《现代操作系统》第4章——文件系统
《现代操作系统》第 4 章——文件系统
就像操作系统提取处理器的概念来建立进程的抽象,以及提取物理存储器的概念来建立进程地址空间的抽象那样,我们可以用一个新的抽象——文件来解决这些问题。进程、地址空间和文件,这些抽象概念均是操作系统中最重要的概念。
文件是对磁盘的建模,而非对 RAM 的建模。事实上,如果能把每个文件看成一个地址空间,那么读者就能理解文件的本质了。
4.1 文件
4.1.1 文件命名
4.1.2 文件结构
Unix 和 Windows 中的文件结构都是字节序列。
还有另外两种结构:记录序列和树,不过现在都不常用。
4.1.3 文件类型
UNIX 和 Windows 中都有普通文件和目录。
普通文件(regular file)是包含用户信息的文件,一般分为 ASCII 文件和二进制文件。ASCII 文件由多行正文组成,每行用回车符号结束,其它系统则用换行符结束。有些系统还同时采用回车符和换行符结束。
UNIX 还有字符特殊文件(character special file)和块特殊文件(block special file)。
4.1.4 文件访问
4.1.5 文件属性
4.1.6 文件操作
4.1.7 使用文件系统调用的一个示例程序
4.2 目录
4.2.1 一级目录系统
4.2.2 层次目录系统
4.2.3 路径名
4.2.4 目录操作
4.3 文件系统的实现
4.3.1 文件系统的布局
文件系统存放在磁盘上。多数磁盘划分为一个或多个分区,每个分区中有一个独立的文件系统。磁盘的 0 号扇区被称为主引导记录(Master Boot Record,MBR),用来引导计算机。在 MBR 的结尾是分区表。该表给出了每个分区的起始和结束地址。表中的第一个分区被标记为活动分区。在计算机被引导时,BIOS 读入并执行 MBR。MBR 做的第一件事时确定活动分区,读入它的第一个块,被称为引导块(boot block),并执行之。引导块中的程序将装载该分区中的操作系统。为统一起见,每个分区都从一个引导块开始,即使它不含一个可启动的操作系统。
之后是超级块(superblock),包含了文件系统的所有关键参数。
接着是文件系统中空闲块的信息,例如,可以用位图或指针列表的形式给出。后面也许跟随的是一个 i 节点,这是一个数据结构数组,每个文件一个,i 节点说明了文件的方方面面。
接着可能是根目录,它存放文件系统目录树的根部。
最后,磁盘其它部分存放了其他所有的目录和文件。
4.3.2 文件的实现
| 实现方式 | 注释 | 优点 | 缺点 |
|---|---|---|---|
| 连续分配 | 1. 实现简单;2. 读操作性能好。 | 1. 运行一段时间之后会产生碎片(和内存的交换一样的原因);2. 为了在创建文件时选择合适的碎片来分配内存,必须在创建文件的时候就确定文件大小,这对用户并不友好。 | |
| 链表分配 | 为每个文件构造磁盘块链表。 | 不会因磁盘碎片浪费空间 | 1. 随机访问速度变慢;2. 链表指针字占用磁盘块,是的磁盘块大小不再是的 2 的整数次幂,降低了系统运行效率。 |
| 文件分配表 | 把链表分配中放在磁盘块中的指针字放到内存里面,组成一张表格,称为文件分配表(File Allocation Table,FAT)。起初用在 MS-DOS 上,现仍被 Windows 完全支持着。 | 1. 尽管仍不支持随机访问,但是遍历链表的时候不再需要与磁盘交互,速度变快了;2. 不论文件多大,都只需要一个记录链表的头结点就可以了。 | 整张表都要放在内存中,对于 1TB 的磁盘和 1KB 大小的块,根据系统对时间和空间的优化方案,这张表要占用 3GB 或许 2.4GB 内存。 |
| i 节点 | 赋予每一个文件一个称为 i 节点(index-node)的数据结构,其中列出了文件属性和文件块的磁盘地址。 |
4.3.3 目录的实现
i 节点
