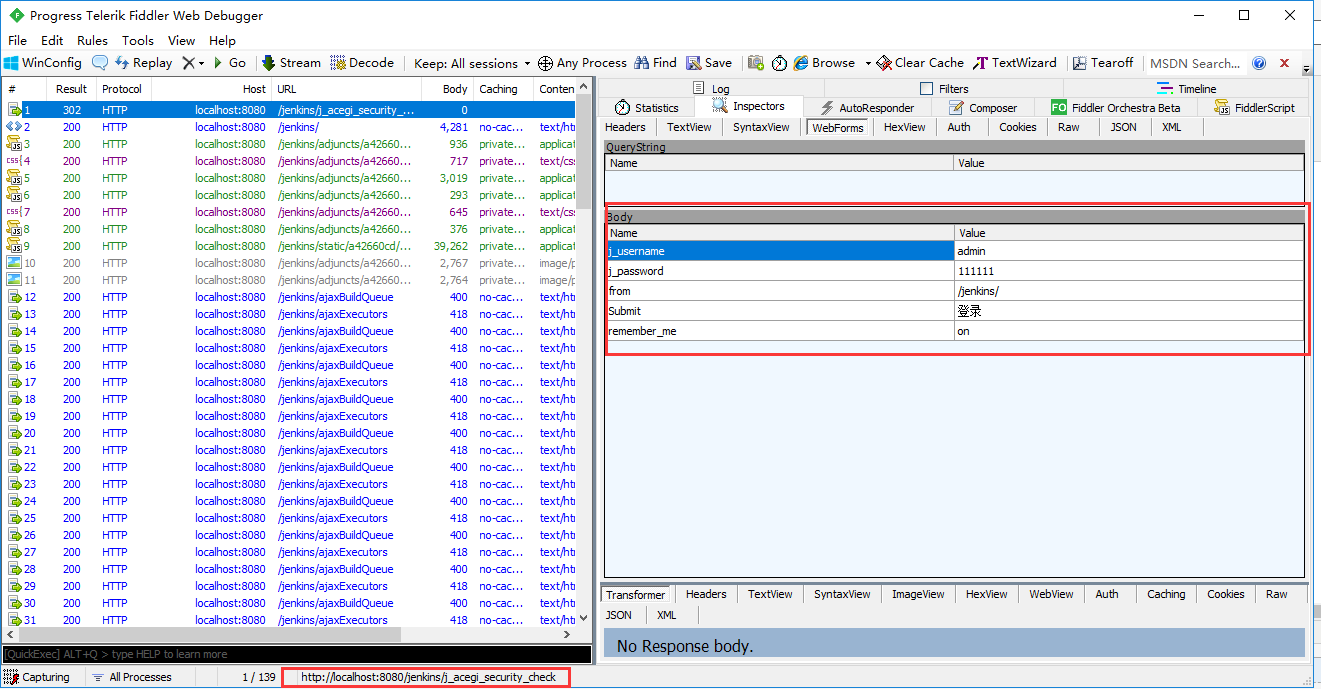
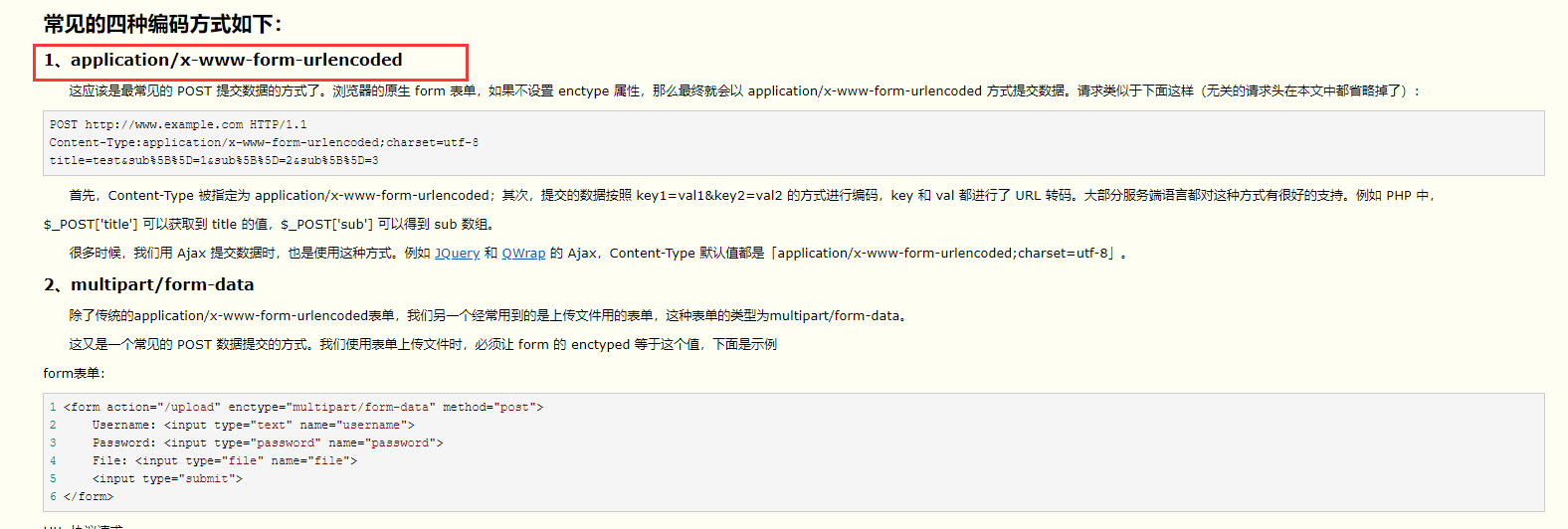
3、可以清楚地看到这个body参数并不是json格式,是key=value格式,也就是前面介绍post请求四种数据类型里面的第一种
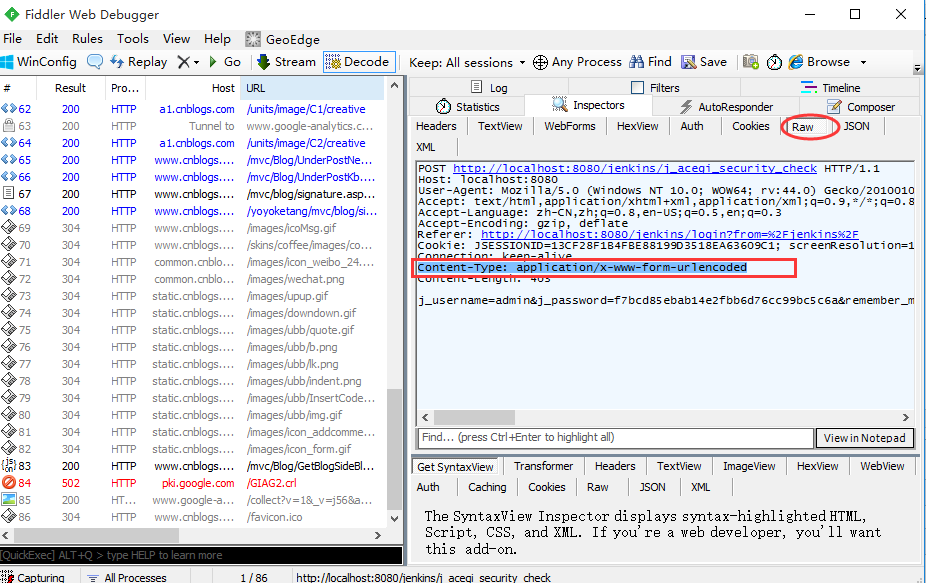
二、请求头部
1.上面抓包已经知道body的数据类型了,那么头部里面Content-Type类型也需要填写对应的参数类型
三、实现登录
1、登录实例代码如下:
注意:此处的登录URL是fiddler抓包抓到的,而并非是浏览器的URL地址,如果你复制的是浏览器的地址,就会报错了

1 # coding:utf-8
2 import requests
3 # 先打开登录首页,获取部分session
4 url = "http://localhost:8080/jenkins/j_acegi_security_check"
