制作自己的数据集(VOC2007格式)用于Faster-RCNN训练
一、数据集文件夹
新建一个文件夹,用来存放整个数据集,或者和voc2007一样的名字:VOC2007
然后在文件夹里面新建如下文件夹:
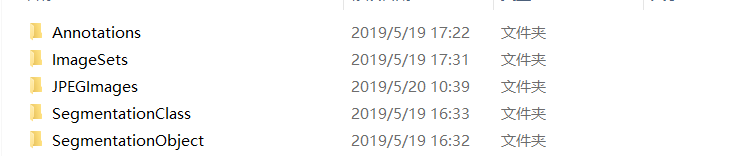
二、将训练图片放到JPEGImages
将所有的训练图片放到该文件夹里,然后将图片重命名为VOC2007的“000005.jpg”形式
重命名的python代码为:


import os path = r"D:\VOC2007\JPEGImages" filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹) count=0 for file in filelist: print(file) for file in filelist: #遍历所有文件 Olddir=os.path.join(path,file) #原来的文件路径 if os.path.isdir(Olddir): #如果是文件夹则跳过 continue filename=os.path.splitext(file)[0] #文件名 filetype=‘.jpg’ #文件扩展名 Newdir=os.path.join(path,str(count).zfill(6)+filetype) #用字符串函数zfill 以0补全所需位数 os.rename(Olddir,Newdir)#重命名 count+=1
三、标注图片,标注文件保存到Annotations
使用Github上的labelimg:https://github.com/tzutalin/labelImg
这一步需要安装Pyqt and lxml 下载地址:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#PyQt4
https://www.lfd.uci.edu/~gohlke/pythonlibs/#Lxml
然后在labelImage 的目录下 shift+右键打开PowerShell 运行一下命令:
pyrcc4 -py3 -o resources.py resources.qrc
python labelImg.py
这个时候,就会出现labelimage的窗口
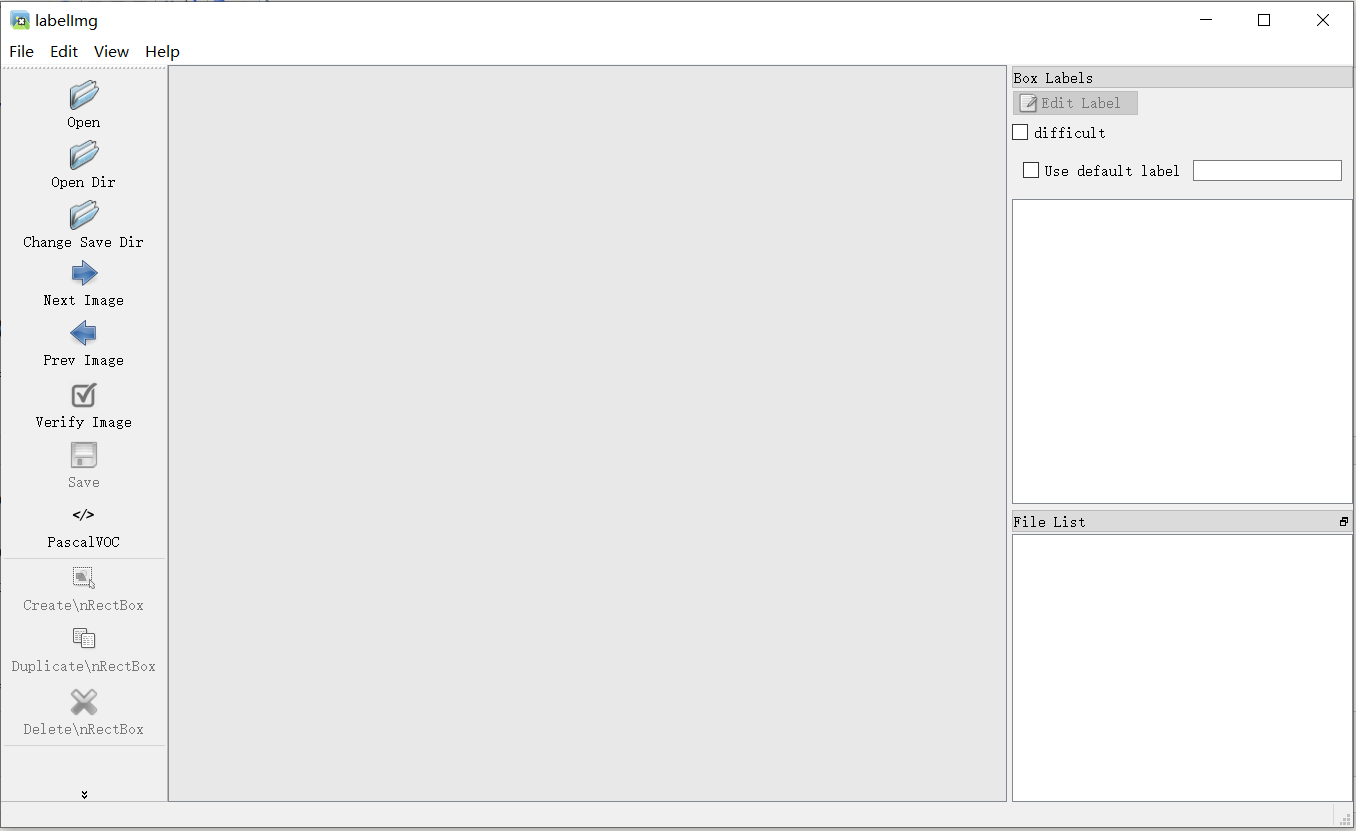
labelimg窗口的使用方法:
• 源码文件夹中使用notepad++打开data/predefined_classes.txt,可以修改默认类别,比如改成bus、car、building三个类别。 先修改,再打开labelimage
• 修改默认的XML文件保存位置,可以用“Ctrl+R”,改为自定义位置(D:\VOC2007\Annotations 数据集的Annotations 文件夹),这里的路径不能包含中文,否则无法保存。
•“Open Dir”打开需要标注的样本图片文件夹,会自动打开第一张图片,开始进行标注
• 使用“Create RectBox”开始画框
