Redis学习
Redis使用场景
最新N个数据 通过List实现按自然时间排序的数据
排行榜,Top N 利用zset(有序集合)
时效性的数据,比如手机验证码 Expire过期
计数器、秒杀 原子性,自增方法INCR、DECR
去除大量数据中的重复数据 利用Set集合
构建队列 利用list集合
发布订阅消息系统 pub/sub模式
独立访客、独立IP等需去重数据 HyperLogLog
Redis安装目录工具:/usr/local/bin
redis-benchmark:性能测试工具
redis-check-aof:修复有问题的AOF工具
redis-check-dump:修复有问题的dump.rdb文件
redis-sentinel:Redis集群使用
redis-server:Redis服务器启动命令
redis-cli:客户端,操作入口
数据类型
字符串
当字符串长度小于1M时,扩容都是加倍现有空间;如果超过1M,扩容时只会多扩1M的空间,需要注意的是字符串最大长度为512M

列表
底层是双向链表,通过索引下标的操作中间的节点性能会比较差,列表元素较少时会使用一块连续的内存存储,这个结构是ziplist(压缩列表);当数据量比较多的时候会改成quicklist

zset
没有重复元素的字符串集合,不同的是有序集合的每个成员都关联了一个评分,这个评分被用来按照从最低分到最高分的方式排序集合中的成员
HyperLogLog
什么是基数,即比如数据集{1,2,3,4,5}基数为5。HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身
Geographic
该类型对应元素的2维坐标,在地图上就是经纬度
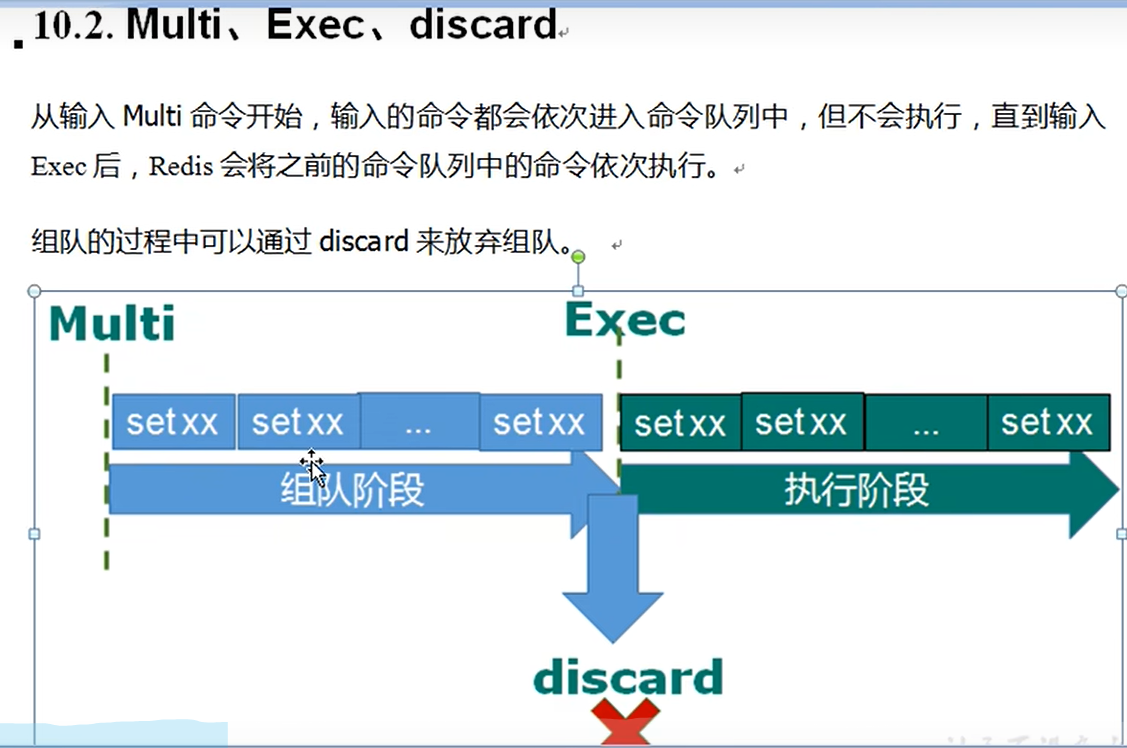
Redis事务
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其它客户端发来的命令请求所打断。
组队中某个命令出现了报告错误,执行时整个队列都会被取消;执行阶段某个命令执行错误,其它命令仍旧会照常进行
悲观锁——操作之前都会上锁
乐观锁——每次拿数据时认为别人不会修改,不会上锁;更新时,会判断版本号,如果和数据库中版本号一样,则操作;反之不操作。适用于多读的应用类型
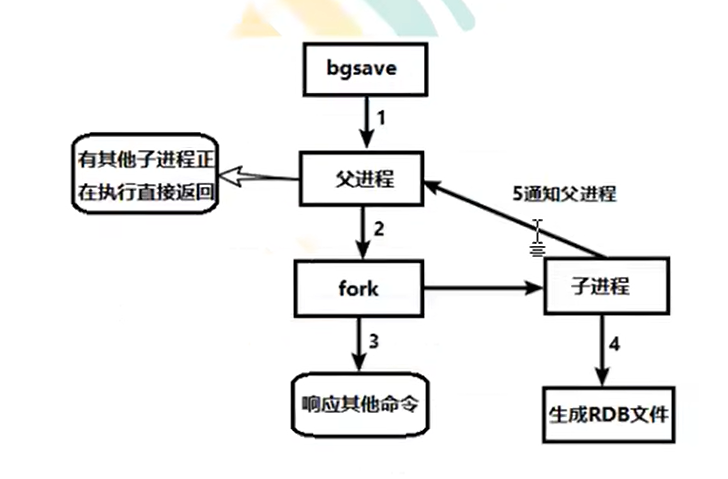
RDB
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程不进行任何IO操作,如果需要进行大规模数据恢复,且对于完整性不敏感,RDB方式更好,缺点是最后一次持久化后的数据可能丢失。
fork
作用是复制一个与当前进程一样的进程,新进程的所有数据都和原进程一样,但是是全新的进程,并作为原进程的子进程存在
优势
适合大规模的数据恢复;对数据完整性和一致性要求不高;节省磁盘空间;恢复速度快
劣势
fork时,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑;虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大还是比较消耗性能
AOF
以日志的形式来记录每个写操作,将Redis执行过的写指令记录下来,只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据;与RDB同时开启时,采用AOF方式
AOF持久化流程
客户端请求写命令会被append追加到AOF缓冲区内;
AOF缓冲区根据AOF持久化策略将操作sync同步到磁盘AOF文件中;
AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量

