aiohttp异步爬虫案例
写在开头:由于需要爬取网上的一些数据,并且需要请求很多个URL,但requests库是一个同步库,因此采用aiohttp实现异步爬取数据
需求
爬取数据并得到想要的结果,并将结果输出为excel文档
基本情况
通过浏览器开发者模式查看可以了解到网站是通过API得到json数据包从而渲染到网页,因此不需要使用lxml等解析网页的Python包,只需要通过网页请求得到对应的json数据包即可。
首先我得到了一个汇总的json(SOC.json),这个json记录了每个子节点所对应的ID。
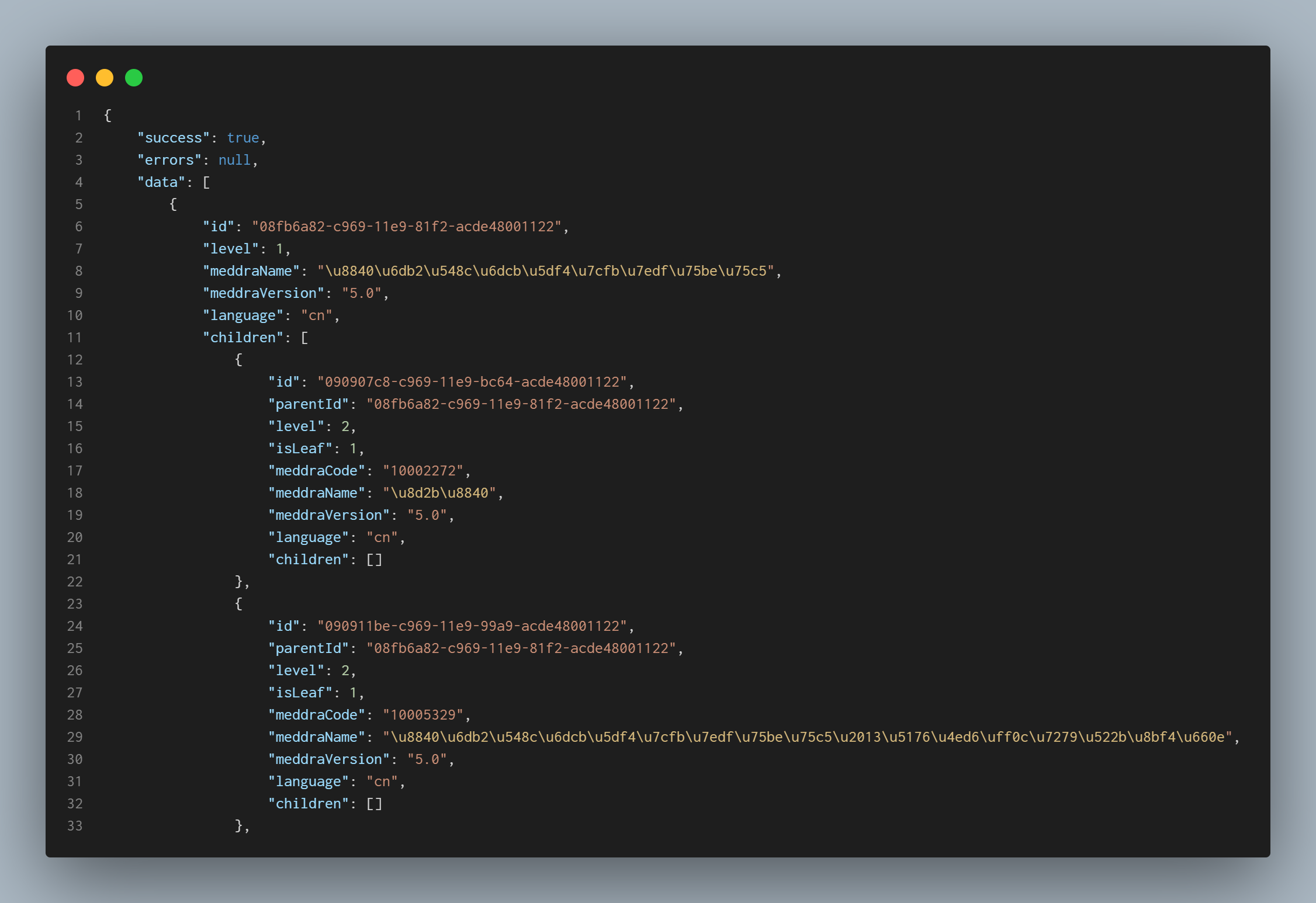
而获取子节点的json所需要的URL正好需要子节点ID作为参数拼接,子节点json如图所示。
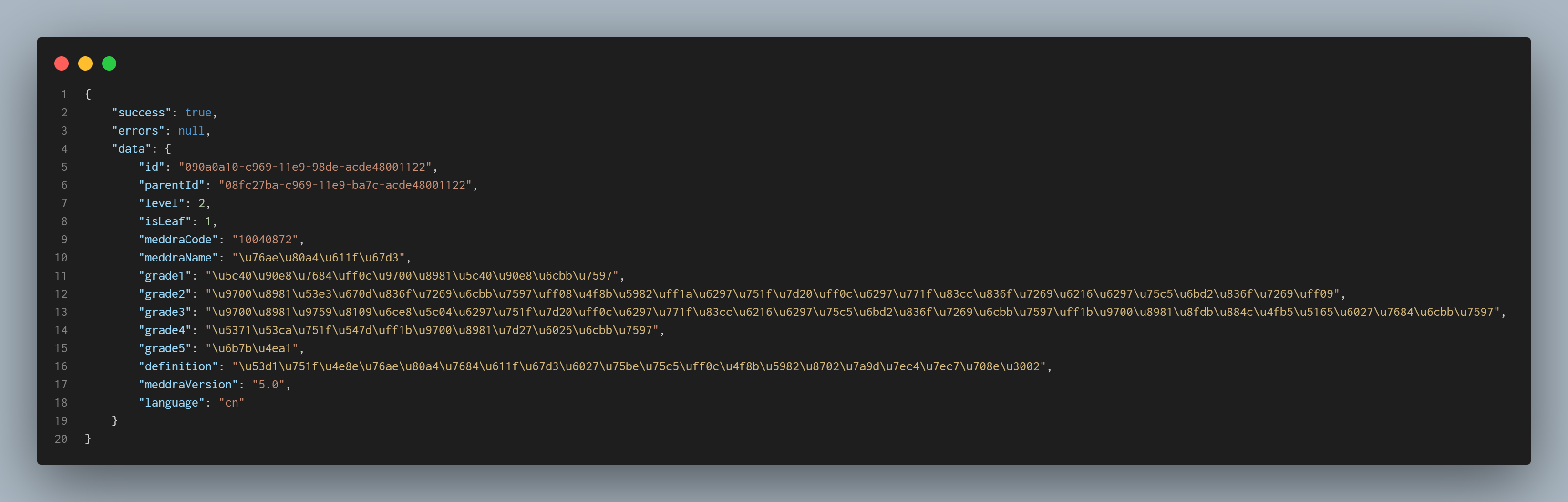
子节点json记录了我所需要的所有信息,因此获取所有的子节点json即可。
编程思路
-
直接请求URL以获得
SOC.json文件 -
读取
SOC.json文件获取所有的子节点ID -
由得到子节点ID拼接为URL,请求得到的URL获取子节点json
-
读取所有json文件并输出到EXCEL文件
相关代码
获取json的代码如下,相关网址已省略。
spider.py
import json,requests,aiohttp,asyncio,os,random
SOC_URL = "https://SOC_URL"
TERM_URL = "https://TERM_URL/"
class Spider(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29'
}
loop = asyncio.get_event_loop()
# 设定异步延迟(s),防止请求过快获取不到数据
delay = {
'min': 2,
'max': 6
}
def __init__(self) -> None:
pass
async def async_requests(self,url):
"""
异步请求函数
"""
async with aiohttp.ClientSession(headers=self.headers) as session:
async with session.get(url=url, headers=self.headers) as response:
if response.status == 200:
print(response)
asyncio.sleep(random.uniform(self.delay['min'],self.delay['max'])*1000)
term_json = await response.json()
term_id = term_json['data']['id']
print(term_id)
# 保存json文件
with open('assets/{}.json'.format(term_id),'w+') as f:
f.write(json.dumps(term_json))
def getTerm(self):
with open('assets/soc.json','r') as f:
self.SOC_json = json.load(f)
n = 0
task = None
for SOC in self.SOC_json["data"]:
for Term in SOC['children']:
url = TERM_URL + Term['id']
n=n+1
print('第{}个正在进行...'.format(n))
