进程环境
当内核执行C程序时(使用一个exec函数),在调用main前先调用一个特殊的启动例程。可执行程序文件将此启动例程指定为程序的起始地址—这是由连接编辑器设置的,而连接编辑器由C编译器调用。启动例程从内核取得命令行参数和环境变量值,然后按上述方式调用main函数做好安排。
5种正常终止
- 在main函数内执行return语句。这等效于调用exit。
- 调用exit函数。其包括调用各终止处理程序(终止处理程序在调用atexit函数时登记),然后关闭所有标准I/O流等。因为ISO C并不处理文件描述符、多进程(父进程和子进程)以及作业控制,所以这一定义对于UNIX系统而言是不完整的。
- 调用_exit或_Exit函数。ISO C定义_Exit,其目的是为进程提供一种无需运行终止处理程序或信号处理程序而终止的方法。对标准I/O是否进行冲洗,这取决于实现。在UNIX系统中,_Exit和_exit是同义的,并不冲洗标准I/O流。_exit函数由exit调用。他处理UNIX系统的特定的细节。
- 进程的最后一个线程在其启动例程中执行return语句。但是,该线程的返回值不用做进程的返回值。当最后一个线程从启动例程返回时,该进程以终止状态0返回。
- 进程的最后一个线程调用pthread_exit函数。在这种情况下,进程终止状态总是0,这与传递给pthread_exit的参数无关。
3种异常终止
- 调用abort。它产生SIGABR信号;
- 当进程接收到某些信号时。信号可由进程自身、其它进程或内核产生。例如,若进程引用地址空间之外的存储单元、或者除以0,内核就会为该进程产生相应的信号。
- 最后一个线程对“取消”请求作出响应。默认情况下,“取消”以延迟方式发生:一个线程要求取消另一个线程,若干时间之后,目标线程终止。
不管进程如何终止,最后都会执行内核中的同一段代码。这段代码为相应进程关闭所有打开描述符,释放他所使用的存储器等。
对上述任意一种终止情形,我们都希望终止进程能够通知其父进程它是如何终止的。对于e x i t和_ e x i t,这是依靠传递给它们的退出状态( exit status)参数来实现的。在异常终止情况,内核(不是进程本身)产生一个指示其异常终止原因的终止状态( termination status) 。在任意一种情况下,该终止进程的父进程都能用 w a i t或w a i t p i d函数(在下一节说明)取得其终止状态。(退出状态是传给exit/_exit的参数,或main返回值。在最后调用_exit时内核将其退出状态转为终止状态,如果子进程正常终止那父进程可以获取子进程的退出状态)。
在说明fork函数时,子进程是在父进程调用fork后生成的。子进程将其终止状态返回给父进程。但是如果父进程在子进程之前终止,该如何?回答是:对于父进程已经终止的所有进程,他们的父进程都改变为init进程。我们称这些进程由init进程收养。其操作过程大概是:在一个进程终止时,内核诸葛检查所有活动进程,以判断他是否是正要终止进程的子进程,如果是,则该进程的父进程的ID更改为1(init进程的ID)。这种处理方法保证了每一个进程都有一个父进程。
如果子进程在父进程之前终止,那么父进程如何在做相应检查时得到子进程的终止状态呢?如果子进程完全消失了,父进程在最终准备好检查子进程是否终止时是无法获得他的终止状态的。内核为每个终止子进程保存了一定量的信息。所以当终止进程的父进程调用wait或waitpid时,可以得到这些信息。这些信息至少包括进程ID、该进程的终止状态以及该进程使用的CPU时间总量。内核可以释放终止进程所使用的所有存储区,关闭其所有打开文件。在UNIX术语中,一切已经终止、但是其父进程尚未对其进行善后处理的进程被称为僵尸进程。==如果一个长期运行的程序,它fork了很多子进程,那么除非父进程取得子进程的终止状态,不然子这些进程终止后就会变成僵尸进程。