优势
备份机制更稳健,丢失数据概率更低;可读的日志文本,通过操作AOF文件,可以处理误操作
劣势
比起RDB占用更多的磁盘空间;恢复备份速度要慢;每次读写都同步的话,有一定的性能压力;存在个别Bug,造成不能恢复的情况
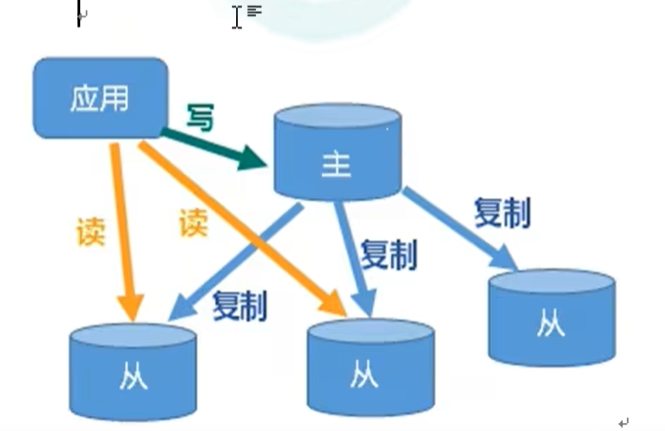
Redis一主多从
具体步骤
// 创建/myredis文件夹,复制redis.conf文件到此处 mkdir /myredis cp /etc/redis.conf /myredis // 修改redis.conf文件的appendonly为no vim /myredis/redis.conf appendonly no // 配置一主两从配置,新建redis6379.conf等文件,并输入以下内容 include /myredis/redis.conf pidfile /var/run/redis_6379.pid port 6379 dbfilename dump6379.rdb replicaof 127.0.0.1 6379 //主机ip与端口,如果不加,则需要执行slaveof ip 端口
masterauth 密码 // 确保没有redis服务后,启动服务;若为云服务器,需要开通云服务器端口权限 redis-server redis6379.conf redis-server redis6380.conf redis-server redis6381.conf // 进入对应redis,看到有slave节点,则表示主从建立成功 redis-cli -p 6379 auth 密码 info replication
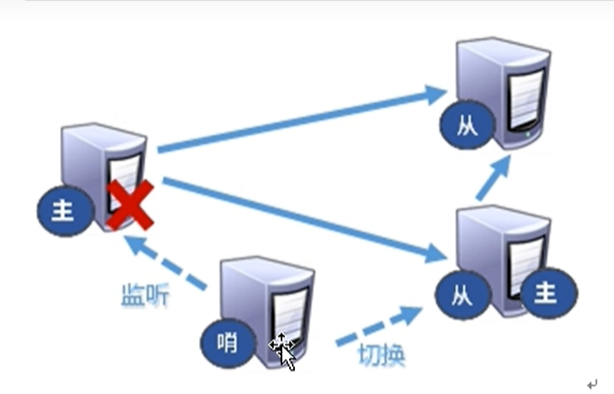
哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
执行步骤
// 调整为一主二仆模式 // /myredis目录下建立sentinel.conf文件,并填写以下内容 sentinel monitor mymaster 127.0.0.1 6379 1 sentinel auth-pass mymaster 密码 执行redis-sentinel sentinel.conf


