


KingbaseES V8R6集群运维案例之---级联备库upstream节点故障
案例说明:
在KingbaseES V8R6集群,构建级联备库后,在其upstream的节点故障后,级联备库如何处理?
适用版本:
KingbaseES V8R6
集群架构:
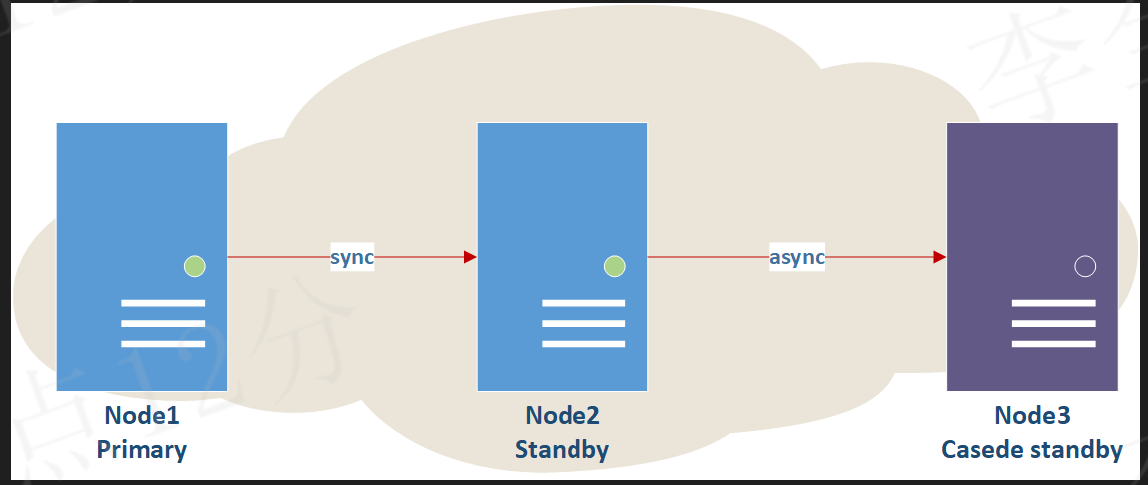
案例一:
一、配置集群的recovery参数(all nodes)
Tips: 关闭备库的aut-recovery机制
[kingbase@node102 bin]$ cat ../etc/repmgr.conf |grep -i recovery
recovery='manual'
二、查看当前集群状态
1、节点状态
[kingbase@node103 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | LSN_Lag | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+---------+----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node1 | primary | * running | | default | 100 | 20 | | host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node2 | standby | running | node1 | default | 100 | 20 | 0 bytes | host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
3 | node3 | standby | running | node2 | default | 100 | 20 | 0 bytes | host=192.168.1.103 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
如下图所示:node3的upstream节点是node2

2、流复制状态
Tips:在node2节点查看流复制状态信息,node3和node2构建流复制。
test=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_
start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | f
lush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+---------+------------------+---------------+-----------------+-------------+-----------------
--------------+--------------+---------+------------+------------+------------+------------+----------------+----
------------+----------------+---------------+------------+-------------------------------
21188 | 10 | system | node3 | 192.168.1.103 | | 60130 | 2023-08-24 11:37
:16.149515+08 | | catchup | 2/104C0000 | 2/103E0000 | 2/10320000 | 2/9C47A08 | 0:00:06.917596 | 0:0
0:06.917596 | 0:00:06.917596 | 0 | async | 2023-08-24 11:37:24.604332+08
(1 row)
test=# select * from sys_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin
| restart_lsn | confirmed_flush_lsn
---------------+--------+-----------+--------+----------+-----------+--------+------------+-------+--------------
+-------------+---------------------
repmgr_slot_3 | | physical | | | f | t | 21188 | 60748 |
| 2/52AA0000 |
(1 row)
三、模拟upstream节点数据库服务故障
1、查看node3节点repmgrd进程
[kingbase@node103 bin]$ ps -ef |grep repmgrd
kingbase 4619 1 0 11:47 ? 00:00:02 ./repmgrd -d
2、关闭node2(upstream)节点数据库服务
[kingbase@node102 bin]$ ./sys_ctl stop -D /data/kingbase/c7/data/
........
server stopped
3、查看节点状态
如下图所示,node3的upstream节点更新为node1.