• 完成一张图片后点击“Save”,此时XML文件已经保存到本地了。
• 点击“Next Image”转到下一张图片。
• 标注过程中可随时返回进行修改,后保存的文件会覆盖之前的。
• 完成标注后打开XML文件,发现确实和PASCAL VOC所用格式一样。
PS:
每个图片和标注得到的xml文件,JPEGImages文件夹里面的一个训练图片,对应Annotations里面的一个同名XML文件,一 一 对应,命名一致
标注自己的图片的时候,类别名称请用小写字母,比如汽车使用car,不要用Car
pascal.py中读取.xml文件的类别标签的代码:
cls = self._class_to_ind[obj.find('name').text.lower().strip()]
写的只识别小写字母,如果你的标签含有大写字母,可能会出现KeyError的错误。
四、ImageSets\Main里的四个txt文件
在ImageSets里再新建文件夹,命名为Main,在Main文件夹中生成四个txt文件,即:

test.txt是测试集
train.txt是训练集
val.txt是验证集
trainval.txt是训练和验证集
VOC2007中,trainval大概是整个数据集的50%,test也大概是整个数据集的50%;train大概是trainval的50%,val大概是trainval的50%。
txt文件中的内容为样本图片的名字(不带后缀),格式如下:
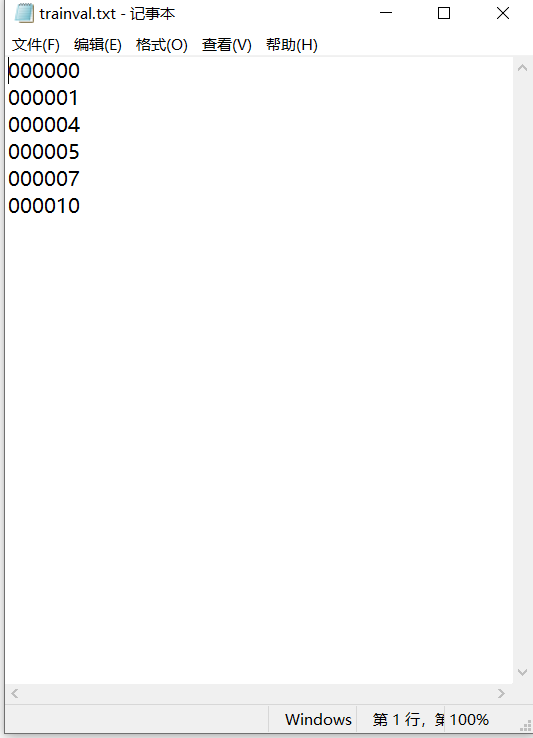
根据已生成的xml,制作VOC2007数据集中的trainval.txt ; train.txt ; test.txt ; val.txt
trainval占总数据集的50%,test占总数据集的50%;train占trainval的50%,val占trainval的50%;
上面所占百分比可根据自己的数据集修改,如果数据集比较少,test和val可少一些
在自己的VOC2007文件夹下创建.py文件,运行以下程序
import os import random trainval_percent = 0.66 train_percent = 0.5 xmlfilepath = 'Annotations' txtsavepath = 'ImageSets\Main' total_xml = os.listdir(xmlfilepath) num=len(total_xml) list=range(num) tv=int(num*trainval_percent) tr=int(tv*train_percent) trainval= random.sample(list,tv) train=random.sample(trainval,tr) ftrainval = open('ImageSets/Main/trainval.txt', 'w') ftest = open('ImageSets/Main/test.txt', 'w') ftrain = open('ImageSets/Main/train.txt', 'w') fval = open('ImageSets/Main/val.txt', 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest .close() -------------------