从log中可以发现6381升级为master,重启后的6379转变为slave
复制延时
由于所有写操作都是在master上操作,然后同步更新到Slave上,所以从master同步到slave机器上有一定延时。系统繁忙与机器增加上,延时会更严重。
故障恢复
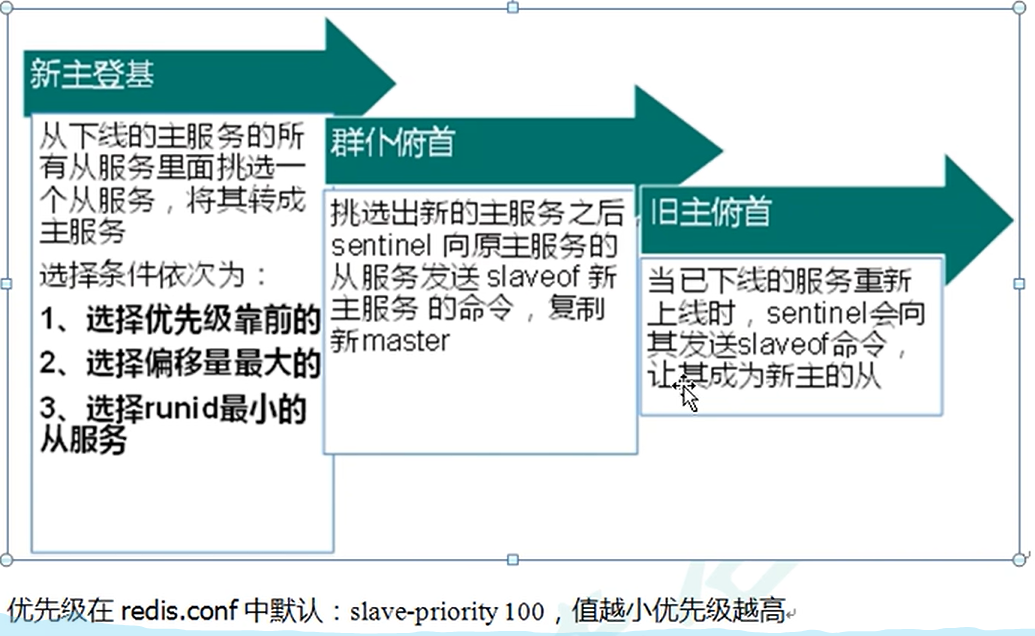
集群
Redis集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数的1/N。Redis集群通过分区来提供一定程度的可用性:即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求
执行步骤(本地用6个redis服务器搭建集群,分别是3个主从服务器)
// cd进/myredis目录,删除dump文件以及redis6380、6381.conf文件,并修改redis6379.conf include /myredis/redis.conf pidfile "/var/run/redis_6379.pid" port 6379 dbfilename "dump6379.rdb" masterauth 123456 cluster-enabled yes cluster-config-file nodes-6379.conf cluster-node-timeout 15000 // 复制redis6379.conf为6380、6381、6389、6390、6391.conf,打开vim输入以下内容更改对应配置 :%s/6379/6380 // --cluster-replicas 1代表为每个主节点分配一个从节点 redis-cli --cluster create --cluster-replicas 1 10.0.16.8:6379 10.0.16.8:6380 10.0.16.8:6381 10.0.16.8:6389 10.0.16.8:6390 10.0.16.8:6391 -a 123456 // 一个Redis集群包含16384插槽,数据库中每个键都属于这其中的一个。 All 16384 slots covered // -c代表集群连接 redis-cli -c -p 6379 // 通过cluster nodes查看集群信息 cluster nodes
一个集群至少要3个节点,分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。