5 headers = {
6 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
7 } # get方法其它加个ser-Agent就可以了
8 d = {"j_username": "admin",
9 "j_password": "111111",
10 "from": "",
11 "Submit": u"登录",
12 "remember_me": "on"
13 }
14 s = requests.session()
15 r = s.post(url, headers=headers, data=d)
16 print (r.content.decode('utf-8')
)
2、运行后的结果如下:
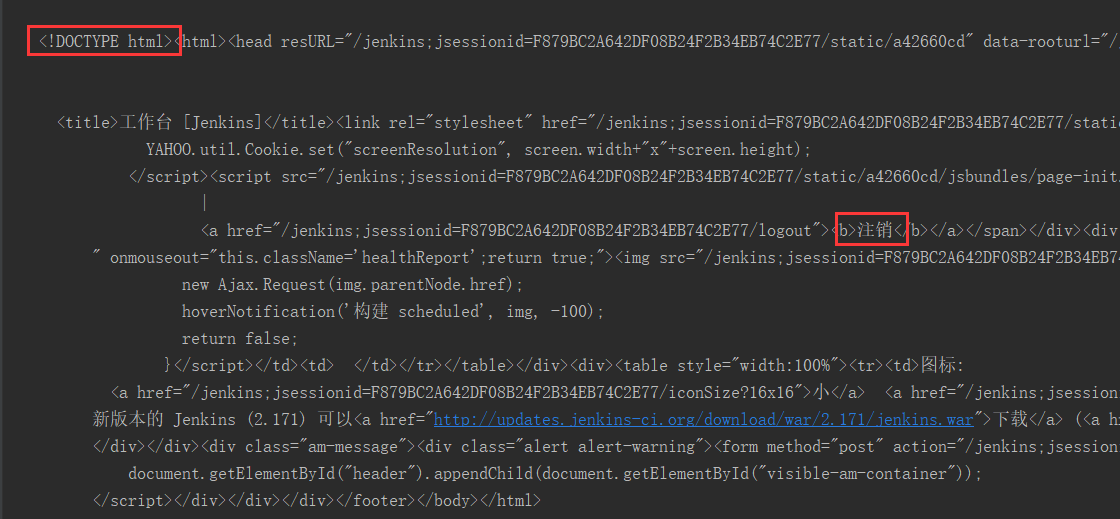
3、为了更好地查看你可以将其拷贝到记事本,保存,然后将文件后缀名修改成.html或者.htm,用浏览器打开查看