把文件属性放到 i 节点而非目录项中,是更好的做法。这样做,目录项会更短:只有文件名和 i 节点号。
文件名
早些时候的操作系统支持的文件名是固定长度的,例如 MS-DOS 中,文件有 1 ~ 8 个字符的基本名和 1 ~ 3 个字符的可选拓展名,这也是为什么会在 Windows 上看到一些奇怪缩写的目录的原因。在 UNIX V7 中文件名有 1 ~ 14 个字符,包括任何扩展名。但是现代操作系统支持可变长度的长文件名。
当然给每一个目录项以固定的 255 长度的空间来存储长文件名并不是个好方法。
支持长文件名有两种方法:
- 是把文件名存储在行中,即文件名接在固定长度的目录项数据头后面,数据头一般由该目录项的长度、固定格式的数据(所有者、创建者、保护信息以及其它属性)组成,后面的文件名是不定长的。
- 这个方法的缺点是,每当移走一个目录项之后,会留下一个不定长的空隙,而下一个进来的文件项不一定满足这个空隙(和分段一样的缺点)。
- 第二个缺点是目录项可能会分布在多个页面上,在读取文件名时,可能会发生缺页中断。
- 第二种方法是把文件名存储在堆中,即每个目录项拥有固定的长度,而将文件名放置在目录项后的堆中。
- 优点是目录项固定长度,一个目录项被移走之后,另一个目录项总是适合这个空隙的。
- 当然缺页中断还是会发生。
文件查找
可以使用散列表加速文件的查找。
对于大型目录来说,也可以引入高速缓存,将查找结果写到高速缓存中。
4.3.4 共享文件
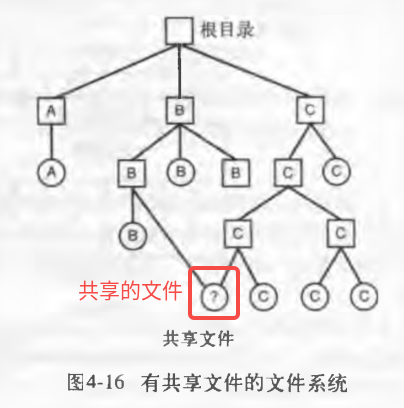
有共享文件的文件系统不再是一棵树,而是一个有向无环图(Directed Acyclic Graph,DAG)。上图中 B 目录和共享文件之间的关系称为一个链接(link)。
考虑这样一种情况,目录 B 和目录 C 共享一个文件,该文件存储在磁盘当中,而目录 B 和目录 C 中存有文件所在的磁盘地址。当一个用户修改了文件之后,例如用户通过目录 C 修改了共享文件,导致共享文件在磁盘上的位置发生了变化,这个变化反应在了目录 C 中。可是其它的用户是不知道这一变化的,这将导致通过目录 B 和目录 C 对同一文件的访问有不一致的结果,这显然是和共享相违背的。有两种方法可以解决这个问题。
- i 节点。磁盘块不保存在目录,而是保存到一个与文件本身相关联的小型数据结构中。目录将指向这个小型数据结构(即 i 节点)。这是 UNIX 所采用的方法。
- i 节点类似 C++中
std::shared_ptr的 control block。 - i 节点中包含文件的所有者、计数。当一个文件被打开时,计数加 1,当文件被关闭时,计数减 1。当计数为 0 时,文件被删除。这样会有一个问题,若计数不为 0,而文件的所有者 C 已经已经不再使用文件了,i 节点中的所有者仍是 C。若涉及到配额一类的问题,C 将继续为该文件付账,直至 B 决定删除它,即文件将一直挂载文件最初的所有者名下,直至计数为零。
- i 节点类似 C++中
- 符号链接。系统新建一个类型为 LINK 的新文件,将其保存在目录 B 下。新的 LINK 文件中包含了它所链接的文件的路径名,当 B 去读取这个文件的时候,操作系统发现要读取的文件是 LINK 文件,则找到该文件所链接的文件的名字,并且去读那个文件。这一方法成为符号连接(symboling linking)。
- LINK 文件类似 C++中的指针。
- 符号链接没有上述的缺点,但是多了一层寻址。例如 B 访问文件,发现文件是 LINK,而 LINK 中记录的路径指向了文件真正的位置,那么操作系统必须读取该路经。这个操作一般是要磁盘操作的。
4.3.5 日志结构文件系统
随着 CPU 的运行速度越来越快,RAM 内存容量越来越大,同时磁盘高速缓存也迅速的增加,进而,不需要磁盘访问,就有可能满足直接来自文件系统高速缓存的很大一部分读请求。从上面的事实可以推断出,未来多数的磁盘访问是写操作。
