Springcloud学习之Sleuth+Zipkin
一、什么是Sleuth
为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。
二、Sleuth 作用
2.1:耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
2.2:可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
2.3:链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
三、Sleuth 怎么用


当客户端发起请求时,控制台即可观察到sleuth打印的请求链路日志

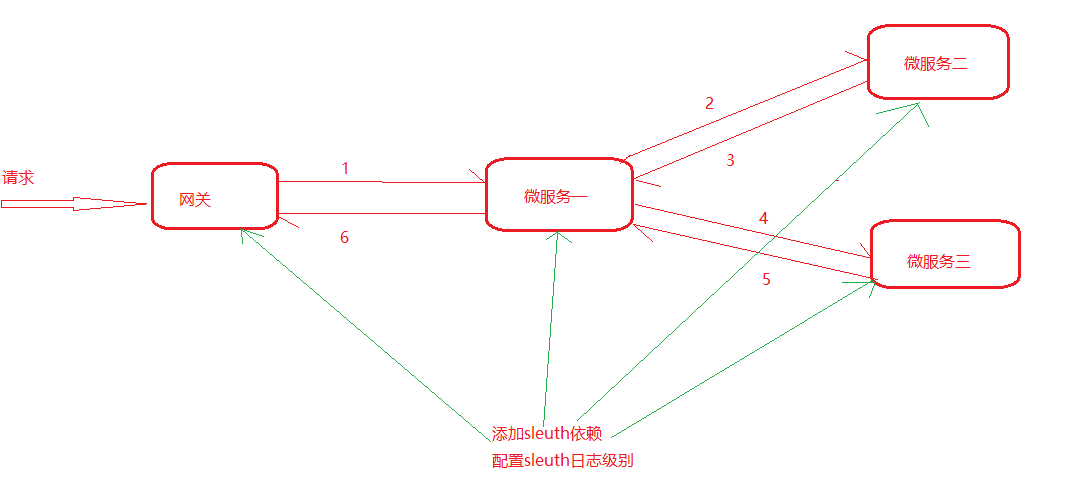