一个由init进程收养的进程最终终止时会发生什么?他会不会变成一个僵尸进程,不会的,因为init被编写成无论何时只要有一个子进程终止,init就会调用一个wait函数取得其终止状态。这样也就防止了在系统中塞满了僵尸进程。当提及“一个init的子进程”时,这指的是init直接产生的进程,也可能是其父进程已经终止,由init收养的过程。
启动例程
启动例程是这样编写的,使得从main返回后立即调用exit函数,如果将启动历程以C代码形式表示(此例程通常用汇编编写),则它调用main函数的形式可能是
exit(main(argc, argv));
exit
exit和_exit函数用于正常终止一个程序:_exit立即进入内核,exit则先执行一些清除处理(包括调用执行各终止处理程序,关闭所有标准IO流等),然后进入内核。
#include <stdlib.h> void exit(int status); #include <unistd.h> void _exit(int statu);
由于历史原因,exit函数总是执行一个标准IO库的清除关闭操作:对所有打开的流调用fclose函数,这会造成缓存中的所有数据都被刷新(写入到文件上)。
atexit
按照ANSI C的规定,一个进程可以登记多至32个的终止处理函数(exit handler),这些函数将由exit自动调用。可用atexit函数来注册这些函数。
#include <stdlib.h> int atexit(void (*func)(void)); //返回值:成功为0,出错非0
atexit的参数是一个无参数并且无返回的函数的指针。exit以注册这些函数的相反顺序调用它们。如果一个函数被注册多次那会被调用多次。 根据ANSI C和POSIX.1 exit首先调用各终止处理程序,然后按需多次调用fclose。下图显示了一个C程序是如何启动的,以及它终止的各种方式。
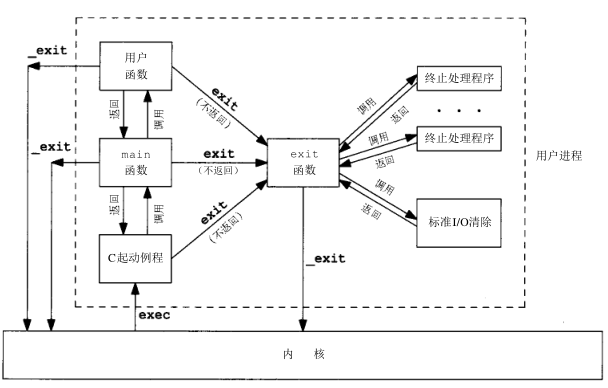
内核使程序执行的唯一方式是调用一个exec函数。
环境表
每个程序都接收到一张环境表。与参数表一样,环境表也是一个字符指针数组,其中每个指针包含一个以null结束的字符串的地址。全局变量environ则包含了该指针数组的地址。 extern char **environ; 如果该环境包含五个字符串,那么它们看起来如下图:
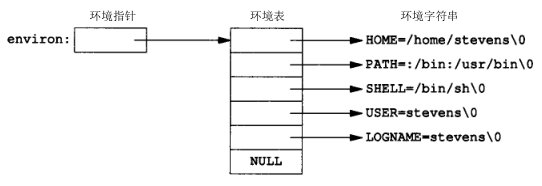
其中每个字符串的结束处都有一个null字符。我们称environ为环境指针。指针数组为环境表,其中各指针指向的字符串为环境字符串。通常使用getenv和putenv函数来存取特定的环境变量,而不是用environ变量。但是如果要查看整个环境则必须使用environ指针。
程序中内存分布

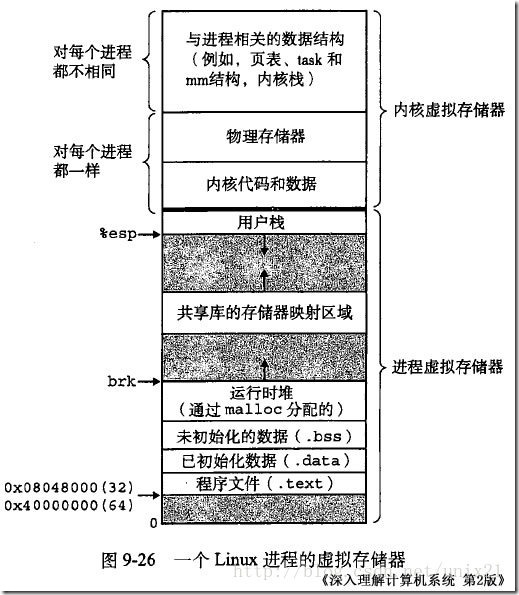
- 正文段。这是由CPU执行的机器指令部分。通常正文段是共享的,所以即使是经常执行的程序(如文本编辑程序、C编译程序、shell等)在存储器中也只需有一个副本。另外正文段常常是只读的。
- 初始化数据段。通常将此段称为数据段。其中包含了程序中需赋初值的变量。如C程序中任何函数之外的说明:
int maxcount = 99; - 非初始化数据段。通常称此段为bss段(block started by symbol, 由符号开始的块),在程序开始执行之前,内核将此段初始化为0。函数外的说明:
long sum[1000]使此变量存放在非初始化数据段中。 - 栈。自动变量以及每次函数调用所需保存的信息(返回地址和调用者的环境信息)都存放在此段中。
- 堆。通常在堆中进行动态存储分配。堆位于非初始化数据段项和栈底之间。
由编译器自动分配释放管理。局部变量及每次函数调用时返回地址、以及调用者的环境信息(例如某些机器寄存器)都存放在栈中。新被调用的函数在栈上为其自动和临时变量分配存储空间。通过以这种方式使用栈,C函数可以递归调用。递归函数每次调用自身时,就使用一个新的栈帧,因此一个函数调用实例中的变量集不会影响另一个函数调用实例中的变量。
a.局部变量
b.函数调用时返回地址