日志结构文件系统(Log-Structured File System,LFS)是一种文件系统设计,它将所有的文件系统修改作为连续的日志记录存储在磁盘上。这种设计的主要优点是,由于大部分磁盘写操作是顺序的,因此它可以大大提高磁盘写入的性能。
然而,LFS 也有一些缺点。例如,随着时间的推移,文件系统的日志会变得碎片化,这可能会降低读取性能。此外,LFS 需要定期进行垃圾回收以回收被删除或覆盖的旧日志记录的空间,这也会消耗系统资源。
因此,虽然 LFS 在某些特定的应用场景(例如,写入密集型的应用)中仍然有其优势,但在许多常见的用例中,它并没有被广泛采用。现代的文件系统,如 ext4、XFS、Btrfs 等,都没有采用 LFS 的设计。
然而,值得注意的是,一些现代的存储系统,如 SSD 和某些类型的分布式存储系统,已经采用了类似 LFS 的设计。例如,许多 SSD 使用了一种称为闪存转换层(Flash Translation Layer,FTL)的技术,它在某种程度上类似于 LFS。此外,一些分布式存储系统,如 Google 的 Bigtable 和 HBase,也使用了类似 LFS 的设计。
4.3.6 日志文件系统
虽然基于日志结构的文件系统是ー个很吸引人的想法,但是由于它们和现有的文件系统不相匹配,所以还没有被广泛应用。尽管如此,它们内在的一个思想,即面对出错的鲁棒性,却可以被其他文件系统所借鉴。这里的基本想法是保存一个用于记录系统下ー步将要做什么的日志。这样当系统在完成它们即将完成的任务前崩溃时,重新启动后,可以通过査看日志,获取崩溃前计划完成的任务,并完成它们。这样的文件系统被称为日志文件系统,并已经被实际应用。比如微软的 NTFS(New Technology File System)文件系统、Linux ext3 文件系统。
看到这里了,NTFS 和 FAT 有什么差别呢?用自己的话说。
- 磁盘块管理方式不同,NTFS 采用链表来管理空闲磁盘块,FAT 采用位图管理空闲磁盘块。
- NTFS 有日志文件系统,可以在系统崩溃后,恢复之前没有完成的操作。
下面是 GitHub Copilot 的回答:
NTFS(New Technology File System)和 FAT(File Allocation Table)都是文件系统类型,但它们在设计、性能和功能上有一些重要的差异:
- 可靠性和恢复能力:NTFS 比 FAT 更可靠,并且具有更好的恢复能力。NTFS 有日志功能,可以在系统崩溃后恢复文件系统,而 FAT 没有这个功能。
- 安全性:NTFS 支持访问控制列表(ACL)和文件加密(EFS),可以为每个文件和目录设置细的权限。而 FAT 不支持这些安全特性。
- 性能和存储效率:对于大磁盘和大文件,NTFS 的性能和存储效率都比 FAT 要好。FAT32 的文件系统最大可以支持 2TB 的磁盘,但单个文件的大小不能超过 4GB。而 NTFS 没有这些限制。
- 兼容性:FAT 的兼容性更好。几乎所有的操作系统(包括 Windows、Linux、Mac OS 等)都可以读写 FAT 文件系统。而 NTFS 主要在 Windows 系统中使用,虽然现代的 Linux 和 Mac OS 系统可以读取 NTFS,但可能无法完全支持所有的 NTFS 特性。
- 其他特性:NTFS 还支持一些 FAT 不支持的特性,如硬链接、符号链接、卷影复制(VSS)、磁盘配额等。
总的来说,如果你需要一个高性能、高可靠性和高安全性的文件系统,或者需要处理大文件或大磁盘,那么 NTFS 是更好的选择。如果你需要最大的兼容性,或者是在小容量的磁盘(如 USB 闪存驱动器)上使用,那么 FAT 可能是更好的选择。
另外,Ubuntu 20.04 中,根目录的文件系统是 ext4。
考察一个普通且经常发生的操作:移除文件。这个操作在 Linux 中需要三个步骤:
- 在目录中删除文件;
- 释放 i 节点到空闲 i 节点池;