if "{}.json".format(Term['id']) not in os.listdir('assets'):
task = asyncio.gather(self.async_requests(url))
if task:
self.loop.run_until_complete(task)
self.loop.close()
def getSOC(self):
response:requests.Response = requests.get(SOC_URL,headers=self.headers)
if response.status_code==200:
SOC_json = response.json()
with open('assets/soc.json','w+') as f:
f.write(json.dumps(SOC_json))
print(SOC_json)
def run(self):
self.getSOC()
self.getTerm()
if __name__ == '__main__':
spider = Spider()
spider.run()
输出excel文件的相关代码
toexcel.py
import os,json
import pandas as pd
os.listdir('assets')
df = pd.DataFrame(columns=['MedDRA Code','SOC','TERM','Grade 1','Grade 2','Grade 3','Grade 4','Grade 5','Definition'])
with open('assets/soc.json','r') as f:
soc_json = json.load(f)
for soc_node in soc_json["data"]:
for term_node in soc_node['children']:
term_id = term_node['id']
with open('assets/{}.json'.format(term_id),'r') as f:
term_json = json.load(f)
code = term_json['data']['meddraCode']
soc = soc_node['meddraName']
term = term_json['data']['meddraName']
grade1 = term_json['data']['grade1']
grade2 = term_json['data']['grade2']
grade3 = term_json['data']['grade3']
grade4 = term_json['data']['grade4']
grade5 = term_json['data']['grade5']
definition = term_json['data']['definition']
onedata = {
'MedDRA Code':code,
'SOC':soc,
'TERM':term,
'Grade 1':grade1,
'Grade 2':grade2,
'Grade 3':grade3,
'Grade 4':grade4,
'Grade 5':grade5,
'Definition':definition
}
df = df.append(onedata,ignore_index=True)
df.to_excel('CTCAE5.0.xlsx',index=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号