c.调用者的环境信息(例如某些机器寄存器)
从图中可以看到未初始化数据段的内容并不存放在磁盘程序文件中。需要存放在磁盘程序文件中的段只有正文段和初始化数据段。size命令报告正文段、数据段、和bss段的长度:
$ size /bin/cc /bin/sh text data bss dec hex 81920 16384 664 98968 18298 /bin/cc 90112 16384 0 106496 1a000 /bin/sh //第4列和第5列分别以十进制和十六进制表示的总长度。
Linux中可以借助brk或mmap函数从用户空间中申请连续内存。

共享库
共享库使得可执行文件中不再需要包含常用的库函数,而只需在所有进程都可存取的存储区中保存这种库例程的一个副本。程序第一次执行的时候或第一次调用某个库函数的时候,用动态链接方法将程序与共享库函数相链接,这减少了每个可执行文件的长度,但增加了一些运行时间开销。另一个优点就是可以用库函数的新版本来替换老版本而无需对该库的程序重新链接编译。
不同的系统使用不同的方法说明程序是否需要使用共享库。比较典型的有cc和ld命令的可选项。
存储器分配
ANSI C说明了三个存储空间动态分配的函数
malloc。分配指定字节数的存储区。此存储区中的初始值不确定。 (2) calloc。在内存中动态地分配nobj个长度为size的连续空间。该空间中的每一位都初始化为0。 (3) realloc。更改以前分配区的长度(增加或减少)。当增加长度时,可能需要将以前分配区的内容移到另一个足够大的区域,而且新增区域内的初始值不确定。
#include <stdlib.h> void *malloc(size_t size); void *calloc(size_t nboj, size_t size); void *realloc(void *ptr, size_t newsize); //三个函数返回:成功返回为非空指针,出错为NULL void free(void *ptr);
这三个分配函数返回的指针一定是适当对齐的,使其可以用于任何数据对象。在一个特定的系统上,如果最苛刻的对齐要求是double,则对齐必须在8的倍数的地址单元处,那么这三个函数返回的指针都应这样对齐。 free函数释放的空间通常被送入可用存储区池,以后可在调用分配函数时再调用。 realloc如果在原存储区后有足够的空间可供扩充,则可在原存储区位置上向高地址方向扩充。并返回传给它的同样的指针值。如果在原存储区后没有足够的空间则realloc分配一个足够大的存储区,将现存的内容复制到新分配的存储区中。因为这种存储区会移动位置所以不应使任何指针指到该区。 realloc的最后一个参数是存储区的newsize而不是新旧长度之差。如果ptr是空指针,则realloc功能与malloc相同。用于分配一个制定长度newsize的存储区。
这些分配例程通常通过sbrk系统调用实现。该系统调用扩充或缩小进程的堆。
虽然sbrk可以扩充或缩小一个进程的存储空间,但是大多数malloc和free的实现都不减小进程的存储空间而是将它们保存在malloc池中而不返回给内核。
大多数实现所分配的存储空间比所要求的要大,额外的空间用来记录管理信息--分配块的长度,指向下一个分配块的指针等等。这就意味着如果写过一个已分配区的尾端,则会改写后一块的管理信息。将指向分配块的指针向后移动可能也会改写本块的管理信息。
其他可能出现的错误:释放一个已经释放了的块;调用free所用的指针不是三个alloc函数的返回值等。
alloca函数是在当前函数的栈帧上分配存储空间。优点是:当函数返回时自动释放它所使用的栈帧,缺点是:某些系统在函数已经被调用后不能增加栈帧长度,于是也就不能支持alloca函数。
环境变量
ANSI C定义了一个函数getenv,可以用其取环境变量值,但是该标准又称环境的内容是由实现定义
#include <stdlib.h> char *getenv(const char *name); //返回值:指向与name关联的value的指针,未找到则返回NULL