4、查看node3节点hamgr.log
如下日志所示,node3在连接node2失败超过阈值后,执行了‘repmgr standby follow’更新了upstream节点。
[2023-08-24 11:47:51] [INFO] checking state of node 2, 1 of 2 attempts
[2023-08-24 11:47:51] [WARNING] unable to ping "user=system connect_timeout=10 dbname=esrep host=192.168.1.102 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
[2023-08-24 11:47:51] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-08-24 11:47:51] [INFO] sleeping 5 seconds until next reconnection attempt
[2023-08-24 11:47:56] [INFO] checking state of node 2, 2 of 2 attempts
[2023-08-24 11:47:56] [WARNING] unable to ping "user=system connect_timeout=10 dbname=esrep host=192.168.1.102 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
[2023-08-24 11:47:56] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-08-24 11:47:56] [WARNING] unable to reconnect to node 2 after 2 attempts
# node3节点执行‘repmgr standby follow’更新upstream节点
[2023-08-24 11:47:56] [DEBUG] standby follow command is:
"/home/kingbase/cluster/R6HA/ha7/kingbase/kingbase/bin/repmgr standby follow -f /home/kingbase/cluster/R6HA/ha7/kingbase/kingbase/etc/repmgr.conf -W --upstream-node-id=%n"
[WARNING] following problems with command line parameters detected:
--no-wait will be ignored when executing STANDBY FOLLOW
[DEBUG] connecting to: "user=esrep connect_timeout=10 dbname=esrep host=192.168.1.103 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr options=-csearch_path="
[DEBUG] connecting to: "user=system connect_timeout=10 dbname=esrep host=192.168.1.101 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr options=-csearch_path="
[INFO] timelines are same, this server is not ahead
[DETAIL] local node lsn is 2/FE169FB0, follow target lsn is 2/FE16A510
[INFO] creating replication slot as user "system"
[DEBUG] replication slot "repmgr_slot_3" exists but is inactive; reusing
[DEBUG] connecting to: "user=esrep connect_timeout=10 dbname=esrep host=192.168.1.103 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr options=-csearch_path="
[NOTICE] setting node 3's upstream to node 1
[NOTICE] begin to stopp server at 2023-08-24 11:47:56.612680
[NOTICE] stopping server using "/home/kingbase/cluster/R6HA/ha7/kingbase/kingbase/bin/sys_ctl -D '/data/kingbase/hac7/data' -l /home/kingbase/cluster/R6HA/ha7/kingbase/kingbase/bin/logfile -w -t 90 -m fast stop"
[NOTICE] stopp server finish at 2023-08-24 11:47:58.797572
[NOTICE] begin to start server at 2023-08-24 11:47:58.797665
[NOTICE] starting server using "/home/kingbase/cluster/R6HA/ha7/kingbase/kingbase/bin/sys_ctl -w -t 90 -D '/data/kingbase/hac7/data' -l /home/kingbase/cluster/R6HA/ha7/kingbase/kingbase/bin/logfile start"
[NOTICE] start server finish at 2023-08-24 11:47:58.907499
[DEBUG] connecting to: "user=system connect_timeout=10 dbname=esrep host=192.168.1.102 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr options=-csearch_path="
[WARNING] unable to connect to old upstream node 2 to remove replication slot
[HINT] if reusing this node, you should manually remove any inactive replication slots
[NOTICE] STANDBY FOLLOW successful
[DETAIL] standby attached to upstream node "node1" (ID: 1)
[2023-08-24 11:47:58] [DEBUG] connecting to: "user=esrep connect_timeout=10 dbname=esrep host=192.168.1.103 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr options=-csearch_path="
INFO: set_repmgrd_pid(): provided pidfile is /home/kingbase/cluster/R6HA/ha7/kingbase/kingbase/etc/hamgrd.pid
[2023-08-24 11:47:58] [DEBUG] update_node_record_set_upstream(): Updating node 3's upstream node to 1
[2023-08-24 11:47:58] [NOTICE] node "node3" (ID: 3) is now following primary node "node1" (ID: 1)
[2023-08-24 11:47:58] [DEBUG] monitor_streaming_standby()
[2023-08-24 11:47:58] [DEBUG] upstream node ID in local node record is 1
[2023-08-24 11:47:58] [DEBUG] connecting to upstream node 1: "host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3"
[2023-08-24 11:47:58] [DEBUG] connecting to: "user=system connect_timeout=10 dbname=esrep host=192.168.1.101 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr options=-csearch_path="
[2023-08-24 11:47:58] [DEBUG] upstream node is primary
[2023-08-24 11:47:58] [DEBUG] primary_node_id is 1
[2023-08-24 11:47:58] [DEBUG] connection check type is "mix"
.......