缓存穿透
出现的原因
redis查不到数据库
出现很多非正常的url访问
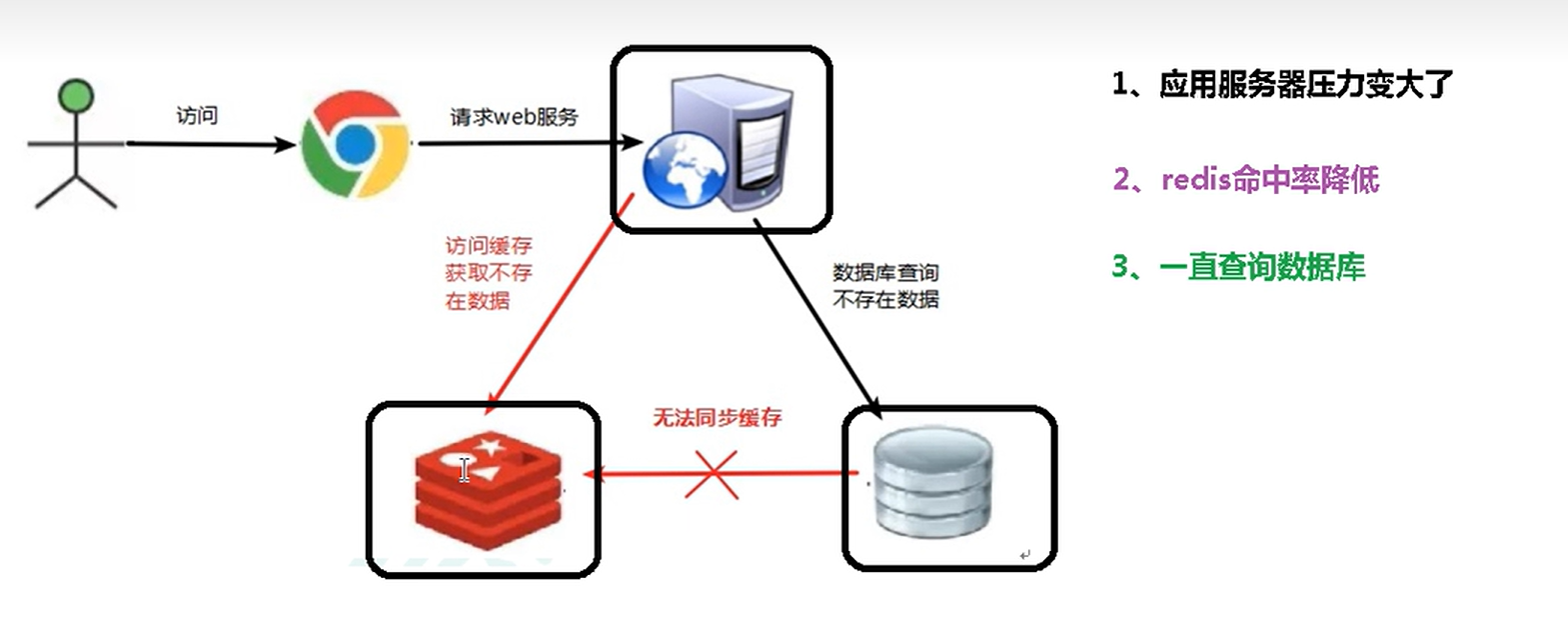
解决方法