POSIX.1和XPG3定义了某些环境变量。下表列出了由这两个标准定义并受到SVR4和4.3+BSD支持的环境变量。
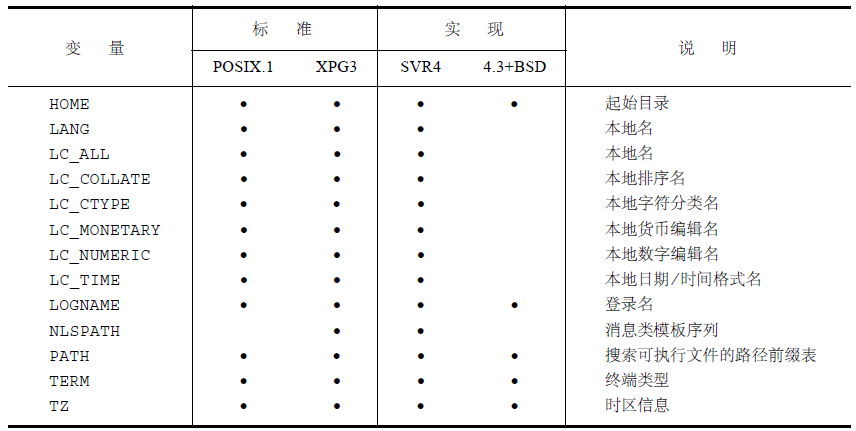
除了取环境变量值,有时也需要设置环境变量,或者是改变现有变量的值,或者是增加新的环境变量。但是不是所有系统都支持这些操作。下表列出了不同的标准及实现支持的各种函数:

#include <stdlib.h> int putenv(const char *str); int setenv(const char *name, const char *value, int rewrite); //两个函数返回:成功为0,失败非0. void unsetenv(const char *name);
这三个函数的操作是:
- putenv取形式为name=value的字符串,将其放到环境表中。如果name已存在则覆盖之前的定义。
- setenv将name设置为value。如果name已存在,(a)如果rewrite非0,则覆盖.(b)如果rewrite为0,则不覆盖而且也不出错。
- unsetenv删除name的定义,即使name不存在也不出错。
环境表和环境字符串典型的存放在进程存储空间的顶部(栈之上)。删除一个字符串很简单--只要找到该指针,然后将所有后续指针都向下移一个位置。但是增加一个字符串或修改一个现存的字符串就比较困难。栈以上的空间因为已处于进程存储空间的顶部所以无法扩充,即无法向上扩充也无法向下扩充。
1.如果修改一个现存的name:
(a) 如果新value的长度少于或等于value的长度,则只要在原字符串所用空间中写入新字符串。
(b) 如果新value的长度大于原长度,则必须调用malloc为新字符串分配空间,然后将新字符写入该空间中,然后使环境表中针对name的指针指向新分配区。
2.如果要增加一个新的name,则操作更为复杂。首先调用malloc为name=value分配空间然后将该字符串写入该空间。然后:
(a) 如果这是第一次增加一个新name,则必须调用malloc为新的指针表分配空间。将原来的环境表复制到新分配区。并将指向新name=value的指针存在该指针表的表尾,然后又将一个空指针存在其后。最后使environ指针指向新指针表。再看上一节中的内存分配图,如果原来的环境表位于栈顶之上(这是常见情况)那么必须将此表移至堆中。但是此表中的大多数指针仍指向栈顶之上的个name=value字符串。
(b) 如果这不是第一次增加一个新name,则可知以前调用malloc在堆中为环境表分匹配了空间,所以只要调用realloc,以分配比原来空间多一个指针的空间。然后将该指向新name=value字符串的指针存放在该表表尾,后面跟着一个空指针。
setjpm和longjmp
在C中不允许使用跳跃函数的goto语句。而执行这种跳转功能的是非局部跳转函数setjmp和longjmp。非局部表示这不是子啊一个函数内的普通的C语言goto语句,而是在栈上跳过若干调用栈,返回到当前函数调用路径上的一个函数中。
#include <setjmp.h> int setjmp(jmp_buf env); //返回值:直接调用则为0,若从longjmp返回则为非0 void longjmp(jmp_buf env, int val);
在希望返回到的位置调用setjmp,因为我们直接调用该函数所以其返回值为0。setjmp的参数env是一个特殊类型jmp_buf。这一数据类型是某种形式的数组,其中存放在调用longjmp时能用恢复栈状态的所有信息。一般,env变量是个全局变量,因为需要从另一个函数中引用它。
当检查到一个错误时,则调用longjmp函数,第一个参数就是在调用setjmp时所用的env,第二个val是个非0值,它成为从setjmp处返回的值。使用第二个参数的原因是对于一个setjmp可以有多个longjmp。