5、查看node3的kingbase.auto.conf
如下所示,kiangbase.auto.conf被更新为与node1连接。
[kingbase@node103 bin]$ cat /data/kingbase/hac7/data/kingbase.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
wal_retrieve_retry_interval = '5000'
primary_conninfo = 'user=system connect_timeout=10 host=192.168.1.101 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 application_name=node3'
primary_slot_name = 'repmgr_slot_3'
6、在node1上查看流复制
如下所示,node3和node1(primary)建立了流复制。
test=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_
start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_
lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+---------+------------------+---------------+-----------------+-------------+-----------------
--------------+--------------+-----------+------------+------------+------------+------------+-----------+-------
----+------------+---------------+------------+-------------------------------
29279 | 10 | system | node3 | 192.168.1.103 | | 36038 | 2023-08-24 11:48
:00.187956+08 | | streaming | 2/FE16AE98 | 2/FE16AE98 | 2/FE16AE98 | 2/FE16AE98 | |
| | 1 | quorum | 2023-08-24 11:53:22.358465+08
(1 row)
test=# select * from sys_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin
| restart_lsn | confirmed_flush_lsn
---------------+--------+-----------+--------+----------+-----------+--------+------------+-------+--------------
+-------------+---------------------
repmgr_slot_2 | | physical | | | f | f | | 60809 |
| 2/FE169FB0 |
repmgr_slot_3 | | physical | | | f | t | 29279 | 60819 |
| 2/FE16AE98 |
(2 rows)
7、恢复upstream节点数据库服务
如下所示,在原upstream节点node2数据库服务恢复后,集群架构没有发生变化,node3的upstream仍然是node1。
# 启动node2数据库服务
[kingbase@node102 bin]$ ./sys_ctl start -D /data/kingbase/hac7/data/
........
server started
# node1查看集群状态和流复制
[kingbase@node102 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | LSN_Lag | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+---------+----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node1 | primary | * running | | default | 100 | 20 | | host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node2 | standby | running | node1 | default | 100 | 20 | 0 bytes | host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
3 | node3 | standby | running | node1 | default | 100 | 20 | 0 bytes | host=192.168.1.103 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
test=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_
start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_
lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+---------+------------------+---------------+-----------------+-------------+-----------------
--------------+--------------+-----------+------------+------------+------------+------------+-----------+-------
----+------------+---------------+------------+-------------------------------
29279 | 10 | system | node3 | 192.168.1.103 | | 36038 | 2023-08-24 11:48
:00.187956+08 | | streaming | 2/FE16BAB0 | 2/FE16BAB0 | 2/FE16BAB0 | 2/FE16BAB0 | |
| | 1 | quorum | 2023-08-24 11:56:21.772887+08
31368 | 10 | system | node2 | 192.168.1.102 | | 62287 | 2023-08-24 11:54
:25.132463+08 | | streaming | 2/FE16BAB0 | 2/FE16BAB0 | 2/FE16BAB0 | 2/FE16BAB0 | |
| | 1 | quorum | 2023-08-24 11:56:17.049560+08
(2 rows)
案例二:
四、配置备库auto-recovery
[kingbase@node101 bin]$ cat ../etc/repmgr.conf |grep -i recovery
recovery='standby'
1、upstream节点down后集群状态
[kingbase@node102 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | LSN_Lag | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+---------+----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node1 | primary | * running | | default | 100 | 20 | | host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node2 | standby | - failed | ? node1 | default | 100 | | ? | host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
3 | node3 | standby | running | node1 | default | 100 | 20 | 0 bytes | host=192.168.1.103 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
[WARNING] following issues were detected
- unable to connect to node "node2" (ID: 2)
----如上所示,node3的upstream更新为node1
2、node3节点hamgr.log
如下所示,node2节点数据库服务down后,node3节点在node2被recovery前,更新为node1。
[2023-08-24 16:11:23] [DEBUG] is_server_available(): ping status for "host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3" is PQPING_OK
[2023-08-24 16:11:23] [DEBUG] get_recovery_type(): SELECT pg_catalog.pg_is_in_recovery()
[2023-08-24 16:11:23] [ERROR] unable to execute repmgr.set_upstream_last_seen()
[2023-08-24 16:11:23] [DETAIL] query text is:
SELECT repmgr.set_upstream_last_seen(2)
........
[2023-08-24 16:11:48] [NOTICE] upstream for local node "node3" (ID: 3) appears to have changed, restarting monitoring
[2023-08-24 16:11:48] [DETAIL] currently monitoring upstream 2; new upstream is 1
[2023-08-24 16:11:48] [DEBUG] monitor_streaming_standby()
[2023-08-24 16:11:48] [DEBUG] upstream node ID in local node record is 1
五、总结
对于级联备库,当其上游节点数据库服务down后,会自动将upstream节点更新为primary节点。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)
2022-08-24 KingbaseES V8R3集群运维案例之---用户自定义表空间管理