HBase架构的优缺点
HBase是目前非常热门的一款分布式KV键值数据库系统,无论是互联网行业还是其他传统 IT 行业都在大量使用。HBase具有高可用、易扩展的特性,目前社区成熟度高,HBase可以作为底层数据存储服务,例如 Kylin、OpenTSDB 等。
一、HBase架构
HBase基于Hadoop。HBase可以不将数据存于HDFS中,而存于本地文件系统,但是这种方式一般仅用于测试,生产环境中都基于 HDFS。HBase 也是一主多从的主从架构。主组件叫作 HMaster,从组件叫作HRegionServer。我们知道,所有主从架构的分布式系统都要想方设法减少主节点的负载,因为主节点只有一个。HBase 在这方面做得比较好,它甚至做到了在客户端读写一个表的数据时可以完全不与HMaster通信。HBase对HMaster和HRegionServer的分工非常科学,HMaster不参与表的管理,不参与客户端对表的访问,其主要工作是故障恢复和负载平衡。故障恢复是指 HRegionServer 的故障恢复,HMaster 监视 HRegionServer 的状态,一旦某个 HRegionServer出问题,就将这个HRegionServer的工作转移给其他 HRegionServer。负载平衡指的是HMaster定期检查各HRegionServer 的数据负载状况,将数据从负载过重的节点移到较轻的节点。
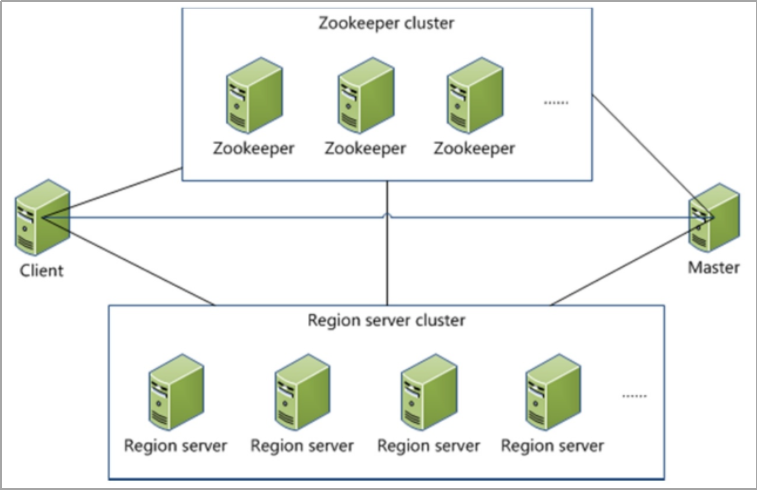
HBase还有一个必需的组件∶ZooKeeper。ZooKeeper的作用是高可用,解决HMaster的单点故障。HMaster可以有多个,但只有一个起作用,其余作为备份,选举时要ZooKeeper帮忙。除此之外,ZooKeeper还是寻找表的路由入口,因为表存在不同的HRegionServer节点,必须有数据记录表数据与节点间的对应关系,要查找这个关系,得从ZooKeeper入手。所以客户端要使用HBase服务,给它的连接地址不是HMaster,而是ZooKeeper的各节点地址。HMaster监控 HRegionServer也是通过ZooKeeper, HRegionServer在ZooKeeper 中建立自己的数据节点,HMaster只需监视这些数据节点即可。
二、HBase的优点
与其他数据库相比,HBase在系统设计以及实际实践中有很多独特的优点。
●容量巨大:HBase的单表可以支持千亿行、百万列的数据规模,数据容量可以达到TB甚至PB级别。传统的关系型数据库,如 Oracle和MySQL等,如果单表记录条数超过亿行,读写性能都会急剧下降,在HBase中并不会出现这样的问题。
●良好的可扩展性:HBase集群可以非常方便地实现集群容量扩展,主要包括数据存储节点扩展以及读写服务节点扩展。HBase 底层数据存储依赖于HDFS系统,HDFS可以通过简单地增加DataNode实现扩展,HBase读写服务节点也一样,可以通过简单的增加RegionServer节点实现计算层的扩展。
●稀疏性:HBase支持大量稀疏存储,即允许大量列值为空,并不占用任何存储空间。这与传统数据库不同,传统数据库对于空值的处理要占用一定的存储空间,这会造成一定程度的存储空间浪费。因此可以使用HBase存储多至上百万列的数据,即使表中存在大量的空值,也不需要任何额外空间。
●高性能:HBase目前主要擅长于LTP场景,数据写操作性能强劲,对于随机单点读以及小范围的扫描读,其性能也能够得到保证。对于大范围的扫描读可以使用MapReduce提供的API,以便实现更高效的并行扫描。
●多版本:HBase支持多版本特性,即一个 KV 可以同时保留多个版本,用户可以根据需要选择最新版本或者某个历史版本。
●支持过期:HBase支持TTL过期特性,用户只需要设置过期时间,超过TTL的数据就会被自动清理,不需要用户写程序手动删除。
●Hadoop原生支持∶HBase是Hadoop生态中的核心成员之一,很多生态组件都可以与其直接对接。HBase数据存储依赖于HDFS,这样的架构可以带来很多好处,比如用户可以直接绕过HBase系统操作HDFS文件,高效地完成数据扫描或者数据导入工作;再比如可以利用 HDFS 提供的多级存储特性(Archival Storage Feature),根据业务的重要程度将HBase进行分级存储,重要的业务放到SSD,不重要的业务放到HDD。或者用户可以设置归档时间,进而将最近的数据放在 SSD,将归档数据文件放在 HDD。
三、HBase的缺点
任何一个系统都不会完美,HBase也一样。HBase不能适用于所有应用场景,例如:
●HBase本身不支持很复杂的聚合运算(如 Join、GroupBy 等)。如果业务中需要使用聚合运算,可以在HBase之上架设Phoenix组件或者Spark 组件,前者主要应用于小规模聚合的 OLTP 场景,后者应用于大规模聚合的 0LAP 场景。
●HBase本身并没有实现二级索引功能,所以不支持二级索引查找。好在针对 HBase 实现的第三方二级索引方案非常丰富,比如目前比较普遍的使用 Phoenix 提供的二级索引功能。
●HBase原生不支持全局跨行事务,只支持单行事务模型。同样,可以使用Phoenix提供的全局事务模型组件来弥补HBase的这个缺陷。
可以看到,HBase系统本身虽然不擅长某些工作领域,但是借助于Hadoop强大的生态圈,用户只需要在其上架设Phoenix 组件、Spark 组件或者其他第三方组件,就可以有效地协同工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号