上面sleuth虽然帮助我们记录了每个请求中的链路日志,但仍然存在几点问题。1、⽇志不容易阅读观察,2、⽇志分散在各个微服务服务器上。所以接下来我们使⽤zipkin统⼀聚合轨迹⽇志并进⾏存储展示
四、什么叫Zipkin
zipkin是一种分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈
五、Zipkin用法
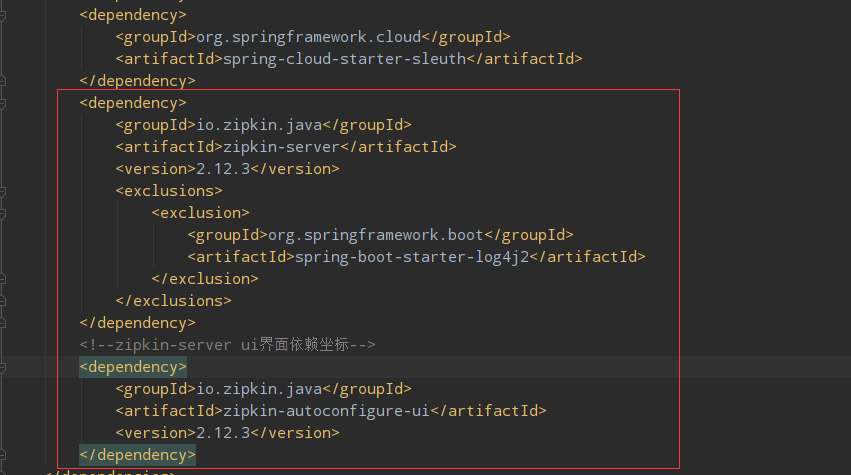
5.1:创建Zipkin服务端,引入zipkin依赖
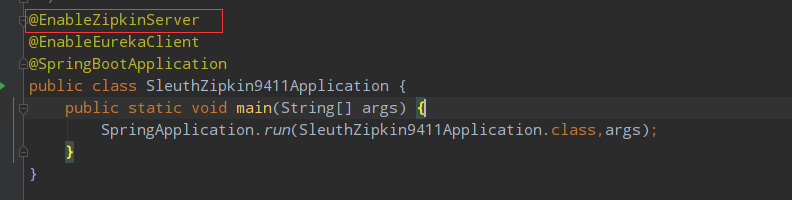
5.2:启动类上添加zipkin server开关
5.3:配置zipkin相关信息
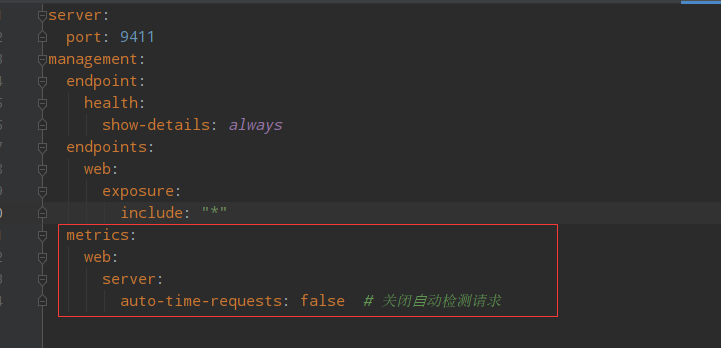
5.4:改造微服务使其作为zipkin的客户端,引入客户端依赖

5.5:配置zipkin客户端相关信息
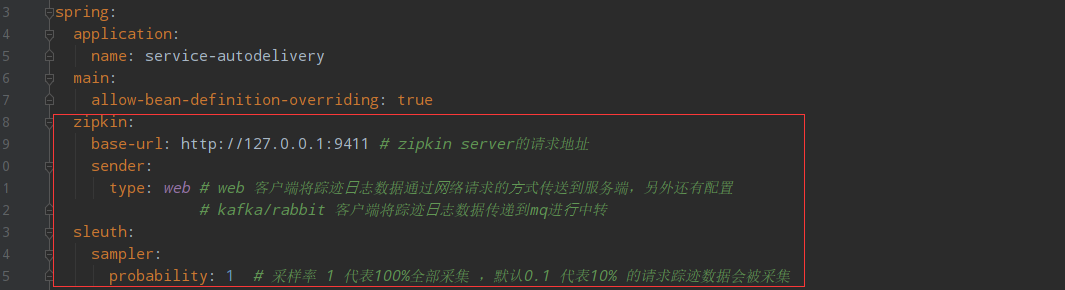