四、判断登录是否成功
1.首先这个登录接口有重定向,看左边会话框302,那登录成功的结果看最后一个200就行
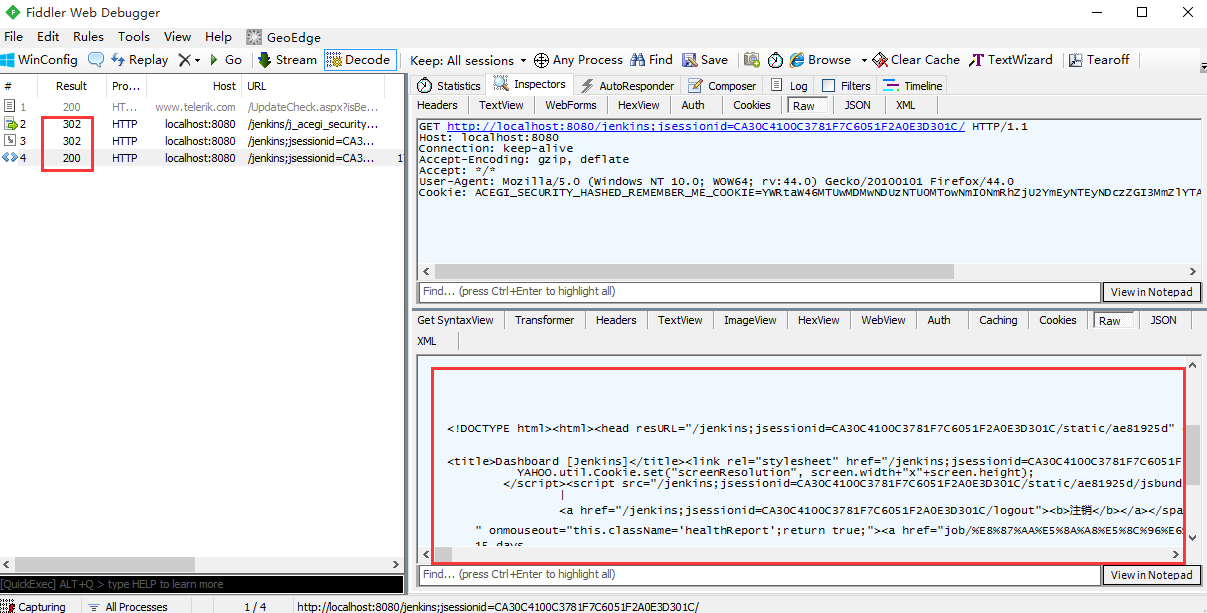
2.返回的结果并不是跟博客园一样的json格式,返回的是一个html页面
五、判断登录成功
1.判断登录成功,可以抓取页面上的关键元素,比如:账号名称admin,注销按钮
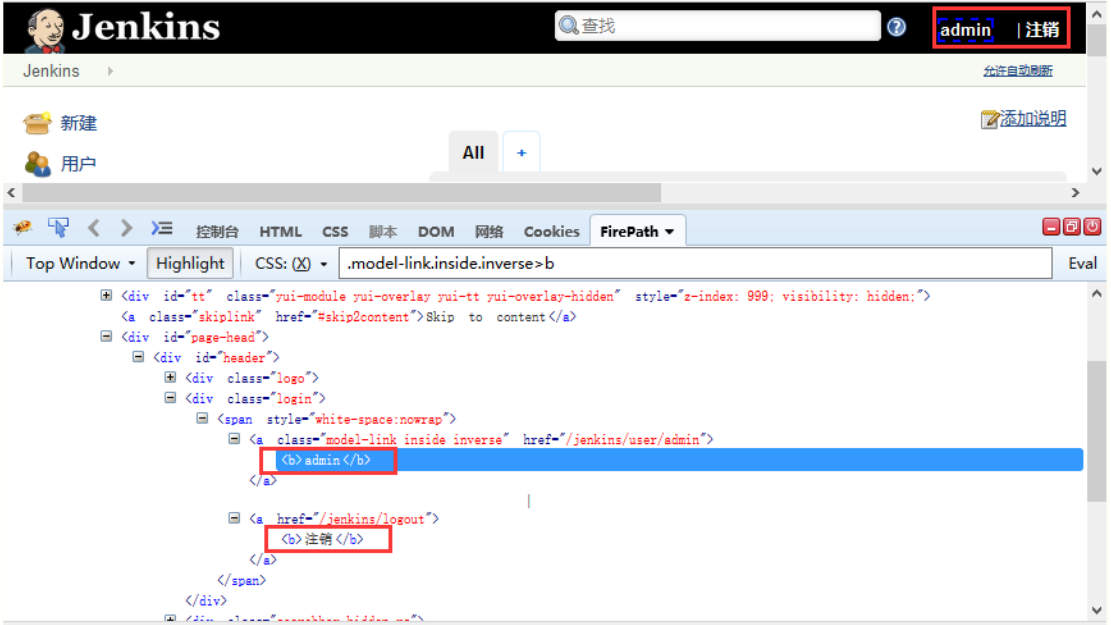
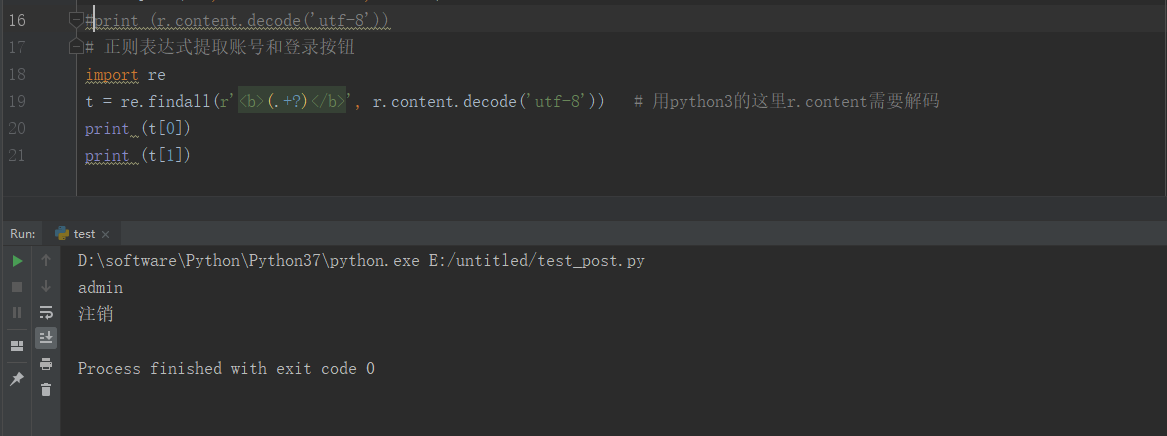
2.通过正则表达式提出这2个关键字
六、参考代码
1 # coding:utf-8
2 import requests
3 # 先打开登录首页,获取部分session
4 url = "http://localhost:8080/jenkins/j_acegi_security_check"
