
Docker第三章:主从操作、分布式存储
mysql_master主从配置
1:新建主服务器容器实例3307
docker run -p 3307:3306 --privileged=true -v /zyt/mysql_master/log:/var/log/mysql -v /zyt/mysql_master/data:/var/lib/mysql -v /zyt/mysql_master/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
2:替换/zyt/mysql_master/conf下的my.cnf文件
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
3:重启docker的主mysql服务,用root权限进入mysql
4:CREATE USER 'slave'@'%' IDENTIFIED BY '123456';——新建slave用户
5:GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';——授权
6:在宿主机目录输入以下
docker run -p 3308:3306 --privileged=true -v /zyt/mysql_slave/log:/var/log/mysql -v /zyt/mysql_slave/data:/var/lib/mysql -v /zyt/mysql_slave/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
7:替换/zyt/mysql_slave/conf下的my.cnf文件
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1
8:重启从mysql的docker容器
9:在主mysql中输入show master status;

10:进到从机的mysql中,输入以下
change master to master_host='宿主机ip', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=1601, master_connect_retry=30;
master_host:主数据库的IP地址;
master_port:主数据库的运行端口;
master_user:在主数据库创建的用于同步数据的用户账号;
master_password:在主数据库创建的用于同步数据的用户密码;
master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
master_connect_retry:连接失败重试的时间间隔,单位为秒。
11:从mysql中开启主从同步
start slave;
show slave status \G;
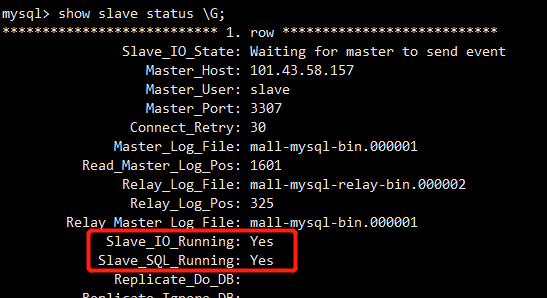
12:在主机上经过一连串组合拳操作后,发觉从机也有数据
分布式存储
心跳包:在客户端和服务器间定时通知对方自己状态的一个自己定义的命令字,按照一定的时间间隔发送
例如有亿条缓存需要存储,则需要使用到分布式存储。通常分布式存储有以下几种方法。
哈希取模算法(适合小厂)
亿条数据就是亿条k,v,假设有三台机器构成一个集群,用户每次读写都是根据公式:hash(key)%N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上
优点
简单粗暴,直接有效。只需要预估好数据规划好节点。就能保证一段时间的数据支撑。使用HASH算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求,起到负载均衡+分而治之的作用。
缺点
原来规划后的节点,进行扩容或者缩容就比较麻烦了。不管是扩容还是缩容,每次数据变更导致几点有变动,映射关系需要重新进行计算。在服务器个数固定不变的时候没问题。如果需要弹性扩容或者故障停机的情况下,原来的取模公式就会发生变化。此时地址经过某个redis机器宕机了。由于机器总数量发生了变化,会导致hash取余全部数据重新洗牌。
一致性哈希算法(适合中厂)
为了在节点数目发生改变时尽可能少的迁移数据,将所有的存储节点排列在首尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点
步骤
1:算法构建一致性哈希环
一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形)

整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到232-1,也就是说0点左侧的第一个点代表232-1, 0和232-1在零点中方向重合,我们把这个由232个点组成的圆环称为Hash环。为什么hash环是对2^32取模?
因为IPV4的地址是由4组8位二进制数组成,所以用2^32可以保证每个IP地址会有唯一的映射
2:服务器IP节点映射
下一步将各个服务器使用Hash(ip)进行一次哈希,这样每台机器就能确定其在哈希环上的位置。
3:key落到服务器的落键规则
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:

最终,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻节点,对其它节点无影响
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果
哈希槽算法(适合大厂)
为了解决一致性哈希算法的数据倾斜问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于是节点上放的是槽,槽里放的是数据

