
最近我们公司在建立数仓,想要建立一套以Greenplum为核心的混合架构数据仓库。在这里,只想谈谈我对数据仓库的一些看法。
什么是数据仓库
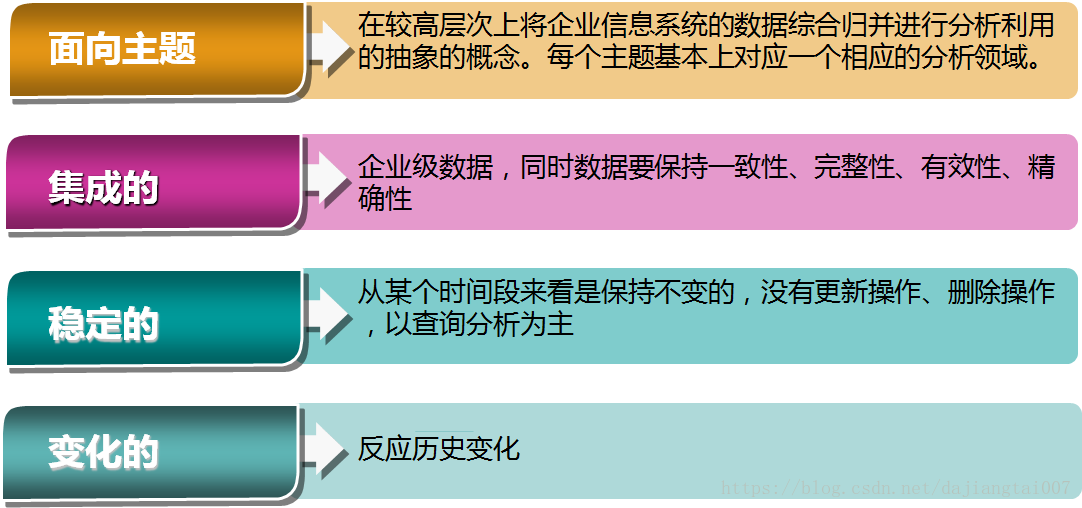
面向主题的,集成的,相对稳定的,反映历史变化的数据集合,用于支持管理决策。
为什么需要数仓
首先,我们公司是做高校大数据的。
高校的数据源形式多样,oracle、sqlserver、mysql,excel、dbf等等,异构性强。
以前我们的做法是将各个数据都导入到mysql。
然而,问题来了:
1.随着数据的增加,mysql性能不再满足我们的需求
2.在mysql中,原始数据,etl临时表,etl最终结果表,专门为某一种业务定制的表,这些表都存在于同一个数据库,造成表的杂乱以及业务用表时出现混乱
3.mysql适合小查询,不适合多维查询。
4.我们以前是将多维查询交给kylin来做,但是基于kylin预处理的特性,每次上线前都需要跑较多的数据,并有上线延期的风险
好吧,是时候做出改变了
结合自身情况对数仓的一些看法
1.首先,什么样的数据不适合数仓
不要求保留历史变化,经常需要更新的数据,不适合进入数仓
比如3A实时在线表,追求的是实时性,更新频率高,历史数据由3A历史上下线表来保存,对于实时表,数据库才是其最后的归宿
2.什么样的数据适合用拉链表
对于拉链表,我也只是了解。
举个例子:对于贫困生信息
以前的业务逻辑是只要曾经是贫困生,就算他是贫困生。
现在业务逻辑改了,如果一个学生当学年是贫困生,那么他的贫困生标记应当记为当学年的,如果下学年不是了,那下学年就不是了,但查询这学年的信息,则还是
其实贫困生信息也属于一个缓慢变化的事实表,这种可以使用拉链表
3.ETL应该放在数据仓库里面做还是分情况讨论
个人的看法还是建议分情况来做吧。
对于数据源是数据库的,这部分数据本身是格式化的,本身会受到数据库的约束,ETL的主要内容还是对一些空值、时间格式来做,以及根据业务去etl
对于数据源是文档类型的(excel、dbf),这部分数据可能是手工录入的,错误数据比较多。且本身这类数据脏数据也较多(重复录入的、多人录入导致标准不统一的)
这类数据etl过程复杂,会用到多种手段(SQL、代码等)。
最关键的一点是,这类数据因为没有数据库的约束,我们etl时无法将过程封装成脚本来方便下次处理(因为下次过来的数据特征又跟上一次的不一样了)
这类数据,有两种方式来处理:
第一种是导入到数据库中来处理
第二种是用python的pandas模块来处理
4.对于一些缓慢变化维度的处理
与其说是处理,不如说要先监控
比如,我们有一个消费维度表是通过消费表中的2个字段来生成的,这种生成是手工整理的。
如果消费表中的2个字段有增加,我们也是没有办法来监控的
这种可能需要脚本来监控