缓存击穿
产生原因
redis某个key过期了,但仍在大量使用这个key
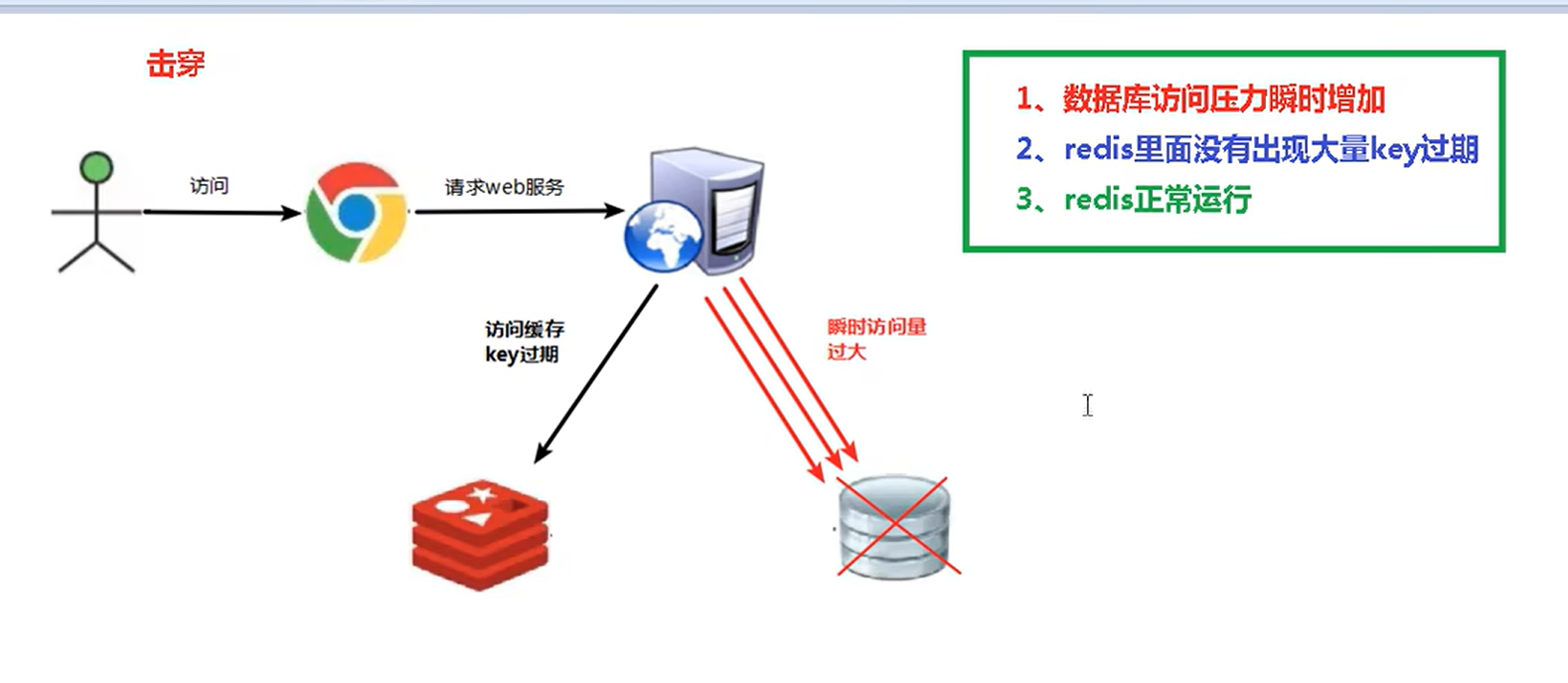
解决方案

