MySQL进阶
insert into select from
insert into tableName2(column_name1,column_name2,....) select column_name1,column_name2,.... from tableName1;
注意:两个表必须存在,而且表的列字段类型也要匹配,注意与插入语句insert into values 的区别。
select into from
select column_name1,column_name2,.... into tableName2 from tableName1;
注意:tableName2 表可以不存在,会在执行的过程中自动创建。但MySQL中不支持此语句。可选择下面这句替代。
CREATE TABLE tableName2( SELECT [column_name1,column_name2,....] FROM table1);
查询执行顺序
from > where > group(含聚合) > having > order > select;
Where与having
where在分组前对数据进行过滤;having在分组后
where后面不能使用聚合函数;having后面能使用聚合函数
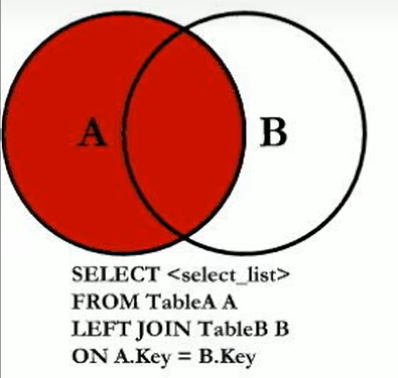
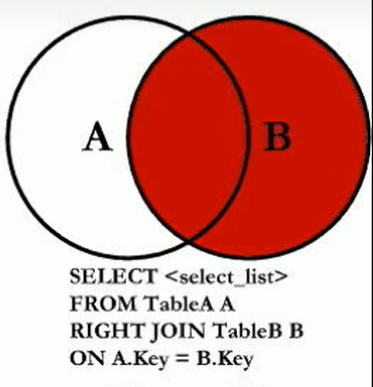
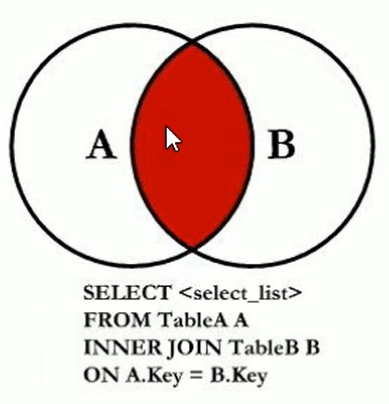
7个SQL JOINS
左连接
右连接
左连接去除内连接

内连接
右连接去除内连接

全连接

全连接去除内连接
索引
帮助SQL搞笑获取数据的数据结构,平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引
索引优势
提高数据检索效率,降低数据库的IO成本
通过索引列对数据进行排序,降低数据排序成本,降低CPU消耗
索引劣势
索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也占空间
索引会降低表更新的速度,如对标的INSERT、UPDATE、DELETE操作。因为更新表时,还要保存索引文件每次更新添加了索引列的字段
哪些情况需要索引
1:主键自动建立唯一索引
2:频繁作为查询条件的字段应该作为索引
3:查询中与其他表关联的字段,外键关系建立索引
4:频繁更新的字段不适合创建索引
5:查询中排序到的字段,排序字段若通过索引去访问将大大提高排序速度
6:查询中统计或分组字段
哪些情况不需要建立索引
1:表记录太少
2:经常增删改的表
3:数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引
explain
id
查询的序列号,包含一组数据,表示查询中执行select子句或操作表的顺序
三种情况:
id相同,执行顺序由上至下;
id不同,如果是子查询,id的序号会增加,id值越大优先级越高,越先被执行
id相同不同,同时存在
select_type

