
[数据结构与算法 05] 链表 Linked list
参考:https://time.geekbang.org/column/article/40036
LRU 缓存淘汰算法 -------- 一个经典的链表应用场景
- 缓存
是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用
比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等
- 缓存淘汰策略
缓存的大小有限,当缓存被用满时,来决定哪些数据应该被清理出去,哪些数据应该被保留
常见的策略有三种:
- 先进先出策略 FIFO(First In,First Out)
- 最少使用策略 LFU(Least Frequently Used)
- 最近最少使用策略 LRU(Least Recently Used)
类比
书太多了,太占书房空间了,你要做个大扫除,扔掉一些书籍。
那这个时候,你会选择扔掉哪些书呢
- 最先买的书,扔掉
- 最少看到书,扔掉
- 最近最少看的书,扔掉
最常见的链表结构
- 单链表
- 双向链表
- 循环链表
数组和链表的区别
1) 从底层的存储结构上来看
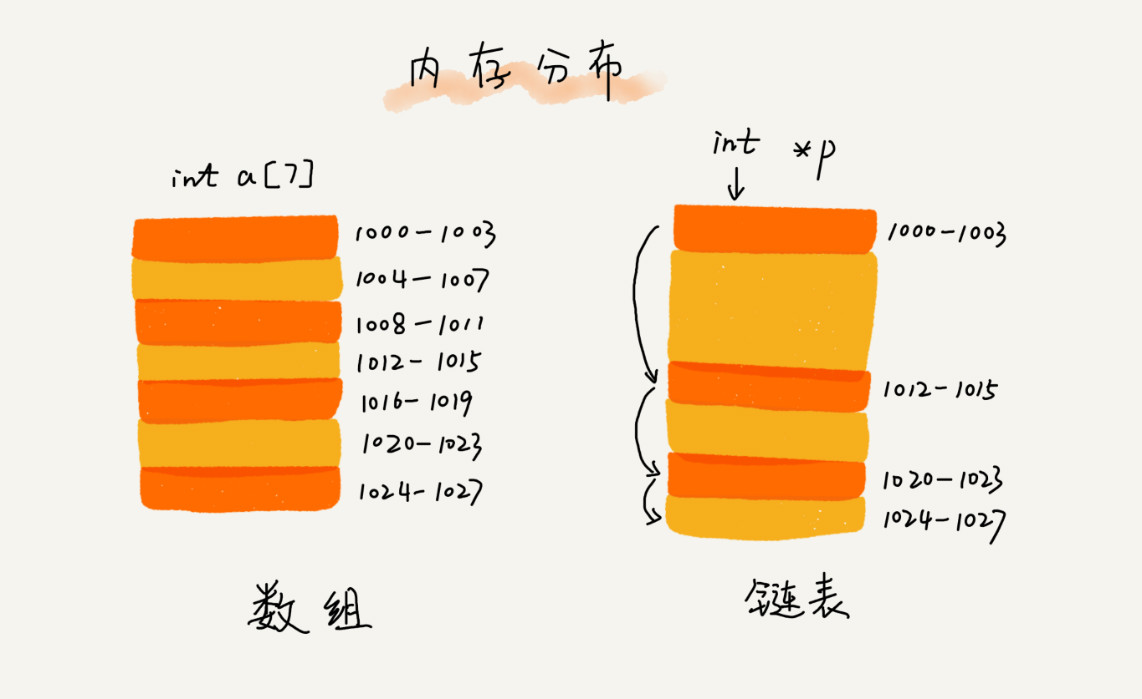
数组需要一块连续的内存空间来存储,对内存的要求比较高
如果我们申请一个 100MB 大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于 100MB,仍然会申请失败
链表恰恰相反,它并不需要一块连续的内存空间
它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请的是 100MB 大小的链表,根本不会有问题
最常见的链表结构
- 单链表
- 链表 通过“指针”将一组零散的内存块串联起来使用
- 把这儿的内存块称为链表的“结点”