- 将所有磁盘块归还空闲磁盘块池。
这个顺序是不可以被改变的,所有的操作必须被完成,才能保证系统正常工作。因此,日志文件系统先写入一个日志项,列出将要完成的三个动作。然后,日志项被写入磁盘。只有当日志项被写入磁盘时,不同的操作才可以进行。如果这时系统崩溃,系统恢复后,文件系统可以通过检查日志来查看是不是有未完成的操作。如果有,系统可以重新运行所有未完成的操作,直到文件被正确地删除。
为了让日志文件系统工作,被写入日志的操作必须是幂等的,它意味着只要有必要,它们就可以重复执行很多次,并不会带来破坏。例如“更新位表并标记 i 节点 k 或者块 n 是空闲的)”可以重复任意次,是幂等的;“查找一个目录并且删除所有叫 foobar 的项也是幂等的”也是幂等的。而“把从 i 节点 k 新释放的块加入空闲表的末端”不是幂等的,因为它们可能已经被释放并存放在那里了。
另外,一个文件系统可以引入数据库中的原子事务(atomic transaction)的概念。使用这个概念,一组动作要么被完成,要么什么也不做。
4.3.7 虚拟文件系统
为了将不同类型的文件系统整合为一个统一的模式,UNIX 做了一个很认真的尝试,即将多种文件系统整合到一个统一的结构中。例如一个 Linux 系统可以用 ext2 作为根文件系统,ext3 分区装载在/usr 下,另一块采用 ReiserFS 的文件系统装载到/home 下。对于用户来说,只有一个文件系统层级。它们事实上是多种(不相容的)文件系统,对于用户和进程是不可见的。
绝大多数 UNIX 操作系统都使用虚拟文件系统(Virtual File System,VFS)的概念尝试将多种文件系统统一成一个有序的结构。
VFS 对用户进程有一个“上层”接口,它是 POSIX 接口,例如open、read、write和lseek等。
VFS 也有一个对于实际文件系统的“下层”接口。这个接口包含许多功能调用,例如从磁盘中读某个特定的块,把它放在文件系统的告诉缓冲中,并且返回指向它的指针。
VFS 是如何工作的
- 当系统启动时,根文件系统在 VFS 中注册。
- 另外,当装载其他文件系统时,不管在启动时还是在操作过程中,它们也必须在 VFS 中注册。
- 当一个文件系统注册时,它做的最基本工作就是提供一个包含 VFS 所需要的函数地址列表,可以是一个长的调用矢量(表),或者是许多这样的矢量(如果 VFS 需要),每个 VFS 对象一个。因此,只要一个文件系统在 VFS 注册,VFS 就知道如何从它那里读一个块——比如它可以从文件系统提供的矢量中直接调用第 4 个矢量。同样地,VFS 也知道如何执行实际文件系统提供地每一个其他的功能:它只需要调用某个功能(应该翻译成“函数”?),该功能所在的地址在文件系统注册时就提供了。
- 装载文件系统之后就可以使用它了。例如:
open("/usr/include/unistd.h", O_RDONLY);。 - VFS 会解析路径,VFS 看到新的文件系统被装载到了/usr,并且通过搜索已经装载文件系统的超块表来确定它的超块。
- 因为超块中包含……
- 做完这些,它可以找到它所装载的文件的根目录,在那里查找路径
include/unistd.h。 - 然后 VFS 创建一个 v 节点并调用实际的文件系统,以返回所有的在文件 i 节点中的信息。这些信息和其他信息一起复制到 v 节点中(在 RAM 中)。
-
什么是 v 节点?A vnode is an object in kernel memory that speaks the UNIX file interface (open, read, write, close, readdir, etc.). Vnodes can represent files, directories, FIFOs, domain sockets, block devices, character devices.