执行main时,调用setjmp,它将所需的信息记入变量jmpbuffer中返回0。然后调用do_line,它又调用cm_add,假定在其中检测到一个错误。在cmd_add中调用longjmp之前,栈的形式如图所示
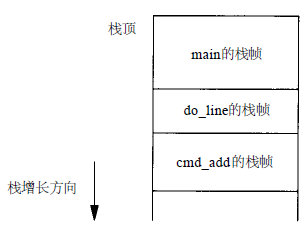
但是longjmp使栈回到执行main函数时的情况,也就是抛弃了cmd_add和do_line的栈帧。调用longjmp造成main中setjmp的返回。但是,这一次的返回值是1(longjmp的第二个参数)。
自动、寄存器和易失变量
在main函数中,自动变量和寄存器变量的状态如何?当longjmp返回到main函数时,这些变量的值是否能恢复到以前调用setjmp时的值(即滚回原先值),或者这些变量的值保持为调用do_line时的值(do_line调用cmd_add,cmd_add又调用longjmp)?大多数实现并不滚回这些自动变量和寄存器变量的值,而所有标准则说它们的值是不确定的。如果有一个自动变量而又不想使其数值滚回可以定义其为具有volatile属性。说明为全局和静态变量的值在执行longjmp时保持不变
#include <setjmp.h> static void f1(int, int, int); static void f2(void); static jmp_buf jmpbuffer; int main(void) { int count; register int val; volatile int sum; count 2; val = 3; sum = 4; if (setjmp(jmpbuffer) != 0) { printf("after longjmp: count = %d, val = %d, sum = %d\n", count, val, sum); exit(0); } count = 97; val = 98; sum = 99; f1(count, val, sum); } static void f1(int i, int j, int k) { printf("in f1():count = %d, val = %d, sum = %d\n", i, j, k); f2(); } static void f2(void) { longjmp(jmpbuffer, 1); }
如果以不带优化和带优化对此程序分别进行编译,然后运行它们得到的结果是不同的:

易失变量不受优化的影响,在longjmp之后的值,是它在调用f1时的值。存放在存储器中的变量将具有longjmp时的值,而在CPU和浮点寄存器中的变量则恢复为调用setjmp时的值。不进行优化时所有这三个变量都存放在存储器中(会忽略val寄存器存储优化)。而进行优化时,count和val都存放在寄存器中。sum由于加了volatile限定符(该限定符修饰表示告诉编译器不要对这个变量进行优化)所以不会放到寄存器中。
自动变量问题
一个open_data的函数,它打开了一个标准IO流,然后为该流设置缓存
FILE *open_data(void) { FILE *fp; char databuf[BUFSIZ]; /* setvbuf设置的标准IO缓存 */ if ((fp = fopen(DATAFILE, "r")) == NULL) { return (NULL); } if (setvbuf(fp, databuf, _IOLBF, BUFSIZ) != 0) { return (NULL); } return (fp); }
当open_data返回时,它在栈上所使用的空间将由下一个被调用函数的栈帧使用。但是,标准IO函数仍然使用原先在栈上分配的存储空间作为流的缓存。这就产生了问题。为了改正这个问题应该在全局空间静态的(如static或extern),或者动态的为数组分配空间(malloc在堆上分配)。
getrlimit和settlimit