type
与查询优化息息相关,从最好到最差依次是,最少要达到range级别
system>const>eq_ref>ref>range>index>ALL

possible_keys和key

key_len
作用是看索引哪些字段被用到,具体来说是看联合索引。一般来说,key_len的值=字段长度*这个类型的字段所占空间,如以下例子

ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
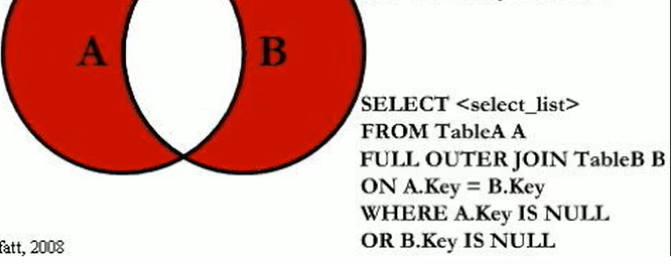
extra
using filesort——说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MYSQL中无法利用索引完成的排序操作称为“文件排序”
using temporary——使用了临时表保存中间结果,MYSQL在对查询结果排序时使用临时表。常见于order by和group by
using index——表示相应的select操作中使用了覆盖索引,避免访问了表的数据行,效率不错!如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。如果要使用覆盖索引,一定要注意select列表中只取出需要的列,不可select *
Join语句的优化

索引失效
最佳左前缀法则——如果索引了多列,要遵守最佳左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列

