
【interview】2020.07.08
1. 解释 http 无状态的含义、cookie 是怎么设置的、cookie 有什么作用、cookie 的优点缺点
- http 无状态的含义:
使同一个客户端连续两次发送请求给服务器,服务器也识别不出这是同一个客户端发送的请求,
这导致的问题就比如你加了一个商品到购物车中,但因为识别不出是同一个客户端,你刷新下页面就没有了……
- cookie 设置:
- 客户端发送 HTTP 请求到服务器
- 当服务器收到 HTTP 请求时,在响应头里面添加一个 Set-Cookie 字段
- 浏览器收到响应后保存下 Cookie
- 之后对该服务器每一次请求中都通过 Cookie 字段将 Cookie 信息发送给服务器
- cookie 作用:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
- cookie 缺点:大小、安全、增加请求大小
2. 你知道Cookie、sessionStorage、localStorage的区别吗?
- cookie
cookie 一般由服务器生成,无兼容性问题 ,可设置存储时间,存放大小4kb,所以cookie只适合保存很小的数据
cookie 数据 始终在同源的 http 请求中携带(即使不需要)
cookie 的内容主要包括:名字、值、过期时间、路径和域。
路径与域一起构成cookie的作用范围。
- 会话 cookie
若不设置时间,则表示这个cookie的生命期为浏览器会话期间,关闭浏览器窗口,cookie就会消失。
会话cookie一般不存储在硬盘而是保存在内存里,当然这个行为并不是规范规定的。
- 持久性 cookie
若设置了过期时间,浏览器就会把 cookie 保存到硬盘上,关闭后再打开浏览器这些cookie仍然有效直到超过设定的过期时间。
- cookie 和 session 的区别
1)cookie 数据存放在客户的浏览器上,是服务端向客户端写入的小的片段信息,session 数据放在服务器上
2)cookie 不是很安全,别人可以分析存放在本地的 cookie 并进行 cookie 欺骗,考虑到安全应当使用session
3)session 会在一定时间内保存在服务器上,当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用 cookie
4)单个 cookie 保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie
5)建议将登录信息等重要信息存放为 session,其他信息如果需要保留,可以放在 cookie 中
6)session 保存在服务器,客户端不知道其中的信息;cookie保存在客户端,服务器能够知道其中的信息
7)session中保存的是对象,cookie中保存的是字符串
8)session 需要借助 cookie 才能正常工作。如果客户端完全禁止 cookie,session 将失效。
- sessionStorage , localStorage 为本地存储
localStorage 不做手动清除的话一直都会有。 存储长度 5M
sessionStorage 关闭浏览器就会清空,存放大小5Mb一般,仅在本地(客户端中)存储
- webStorage
虽然也有存储大小的限制,但是比cookie大得多,可以达到5M或更大数据的有效期不同
2. 点击:浏览器内核、进程、线程、事件模型、事件传播、事件委派/事件代理、event对象属性及方法
3. vue 的 SEO 方案。参考:https://www.jb51.net/article/164285.htm
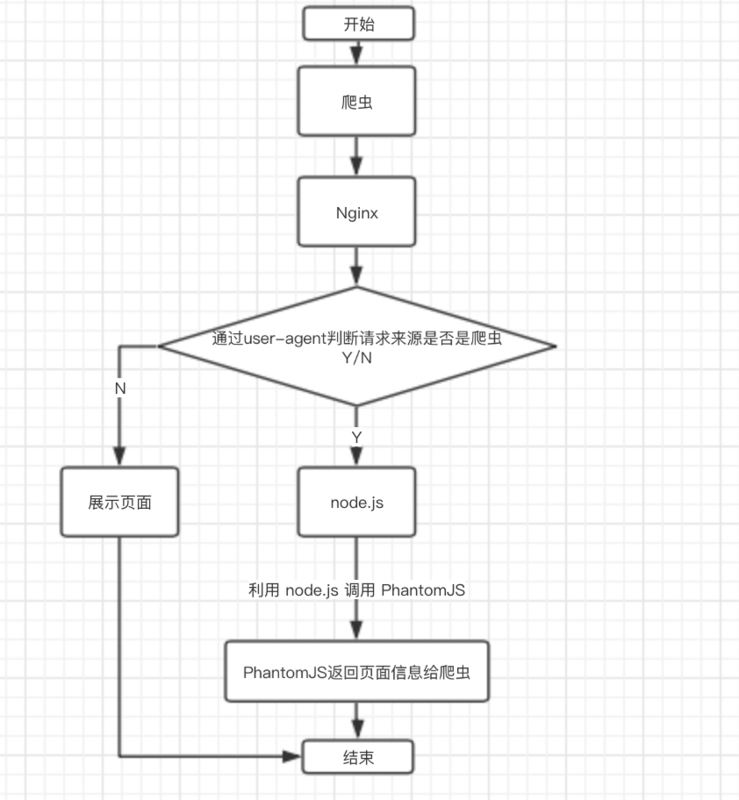
使用 Phantomjs 针对爬虫做处理
hantomjs 是一个基于 webkit 内核的无头浏览器,即没有UI界面,即它就是一个浏览器
只是其内的点击、翻页等人为相关操作需要程序设计实现。
虽然 “PhantomJS 宣布终止开发”,但是已经满足对 Vue 的 SEO 处理。
如果对已用 SPA 开发完成的项目进行 SEO 优化,而且支持 node 服务器,请使用 Phantomjs
这种解决方案其实是一种旁路机制,原理就是通过 Nginx 配置, 判断访问的来源 UA 是否是爬虫访问,
如果是则将搜索引擎的爬虫请求转发到一个 node server,再通过 PhantomJS 来解析完整的HTML,返回给爬虫。
具体代码戳这里: vue-seo-phantomjs 。
- 要安装全局 phantomjs ,局部 express ,测试:
-
phantomjs spider.js 'https://www.baidu.com'
如果见到在命令行里出现了一堆 html,那恭喜你,你已经征服 PhantomJS 啦。
- 启动之后 或者用 postman 在请求头增加 User-Agent 值为 Baiduspider ,效果一样的。
部署上线
- 线上要安装
node、pm2、phantomjs - nginx 相关配置
-
upstream spider_server { server localhost:3000; } server { listen 80; server_name example.com; location / { proxy_set_header Host $host:$proxy_port; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") { proxy_pass http://spider_server; } } }
优势:
- 完全不用改动项目代码,按原本的SPA开发即可,对比开发SSR成本小不要太多;
- 对已用SPA开发完成的项目,这是不二之选。
不足:
- 部署需要node服务器支持;
- 爬虫访问比网页访问要慢一些,因为定时要定时资源加载完成才返回给爬虫;
- 如果被恶意模拟百度爬虫大量循环爬取,会造成服务器负载方面问题,解决方法是判断访问的IP,是否是百度官方爬虫的IP。