5 headers = {
6 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
7 } # get方法其它加个ser-Agent就可以了
8 d = {"j_username": "admin",
9 "j_password": "111111",
10 "from": "",
11 "Submit": u"登录",
12 "remember_me": "on"
13 }
14 s = requests.session()
15 r = s.post(url, headers=headers, data=d)
16 #print (r.content.decode('utf-8'))
17 # 正则表达式提取账号和登录按钮
18 import re
19 t = re.findall(r'<b>(.+?)</b>', r.content.decode('utf-8')) # 用python3的这里r.content需要解码
20 print (t[0])
21 print (t[1])
七、遇到问题可解决方法
注意这里边遇到的问题python3遇到的问题,或许python2没有这些问题,笔者没有实践,有兴趣的自己可以试一下
1、如果打印content,没有加后边的.decode('utf-8'),会出现乱码,解决方法加上即可。
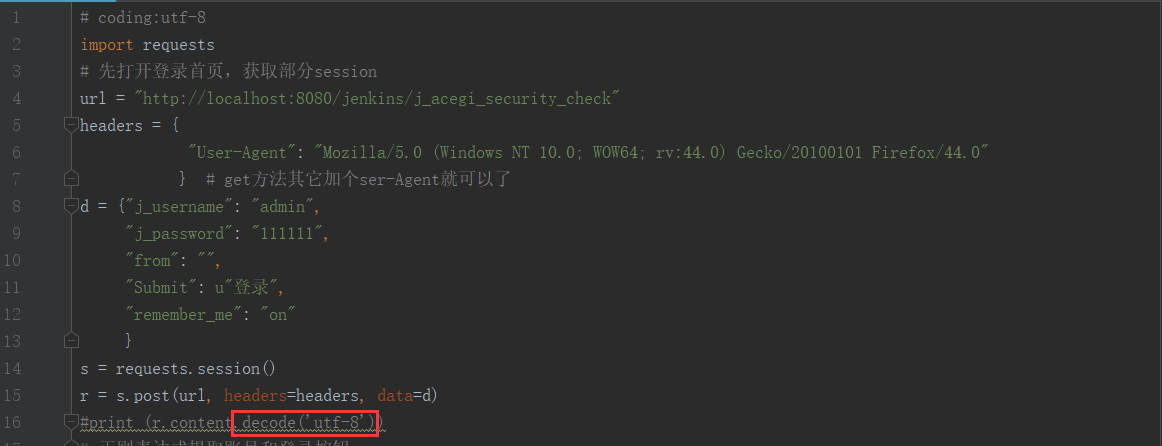
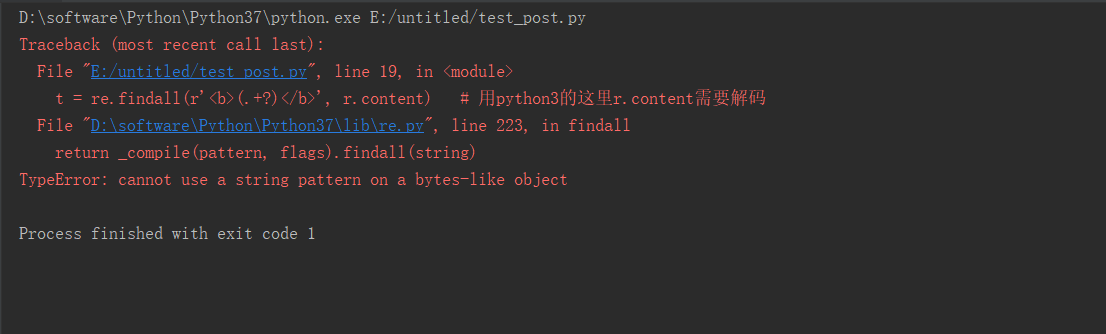
2、如果正则提取没有加.decode('utf-8'),会报如下错误,解决方案也是加上即可
八、小结
jenkins 代码模拟登陆到这里就结束,实际工作中的登录接口也就是这些,记住万变不离其宗,举一反三。
作者:北京-宏哥
更多技术请关注微信公众号:程序员技术前沿

 浙公网安备 33010602011771号
浙公网安备 33010602011771号