不在索引列上做任何操作——如计算、函数、类型转换,会导致索引失效而转向全表扫描

存储引擎不能使用索引中范围条件右边的列

尽量使用覆盖索引——只访问索引的查询(索引列和查询列一致),减少select *

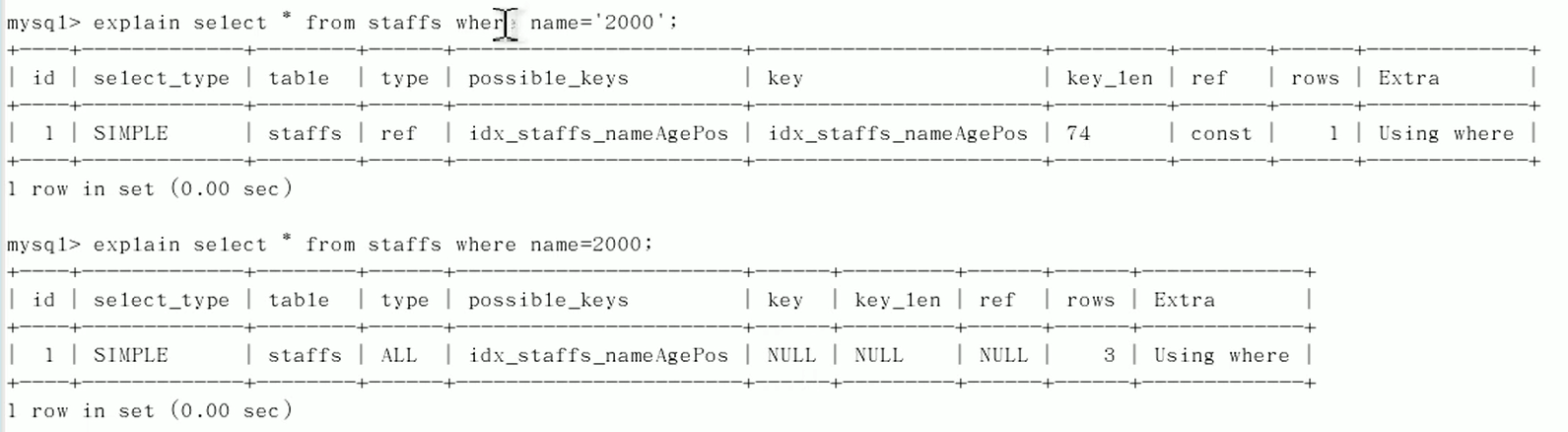
mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
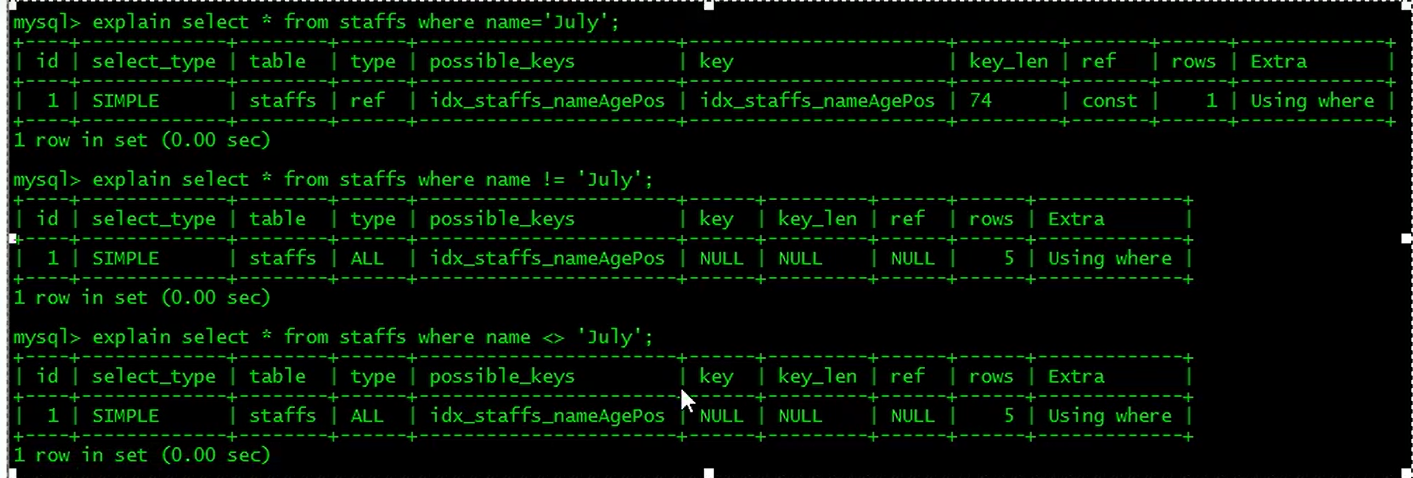