- v 节点是比 i 节点更高级的抽象,v 节点的
v_data字段就包含 i 节点的信息。The v_data attribute allows a file system to attach a piece of file system specific memory to the vnode. This contains information about the file that is specific to the file system (such as an inode pointer in the case of FFS). - 这些信息中最重要的是指向包含调用 v 节点操作的函数表的指针,比如
read、write和close等。 - 关于 v 节点,可以参考:https://man.openbsd.org/vnode。
-
- v 节点被创建后,为了进程调用,VFS 在文件描述符表中创建一个表项,并且将它指向新的 v 节点(为了简单,文件描述符实际上指向另一个包含当前文件位置和指向 v 节点的指针的数据结构)。
- 最后 VFS 向调用者返回文件描述符,调用者可以用它去读、写或者关闭文件。
- 随后,当进程用文件描述符进行一个读操作,VFS 通过进程表和文件描述符表确定 v 节点的位置,并跟随指针指向函数表(所有这些都是被请求文件所在的实际文件系统中的地址,如何理解?)。这样就调用了处理
read函数,运行在实际文件系统中的代码并得到所请求的块。
4.4 文件系统管理和优化
磁盘管理的细节->数据备份->数据是否一致->开始考虑性能->磁盘碎片整理
4.4.1 磁盘空间管理
1. 块大小
和虚拟内存确认页面大小时是一样的考量。
2. 记录空闲块
和虚拟内存的方法一样。
3. 磁盘配额
文件表中每一项都有一个指向文件所有者配额记录的指针,以便找到不同的限制。
4.4.2 文件系统备份
4.4.3 文件系统的一致性
很多计算机都带有一个实用程序以检验文件系统的一致性,例如 UNIX 有 fsck,Windows 有 scandisk。系统启动时,特别是崩溃之后重新启动,可以运行该程序。
一致性检验分为两种:块的一致性检查和文件的一致性检查。
4.4.4 文件系统性能
高速缓存
构建高速缓存的通常方法是将设备和磁盘地址进行散列操作,然后,在散列表中查找结果。具有相同散列值的块在一个链表中连接在一起,这样,就可以沿着冲突链寻找其他块。
除了散列表中的冲突链以外,还有一个双向链表把所有的块按照使用时间的先后次序链接起来,进来最少使用的块在该链表的前端,而进来最多使用的块在该表的后端。当引用某个块时,该块可以从双向链表中移走,并放置到该表的尾部去。用这种方法,可以维护一种准确的LRU顺序。
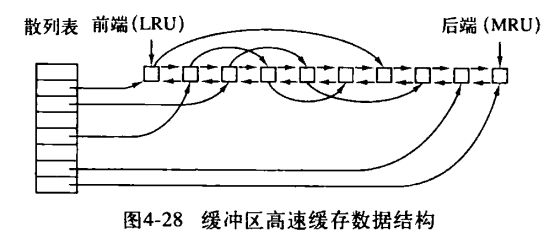
但会有这么一种情况发生,如果一个关键块读进了高速缓存并做过修改,但是没有写回到磁盘,这时,系统崩溃会导致文件系统的不一致。如果把 i 节点块放在 LRU 尾部,在它到达链首并写回磁盘前,有可能需要相当长的一段时间。
可以修改上面提到的数据结构,但这样做并不能很好地解决问题。
在 UNIX 系统中有一个系统调用 sync,它强制性地把全部修改过地块立即写回磁盘。系统启动时,在后台运行一个通常名为 update 的程序,它在无限循环中不断执行 sync 调用,每两次调用之间休眠 30 秒。于是,系统即使崩溃,也不会丢失超过 30 秒的工作。
块提前读
块提前读策略只适用于实际顺序读取的文件。对随机访问文件,提前读丝毫不起作用。相反,它还会帮倒忙,因为读取无用的块以及从高速缓存中删除潜在有用的块将会占用固定的磁盘帯宽(如果有“脏”块的话,还需要将它们写回磁盘,这就占用了更多的磁盘带宽)。
那么提前读策略是否值得采用呢?文件系统通过跟踪每ー个打开文件的访问方式来确定这一点。例如,可以使用与文件相关联的某个位协助跟踪该文件到底是“顺序访问方式”还是“随机访问方式”。在最初不能确定文件属于哪种存取方式时,先将该位设置成顺序访问方式。但是,査找一完成,就将该位清除。如果再次发生顺序读取,就再次设置该位。这样,文件系统可以通过合理的猜测,确定是否应该采取提前读的策略。即便弄错了一次也不会产生严重后果,不过是浪费一小段磁盘的带宽罢了。
减少磁盘臂运动
固态硬盘不考虑这个问题。
4.4.5 磁盘碎片整理
4.5 文件系统实例
第十章有详细介绍。