- 为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址
- 把这个记录下个结点地址的指针叫作后继指针 next
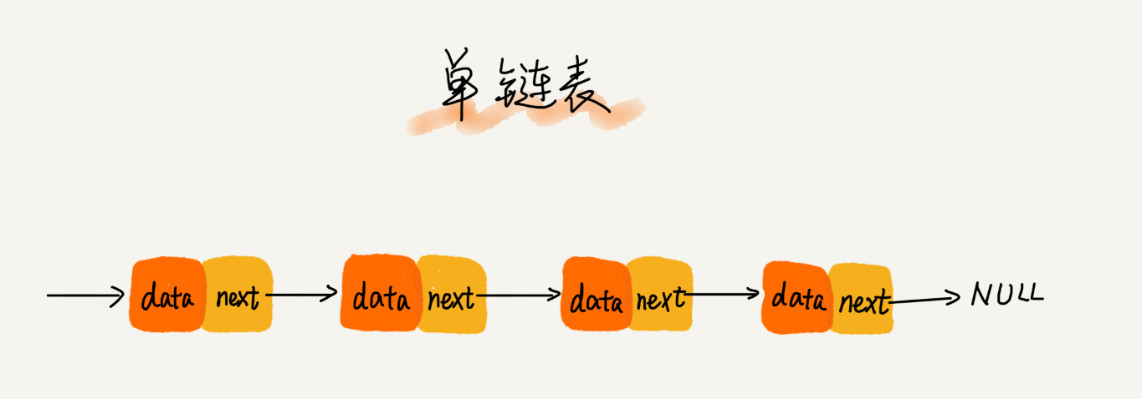
两个结点是比较特殊的:
头结点:第一个结点
- 用来记录链表的基地址
- 有了头结点,我们就可以遍历得到整条链表
尾结点:最后一个结点
尾结点的 next 指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点
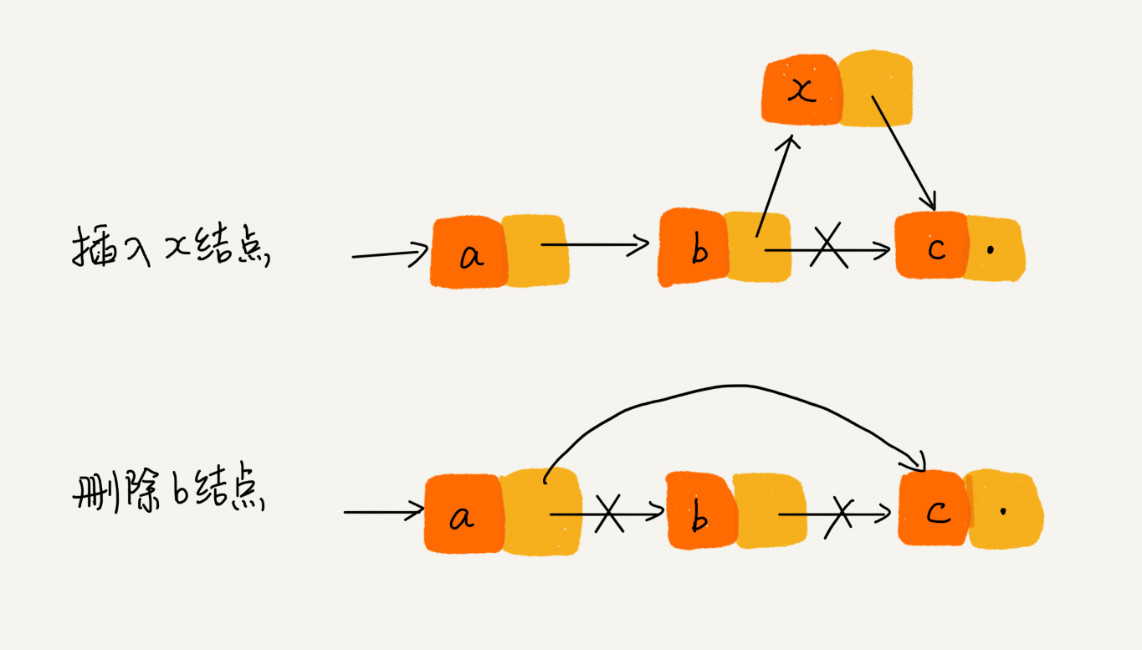
优势:
- 在进行数组的插入、删除操作时,为了保持内存数据的连续性,需要做大量的数据搬移,所以时间复杂度是 O(n)。
- 而在链表中插入或者删除一个数据,只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1),因为链表的存储空间本身就不是连续的。
所以,在链表中插入和删除一个数据是非常快速的
劣势:
要想 随机访问第 k 个元素,就没有数组那么高效
- 因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址
- 而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点
可以把链表想象成一个队伍,队伍中的每个人都只知道自己后面的人是谁,所以当我们希望知道排在第 k 位的人是谁的时候,我们就需要从第一个人开始,一个一个地往下数。
所以,链表随机访问的性能没有数组好,需要 O(n) 的时间复杂度
1
- 双向链表
- 循环链表
4)
5)
6)
1
1
1
1
1
1
1
1
1
1
1
1
1
--------小尾巴
________一个人欣赏-最后一朵颜色的消逝-忠诚于我的是·一颗叫做野的心.决不受人奴役.怒火中生的那一刻·终将结束...