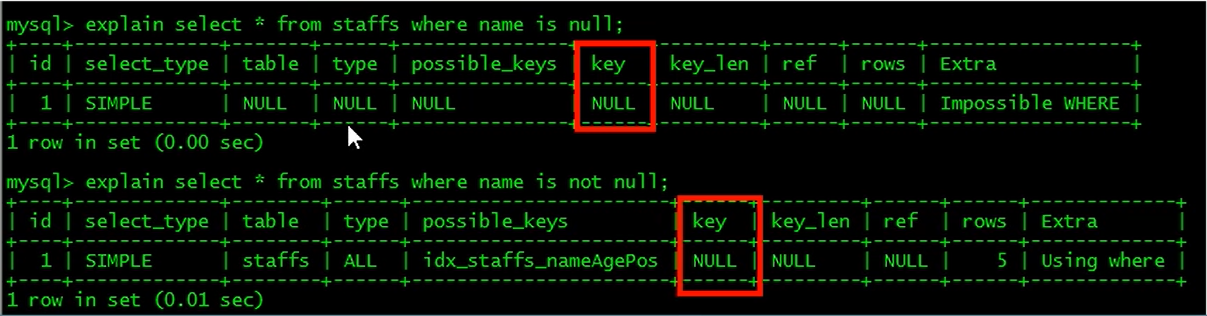
is null,is not null也无法使用索引
like以通配符开头(‘%abc...')mysql索引失效会变成全表扫描的操作
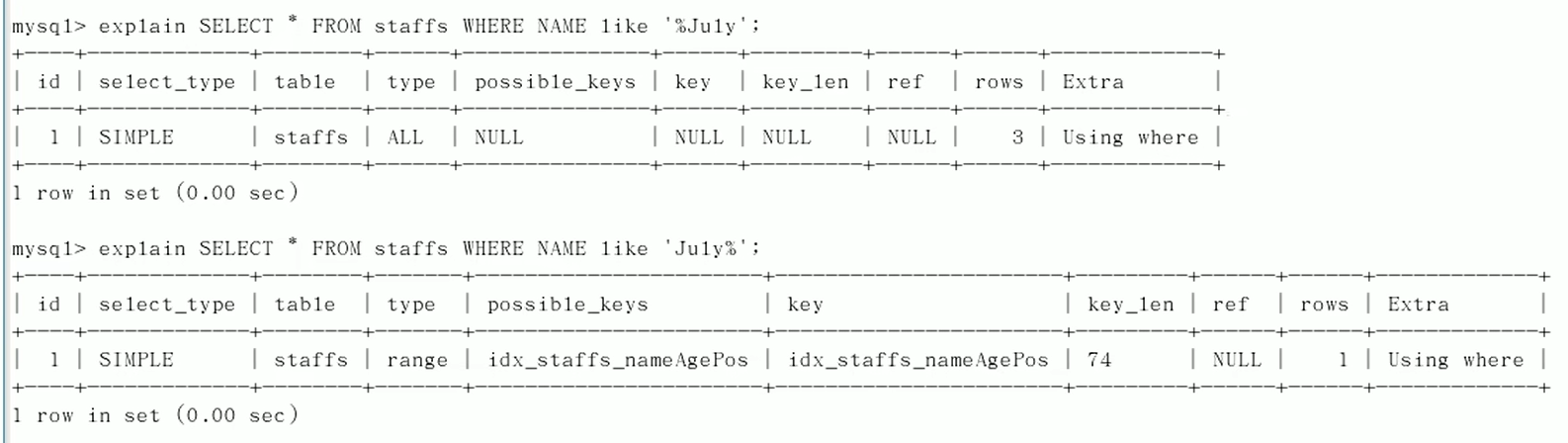
字符串不加单引号索引失效
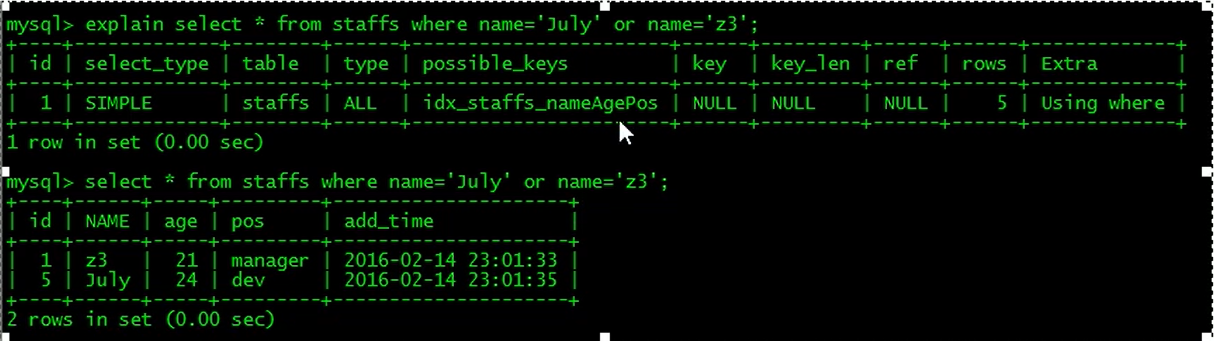
少用or,用它来连接时会索引失效
索引优化——一般性建议

