


KingbaseES V8R6集群运维案例之---备库register故障
案例说明:
据现场实施人员说,备库执行了clone,启动数据库服务,执行'repmgr standby register'后,无法将备库register到集群。
适用版本:
KingbaseES V8R6
一、问题现象
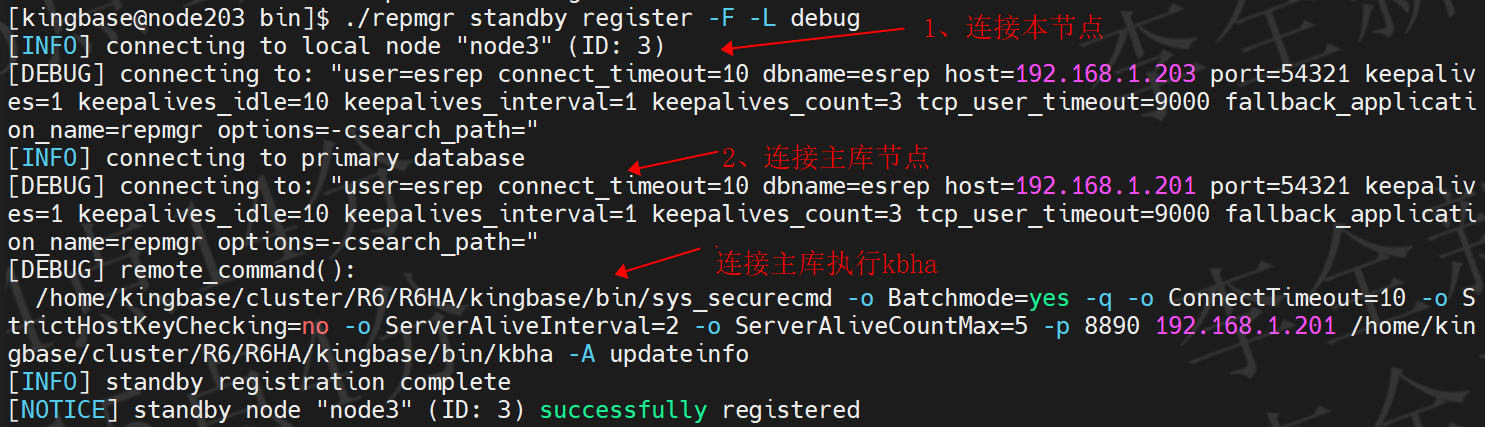
如下图所示,执行'repmgr standby register' ,register失败:

二、问题分析
1、repmgr standby register分析
如下图所示:
1) 备库读取repmgr.conf获取本节点信息,并连接。
2)备库读取repmgr.nodes元数据,获取主库节点信息,并连接。
3)连接主库节点,执行备库节点的register。
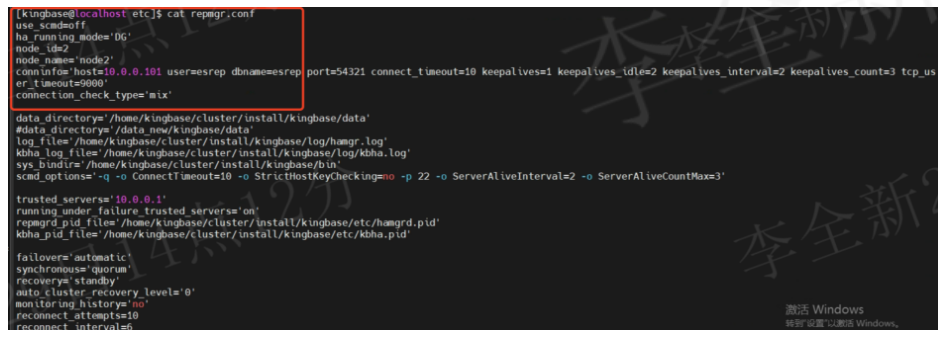
2、查看备库repmgr.conf配置
如下图所示,备库节点配置正常。
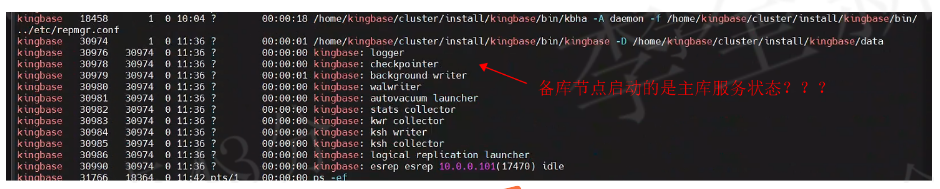
3、检查备库的数据库服务
如下图所示,远程连接到备库节点检查数据库服务,竟然发现备库数据库服务启动在primary状态???
三、问题解决
1、在备库data下创建standby.signal文件
[kingbase@localhost data]$ touch standby.signal
2、主库节点创建备库复制槽

3、重启备库数据库服务(数据库服务在standby状态)
[kingbase@localhost bin]$ ./sys_ctl restart -D ../data
等待服务器进程关闭 ....... 完成
4、执行repmgr standby register
[kingbase@localhost bin]$ ./repmgr standby register --force -L debug
[INFO] connecting to local node "node2" (ID: 2)
[DEBUG] connecting to: "user=esrep connect_timeout=10 dbname=esrep host=10.0.0.101 port=54321 keepalives=1 keepalives_idle=2 keepalives_interval=2 keepalives_count=3 tcp_user_timeout=9000 fallback_application_name=repmgr options=-csearch_path="
[INFO] connecting to primary database
[DEBUG] connecting to: "user=esrep connect_timeout=10 dbname=esrep host=10.0.0.100 port=54321 keepalives=1 keepalives_idle=2 keepalives_interval=2 keepalives_count=3 tcp_user_timeout=9000 fallback_application_name=repmgr options=-csearch_path="
[DEBUG] remote_command():
ssh -o Batchmode=yes -q -o ConnectTimeout=10 -o StrictHostKeyChecking=no -p 22 -o ServerAliveInterval=2 -o ServerAliveCountMax=3 10.0.0.100 /home/kingbase/cluster/install/kingbase/bin/kbha -A updateinfo
[INFO] standby registration complete
[NOTICE] standby node "node2" (ID: 2) successfully registered
---如上所示,standby节点register成功。
5、查看集群节点状态
[kingbase@localhost bin]$ repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | LSN_Lag | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | node1 | primary | * running | | default | 100 | 1 | | host=10.0.0.100 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=2 keepalives_interval=2 keepalives_count=3 tcp_user_timeout=9000
2 | node2 | standby | running | node1 | default | 100 | 1 | 0 bytes | host=10.0.0.101 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=2 keepalives_interval=2 keepalives_count=3 tcp_user_timeout=9000
四、总结
此次案例,是因为备库节点的数据库服务状态启动到了primary模式,导致执行'remgr stanby register'失败,在执行备库克隆后,启动数据库服务注册集群前,需要检查下当前备库的数据库服务状态,状态正常后,再执行register。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)