或者
xmlfilepath='E:\Annotations'; txtsavepath='E:\ImageSets\Main\'; trainval_percent=0.5; #trainval占整个数据集的百分比,剩下部分就是test所占百分比 train_percent=0.5; #train占trainval的百分比,剩下部分就是val所占百分比 xmlfile=dir(xmlfilepath); numOfxml=length(xmlfile)-2;#减去.和.. 总的数据集大小 trainval=sort(randperm(numOfxml,floor(numOfxml*trainval_percent))); test=sort(setdiff(1:numOfxml,trainval)); trainvalsize=length(trainval); #trainval的大小 train=sort(trainval(randperm(trainvalsize,floor(trainvalsize*train_percent)))); val=sort(setdiff(trainval,train)); ftrainval=fopen([txtsavepath 'trainval.txt'],'w'); ftest=fopen([txtsavepath 'test.txt'],'w'); ftrain=fopen([txtsavepath 'train.txt'],'w'); fval=fopen([txtsavepath 'val.txt'],'w'); for i=1:numOfxml if ismember(i,trainval) fprintf(ftrainval,'%s\n',xmlfile(i+2).name(1:end-4)); if ismember(i,train) fprintf(ftrain,'%s\n',xmlfile(i+2).name(1:end-4)); else fprintf(fval,'%s\n',xmlfile(i+2).name(1:end-4)); end else fprintf(ftest,'%s\n',xmlfile(i+2).name(1:end-4)); end end fclose(ftrainval); fclose(ftrain); fclose(fval); fclose(ftest);
至此,VOC2007数据集制作完成,后续会将此数据集用于tensorflow faster rcnn中使用。
参考文章:https://blog.csdn.net/u011574296/article/details/78953681
https://blog.csdn.net/weixin_38124357/article/details/78425890