SQL分析步骤

小表驱动大表——即小的数据集驱动大的数据集
如图中B表为小表
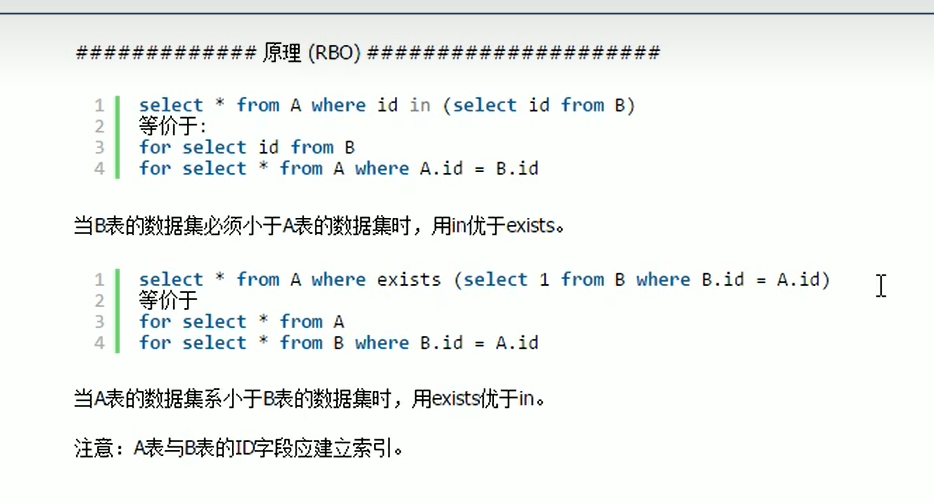
exist表达式

OrderBy优化
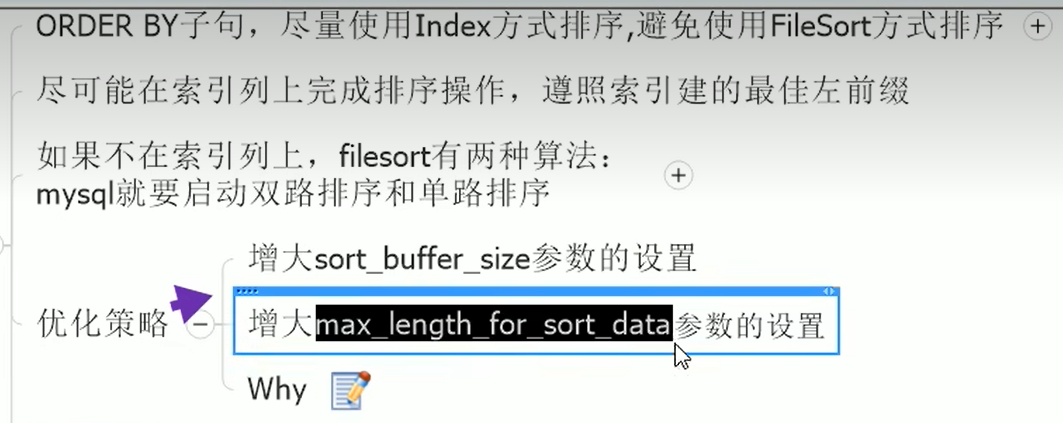
提高OrderBy速度

OrderBy例子

MySQL慢查询
默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数,如果不是调优需要的话,不建议启动该参数。使用set global slow_query_log = 1开启,如果要永久生效,需要修改配置文件

