

Java集合
树
二叉树:永远只有一个根节点,是每个结点不超过2个节点的树
查找二叉树、排序二叉树:小的左边,大的右边,但是可能树会很高,性能会变差。为了做排序和搜索会进行左旋和右旋实现平衡查找二叉树,让树的高度不大于1
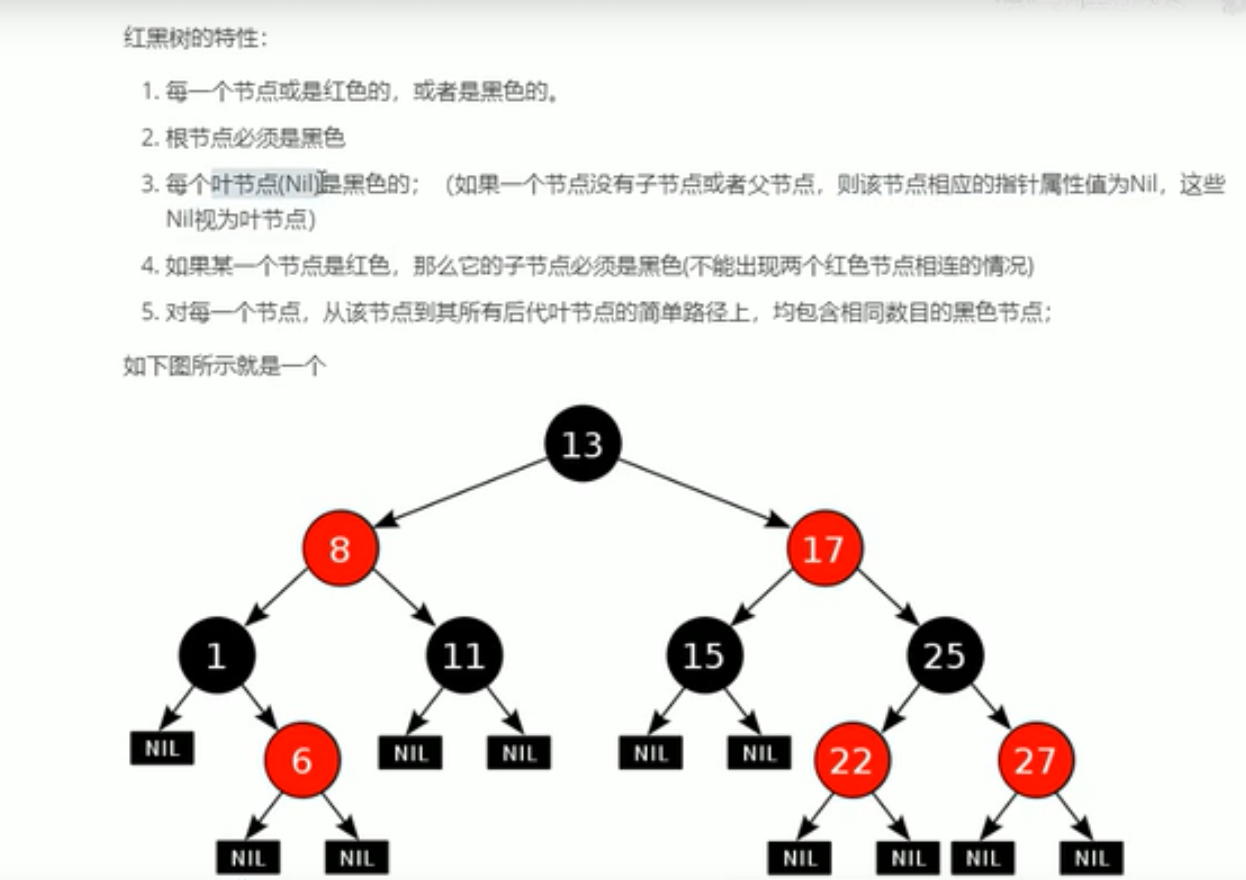
红黑树
基于红黑规则实现了自平衡的排序二叉树,树尽量的保证到了很矮小,又排好了序,是性能最高的树,增删改查性能都好!!!
集合是一个大小可变的容器,其中的每个数据称为一个元素。
集合的特点——类型可以不确定,大小可以不固定;数组的特点——类型和长度一旦定义出来就都固定了。
Java中集合的代表:Collection,体系图如下:

Set系列集合:添加的元素是无序,不重复,无索引的
-- HashSet:添加的元素是无序,不重复,无索引的
-- LinkedHashSet:添加的元素是有序,不重复,无索引的——每个元素会额外带一个链来维护添加顺序
-- TreeSet:不重复,无索引,按照大小默认升序排序
TreeSet自排序:
-- 有值特性的元素直接可以升序排序(浮点型、整形)
-- 字符串类型的元素会按照首字符的编号排序
-- 对于自定义的引用类型,TreeSet默认无法排序,执行的时候直接报错,因为它不知道排序规则
自定义的引用数据类型排序实现(如果两规则都存在,默认使用方法2集合规则):
1:直接为对象的类实现比较器规则接口Comparable,重写比较方法(拓展方式)
public class Employee implements Comparable<Employee> { private String name; private double salary; // 比较者this,被比较者o // 比较者大,返回正数;反之返回负数;相等返回0 @Override public int compareTo (Employee o) { return this.age > o.age; // 升序 } }
2:直接为集合设置比较器Comparator对象,重写比较方法
//Employee类取自上方 Set<Employee> employees1 = new TreeSet<>(new Comparator<Employee>() { @Override public int compare(Employee o1, Employee o2) { // o1比较者, o2被比较者 // 比较者更大,返回正数;反之返回负数;相等返回0 return o1.getAge() - o2.getAge(); } }
Set集合添去重复的原因:
对于有值特性的,Set集合可以直接判断进行去重复;
对于引用数据类型的类对象,Set集合按照如下流程进行是否重复判断:
1:Set集合会让两两对象,先调用自己的hashCode()方法得到彼此的哈希值(所谓的内存地址)
2:比较两个对象的哈希值是否相同,如果不同则直接认为对象不重复
3:如果哈希值相同,会继续让两个对象进行equals比较内容是否相同,如果相同认为重复,不同则认为不重复
4:如果希望Set集合认为两对象只要内容一样就重复了,必须重写hashCode和equals方法
Set系列集合添加元素无序的根本原因是因为底层采用了哈希表存储元素
JDK1.8之前:哈希表 = 数组 + 链表 + (哈希算法)
JDK1.8之后:哈希表 = 数组 + 链表 + 红黑树 + (哈希算法)
当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间
哈希算法:
Set<String> sets = new HashSet<>(); set.add("Mybatis"); set.add("Java"); sets.add("Java"); sets.add("MySQL"); sets.add("MySQL"); sets.add("Spring");
1:先获取元素对象的哈希值,MySQL 60001 dlei 601
2:让当前对象的哈希值对底层数组长度求余 60001%6 = 1 601%6 = 1
3:求余的结果作为该对象元素在底层数组的索引位置
4:把该对象元素存入到该索引位置,如图

总结:增删改查性能很好,但是它是无序不重复的,如果不在意可以使用
List系列集合:添加的元素是有序,可重复,有索引,遍历方式相较Collection集合多了for循环,如for(int i = 0; i < list.size(); i++)
-- ArrayList:添加的元素是有序,可重复,有索引的
-- LinekdList:添加的元素是有序,可重复,有索引的
ArrayList:底层基于数组存储,查询快,增删慢
LinkedList:底层基于链表,查询慢,增删快;支持双链表,定位前后速度非常快,增删前后的速度最快
总结:图片补充为经常要首尾操作元素的情况
Collection集合的遍历有三种:
1:迭代器
2:foreach(增强for循环)
3:JDK1.8开始之后的新技术Lambda表达式
Collection<String> lists = new ArrayList<>(); lists.add("za"); lists.add("ds"); //迭代器遍历 Iterator<String>it = lists.iterator(); while(it.hasNext()) { String ele = it.next(); System.out.println(ele); } //foreach遍历 for(String ele: lists){ System.out.println(ele); } //lambda循环 lists.forEach(s -> { System.out.println(s); })
Collections工具类——常用API
public static <T> boolean addAll(Collection<? super T> c, T... elements) // 给集合对象批量增加元素
public static void shuffle(List<?> list) // 打乱集合顺序
public static <T> void sort(List<T> list) //将集合元素按照默认顺序排序
public static <T> void sort(List<T> list, Comparator <? super T>) // 将集合元素按照规定顺序排序
Map集合
Collection是单值体系,Map集合是另一个集合体系

Map集合特点:
1:由键决定
2:键是无序,不重复,无索引的
3:值无要求
4:键值对都可以为null
HashMap:键无序,不重复,无索引,值不做要求,线程不安全
LinkedHashMap:键有序,不重复,无索引,值不做要求
Map集合常用API:
public V put(K key, V value) // 把指定的键与指定的值添加到Map集合中
public V remote(Object key) // 把指定的键值对元素在Map集合中删除,返回被删除元素
public V get(Object key) // 根据指定的键,在Map集合中获取对应的值
public set<K> keySet() // 获取Map集合中所有的键,存储到Set集合中
public set<Map.Entry<K, V>> entrySet() // 获取到Map集合中所有的键值对对象的集合(Set集合)
public boolean containKey(Object key) // 判断该集合中是否有此键
Map集合遍历:
1:先获取Map集合的全部键的Set集合
2:遍历键的Set集合,然后通过键找值
3:JDK1.8后的新技术:Lambda表达式
Map<String, Integer> maps = new HashMap<>(); maps.put(xxx, xxx); // 1:键找值方式遍历 // 获取当前Map集合的全部键的集合 Set<String> keys = maps.keySet(); for (String key: keys) { Integer value = maps.get(key); System.out.println(key + "=" + value); } // 2:键值对方式遍历,更加面向对象方式,代码复杂 // 键值对想法键值当成一个整体遍历,也就是直接使用foreach遍历 Set<Map.Entry<String, Integer>> entries = maps.entrySet(); for (Map.Entry<String, Integer> entry: entries) { String key = entry.getKey(); Integer value = entry.getValue(); } // 3.JDK1.8之后的新技术:Lambda表达式 maps.forEach((k, v) -> { System.out.println( k + "=>" + v); });
Map集合存储自定义类型
Map集合的键和值都可以存储自定义类型
如果希望Map集合认为键的元素内容一样就重复了,可以重写hashCode()和equals方法
TreeMap集合
TreeMap集合按照键是可排序不重复的键值对集合(默认升序)
TreeMap集合按照键排序的特点与TreeSet是完全一样的