缓存雪崩
产生原因
在极少的时间段内,查询大量key的集中过期情况
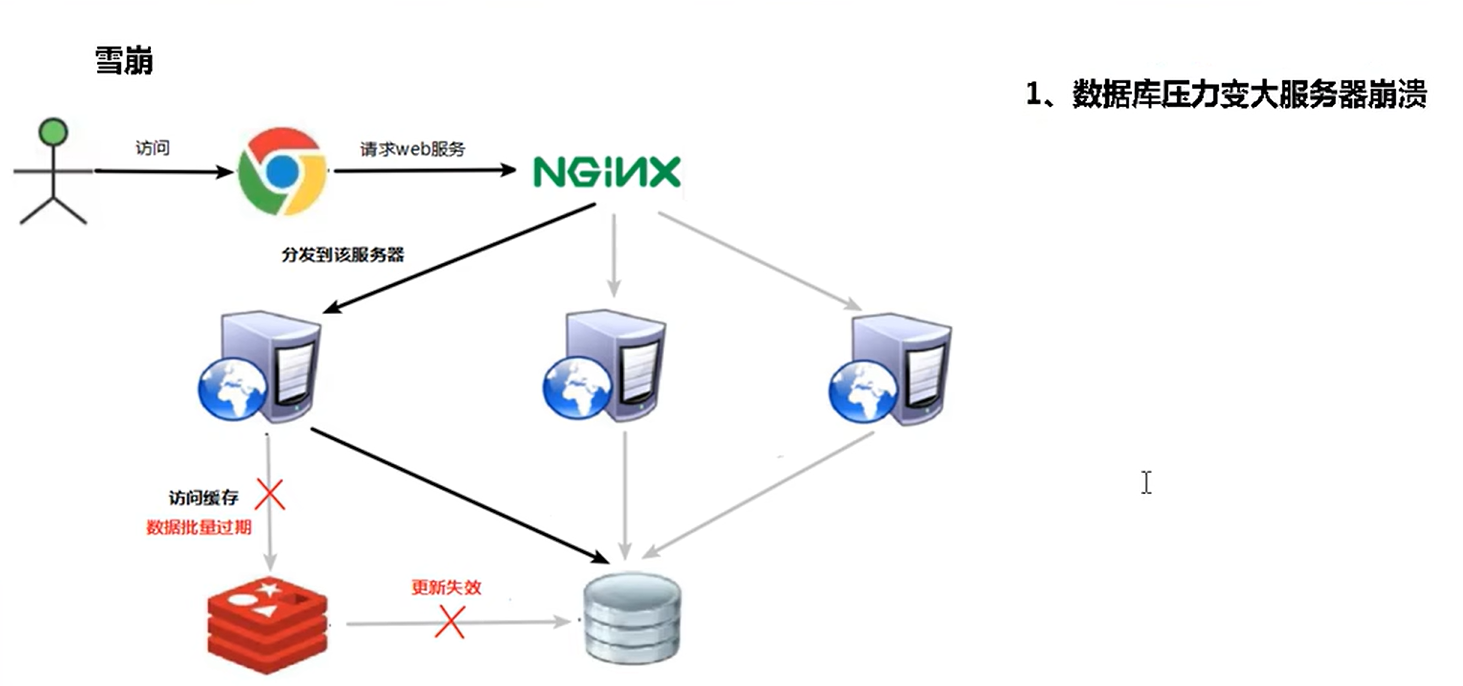
解决方案


分布式锁
使用前提

性能最高:redis
最可靠:zookeeper
上锁同时设置过期时间
set users 10 nx ex 12

Redis6新特性
ACL简介
Redis ACL是Access Control List的缩写,该功能允许根据可以执行的命令和可以访问的键来限制某些连接。

IO多线程
IO多线程其实指客户端交互部分的网络IO交互处理模块多线程,而非执行命令多线程。
多线程IO默认不开启,需要在配置文件中配置。
io-threads-do-reads yes
io-threads 4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号