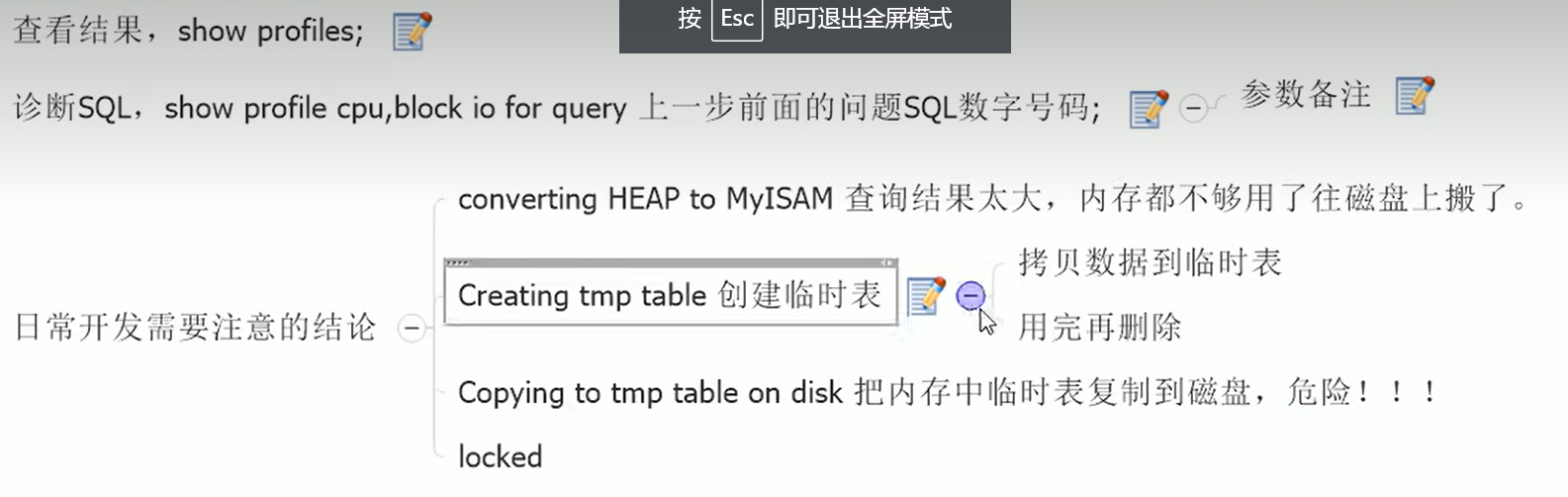
Show Profile
是MySQL提供可以用来分析当前会话中语句执行的资源消耗情况,默认情况下,参数处于关闭状态,并保存最近15次运行结果
MySQL读写锁
读锁会阻塞写,但是不会阻塞读;写锁会把读和写都阻塞
事务
原子性:事务时一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行
一致性:在事务开始和完成时,数据都必须保持一致状态,这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构也都必须是正确的
隔离性:数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的”独立“环境执行,这意味着事务处理过程中的中间状态对外部是不可见的
持久性:事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持
更新丢失
当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其它事务的存在,就会发生丢失更新问题——最后的更新覆盖了由其他事务所做的更新
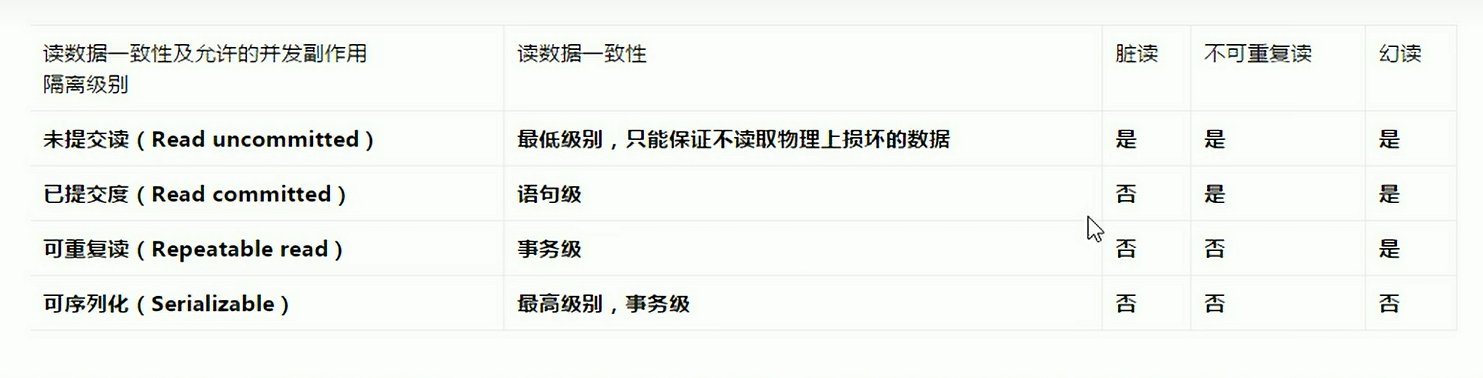
脏读
事务A读取到了事务B已修改但尚未提交的数据,还在这个数据基础上做了操作。此时如果事务B回滚,A读取的数据无效,不符合一致性原则
幻读
与脏读类似,幻读是事务B里面新增了数据
不可重复读
事务A读取到了B已经提交的修改数据,不符合隔离性
事务隔离机制