#include <sys/time.h> #inlcude <sys/resource.h> int getrlimit(int resource, struct rlimit *rlptr); int setrlimit(int resource, const struct rlimit *rlptr); //返回值:成功为0,出错非0. struct rlimit { rlimi_t rlim_cur; /* soft limit: current limit */ rlimi_t rlim_max; /* hard limit:maximum vlaue for rlim_cur */ };
每个进程都有一组资源限制,其中一些可以用getrlimit和setrlimit函数查询和修改。
对这两个函数的每一次调用都指定一个资源以及一下指向下列结构的指针。
在更改资源限制时,须遵循下列三条规则:
- 任何一个进程都可将一个软限制更改为小于或等于其软限制。
- 任何一个进程都可降低其硬限制值,但它必须大于或等于其软限制值。这种降低,对普通用户是不可逆反的。
- 只有超级用户可以提高硬限制。
一个无限量的限制通常由常数RLIM_INFINITY指定。
这两个函数的resource参数取下列值之一。并非所有资源限制都受到SVR4和4.3+BSD的支持。
- RLIMIT_CODE (SVR4及4.3+BSD) core文件的最大字节数,若其值为0则组织创建core文件。
- RLIMIT_CPU(SVR4及4.3+BSD) CPU时间的最大量值(秒),当超过此限制时,向该进程发送SIGXCPU信号。
- RLIMIT_DATA(SVR4及4.3+BSD) 数据段的最大字节长度。这是图中初始化数据、非初始化数据以及堆的总和。
- RLIMIT_FSIZE (SVR4及4.3+BSD) 可以创建的文件的最大字节长度。当超过此软限制时,则向该进程发送SIGXFSZ信号。
- RLIMIT_MEMLOCK (4.3+BSD) 锁定在存储器地址空间(尚未实现)。
- RLIMIT_NOFILE (SVR4) 每个进程能打开的最多文件数。更改此限制将影响到sysconf函数在参数_SO_OPEN_MAX中返回的值。
- RLIMIT_NPROC (4.3+BSD) 每个实际用户ID所拥有的最大子进程数。更改此限制将影响到sysconf函数在参数_SC_CHILD_MAX中返回的值。
- RLIMIT_OFILE (4.3+BSD) 与SVR4的RLIMIT_NOFILE相同
- RLIMIT_RSS (4.3+BSD) 最大驻内存集字节长度(RSS)。如果物理存储器供不应求则内核将从进程处取回超过RSS的部分。
- RLIMIT_STACK (SVR4及4.3+BSD)栈的最大字节长度。
- RLIMIT_VMEN (SVR4) 可映照地址空间的最大字节长度。这影响到mmap函数。
资源限制将影响到调用进程并由其子进程继承。这就意味着为了影响一个用户的所有后续进程,需将资源限制设置构造在shell中。
在linux中,进程以进程号作为标识,任何对进程的操作都要赋予进程号,每个进程属于一个用户,进程要配备所属的用户编号UID,每个进程也属于多个用户组,所以好要配备其所属的组编号GID。
进程运行的环境称为上下文(context),linux中进程的上下文由进程控制块PCB(包含了进程编号,状态,优先级以及正文段和数据段中数据分布大概情况),正文段(Text segment),数据段(data segment),以及用户堆栈组成。
一个称作进程表的链表结构将系统中的所有PCB块连起来,linux中的PCB称为task_struct结构,每个task_struct结构占1680B,Linux根据系统物理内存大小限制已经打开进程的总数,每次访问一个进程时,内核根据PID在进程表中查找响应的PCB块(查找通过一个PID的hash实现),在通过PCB找到响应的代码段和数据段进行操作。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号