5.6:启动zipkin服务端和消费端,网页访问127.0.0.1:9411,发起请求后,操作查看
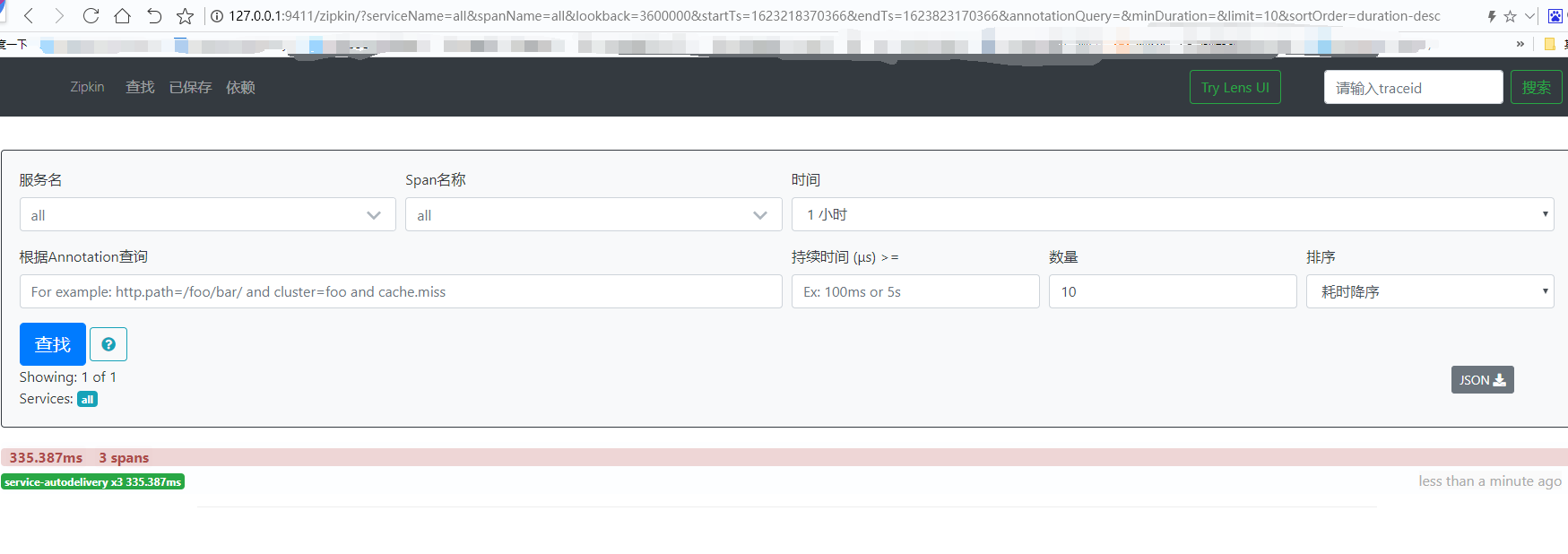
六、ZipKin持久化
6.1:创建zipkin的数据库,库和表结构官网已经给定,直接从官方拷贝即可,脚本下载地址 https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
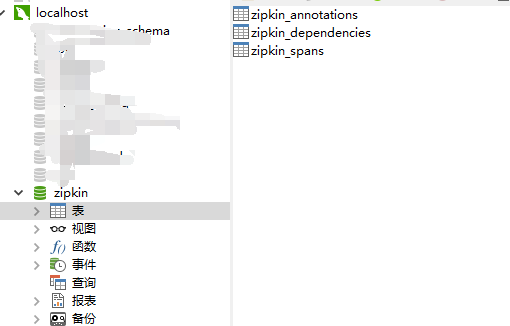
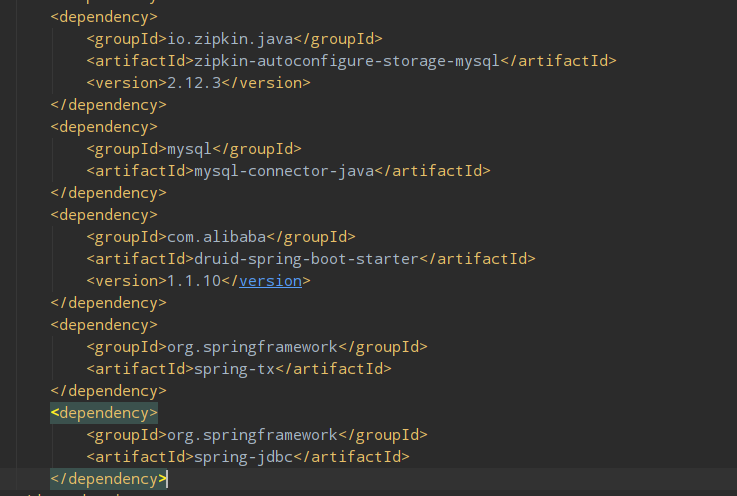
6.2:服务端引入zipkin持久化所需的依赖
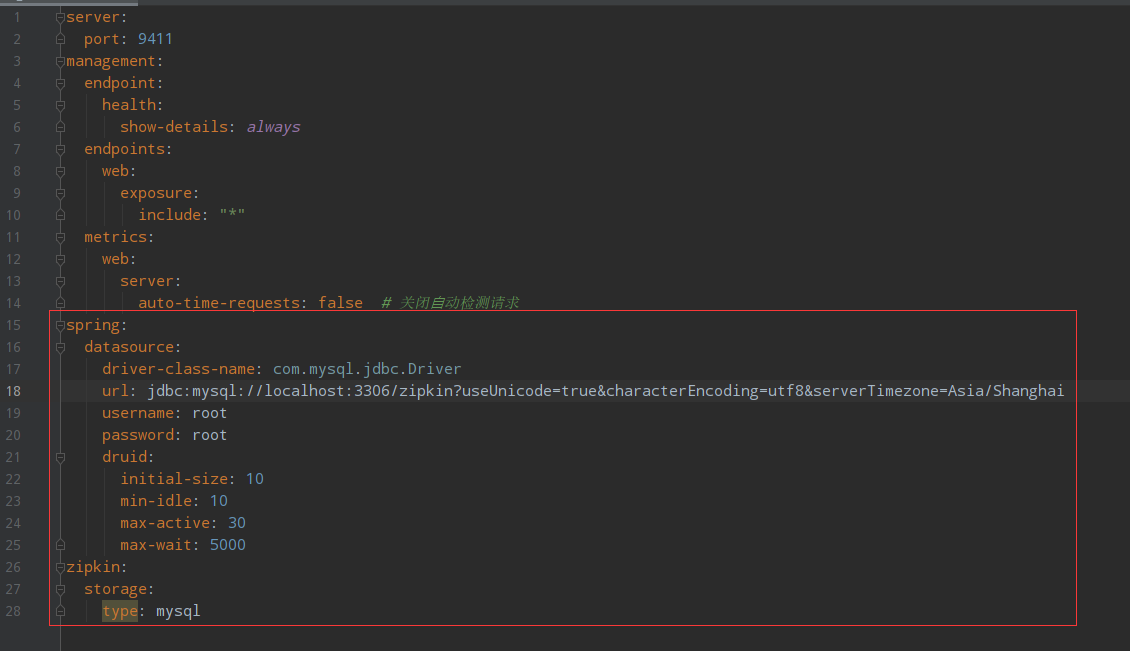
6.3:在zipkin服务端配置数据持久化相关信息
6.4:启动类中注⼊事务管理器