Redis Cluser采用虚拟槽分区,所有的键根据哈希函数映射到0~16383个整数槽内。
- 哈希槽计算公式:slot=CRC16(key)& 16384。集群中的每个键都属于这16384个哈希槽中的一个。
举例:假如当前集群有3个节点,槽默认是平均分的:
节点 A (6381)包含 0 到 5499号哈希槽。
节点 B (6382)包含5500 到 10999 号哈希槽。
节点 C (6383)包含11000 到 16383号哈希槽。
这种结构很方便添加或者删除节点,比如如果我想新添加个节点D,,我需要从节点 A、B、C中得部分槽到D上。
如果我像移除节点A,需要将A中得槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可。
由于哈希槽从一个节点将移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量,都不会造成集群不可用的状态。
为什么Redis集群的最大槽数是16384?
https://blog.csdn.net/g6U8W7p06dCO99fQ3/article/details/120386715
Docker配置redis集群——自动启动哨兵模式
1:docker run -d --name redis-node-1 --net host --privileged=true -v /zyt/redis-cluster/redis-node-1:/data 4b1123a829a1 --cluster-enabled yes --appendonly yes --port 6379——同理整出80,81,89,90,91六个端口对应的redis服务
2:docker exec -it redis-node-1 /bin/bash
3:redis-cli --cluster create 10.0.16.8:6379 10.0.16.8:6380 10.0.16.8:6381 10.0.16.8:6389 10.0.16.8:6390 10.0.16.8:6391 --cluster-replicas 1——cluster-replicas 1代表对每一个master创建一个slave节点

4:redis-cli -p 6379——进入第一台主机的redis-cli客户端
5:cluster info——确认集群情况
6:cluster nodes——确认节点情况
集群读写
1:redis-cli -p 6379 -c——进入第一台主机,多加了-c
2:set k1 v1——结果图如下

查看集群信息
1:redis-cli --cluster check 10.0.16.8:6379
主从扩容——现情况从3主3从扩容至4主4从
1:docker run -d --name redis-node-7 --net host --privileged=true -v /zyt/redis-cluster/redis-node-7:/data 4b1123a829a1 --cluster-enabled yes --appendonly yes --port 6382——同理再生成一个redis-node-8容器
2:docker exec -it redis-node-7 /bin/bash
3:redis-cli --cluster add-node 10.0.16.8:6382 10.0.16.8:6379——得知6382还没有分配槽位

4:redis-cli --cluster reshard 10.0.16.8:6380——16384/4 = 4096,第二行输入6382容器的ID号,而后输入all

5:redis-cli --cluster check 10.0.16.8:6379——查看集群信息可以知道之前三个主机各分了部分槽位给四号主机

6:redis-cli --cluster add-node 10.0.16.8:6392 10.0.16.8:6382 --cluster-slave --cluster-master-id 8adc4671396d9f52b187ded3a48ca2ac7c0e1c68——最后的参数是6382的ID,该命令加入6382的从机
7:redis-cli --cluster check 10.0.16.8:6379——确认从机添加成功

主从缩容——将4主4从缩容为3主3从
1:redis-cli --cluster check 10.0.16.8:6379——获得6392与6382的ID
2:redis-cli --cluster del-node 10.0.16.8:6392 b030d6d1c17404fc73ab6476b63b4a966c5e27c8——删除从机6392
3:redis-cli --cluster check 10.0.16.8:6379——检查集群情况,确认6392被删除
4:redis-cli --cluster reshard 10.0.16.8:6379——重新分配hash槽
1:4096
2:f0bb7338862bd968e26f9f6d3ec717476a7eb674——接收回收的hash槽的master容器ID
3:8adc4671396d9f52b187ded3a48ca2ac7c0e1c68——要回收的hash槽的master容器ID
4:done
5:yes
5:redis-cli --cluster check 10.0.16.8:6379——检查集群情况,确认6382的hash槽被回收
6:redis-cli --cluster del-node 10.0.16.8:6382 8adc4671396d9f52b187ded3a48ca2ac7c0e1c68——删除6382节点
7:redis-cli --cluster check 10.0.16.8:6379——确认缩容成功

