《现代操作系统》第3章——内存管理
《现代操作系统》第 3 章——内存管理
3.1 无存储器的抽象
早期大型计算机(20 世纪 60 年代之前)、小型计算机(20 世纪 70 年代之前)和个人计算机(20 世纪 80 年代之前)都没有存储器抽象。每一个程序都直接访问物理内存,存储器模型就是物理内存。当一个程序执行如下指令:
MOV REGISTER1, 1000
计算机会将位置为 1000 的物理内存中的内容移到 REGISTER1 中。在这种情况下,想要在内存中同时运行两个程序是不可能的。因为直接使用了物理地址,程序之间会相互影响。
在不使用存储器抽象的情况下运行多个程序
IBM 360 的早期模型是这样解决的:内存被划分成为 2KB 的块,每个块被分配一个 4 位的保护键,保护键存储在 CPU 的特殊寄存器中。一个内存为 1MB 的机器只需要 512 个这样的 4 位寄存器,容量总共位 256 字节。PSW(Program Status Word,程序状态字)中存有一个 4 位码。一个运行中的进程如果访问保护键与其 PSW 码不同的内存,IBM 360 的硬件会捕获到这一事实。因为只有操作系统可以修改保护键,这样就可以防止用户进程之间、用户进程和操作系统之间的相互干扰。
但是这样做存在这样一个问题,例如有两个用户程序,它们中一个有指令JMP 24,一个有指令JMP 28,如果这样两个进程被装载到内存后,则必有一个进程的起始地址不再地址 0 处,这样的话,其JMP指令就会失效,会跳转到错误的地方。补救方案是装载进程到内存的时候,使用静态重定位技术修改它,即给这个进程中所有的指令都加上程序被装载进内存时的起始地址。
3.2 一种存储器的抽象:地址空间
3.2.1 地址空间的抽象
一个更好的办法是创造一个新的存储器抽象:地址空间(address space)。就像进程的概念创造了一类抽象的 cpu 以运行程序一样,地址空间为程序创造了一种抽象的内存。地址空间是一个进程可用于寻址内存的一套地址集合。每个进程都有一个自己的地址空间,并且这个地址空间独立于其他进程的地址空间(除了在一些特殊情况下进程需要共享它们的地址空间外)。
基址寄存器和界限寄存器
使用基址寄存器和界限寄存器相当于将进程内的所有地址,在运行时做动态重定位,例如,当基址寄存器为 16384,界限寄存器为 32768 时,程序执行
JMP 28
硬件会将其解释为
JMP 16412
即基址寄存器的值加上程序的虚拟地址,且检查该地址小于界限寄存器的值。
3.2.2 交换技术
有两种处理内存超载的通用方法。最简单的策略是交换(swapping)技术,即把一个进程完整调入 内存,使该进程运行一段时间,然后把它存回磁盘。空闲进程主要存储在磁盘上,所以当它们不运行时就不会占用内存。
交换在内存中产生了多个空闲区(hole,也称为空洞),通过把所有的进程尽可能向下移动,有可能将这些小的空闲区合成一大块。该技术称为内存紧缩(memory compaction)。通常不进行这个操作,因为它要耗费大量的 CPU 时间。例如,一台有 16GB 内存的计算机可以每 8ns 复制 8 个字节,它紧缩全部内存大约要花费 16s。
3.2.3 空闲内存管理
1. 使用位图的存储器管理
内存可能被划分成小到几个字或大到几千字节的分配单元。每个分配单元对应于位图中的一位。0 表示空闲,1 表示占用(或者相反)。
这种方法的主要问题是,在决定把一个占 k 个分配单元的进程调入内存时,存储管理器必须搜索位图,在位图中找出有 k 个连续 0 的串。査找位图中指定长度的连续串是耗时的操作(因为在位图中该串可能跨越字的边界),这是位图的缺点。
2. 使用链表的存储器管理
维护一个记录已分配内存段和空闲内存段的链表。
如果进程和空闲区使用不同的链表,则可以按照大小对空闲区链表排序。
在与进程段分离的单独链表中保存空闲区时,可以做一个小小的优化,可以利用空闲区存储链表中的结点。每个空闲区的第一个字可以是空闲区大小,第二个字指向下一个空闲区。
当按照地址顺序在链表中存放进程和空闲区时,有几种算法可以用来为创建的进程(或从磁盘换入的已存在的进程)分配内存。它们分别是:首次适配、最佳适配和快速适配。
3.3 虚拟内存
*3.3.1 分页
大部分虚拟内存系统中都使用一种称为分页(paging)的技术。
由程序产生的这些地址称为虚拟地址(virtual address),它们构成了一个虚拟地址空间(virtual address space)。在没有虚拟内存的计算机上,系统直接将虚拟地址送到内存总线上,读写操作使用具有同样地址的物理内存字;而在使用虚拟内存的情况下,虚拟地址不是被直接送到内存总线上,而是被送到内存管理单元(Memory Management Unit,MMU),MMU 把虚拟地址映射为物理内存地址。
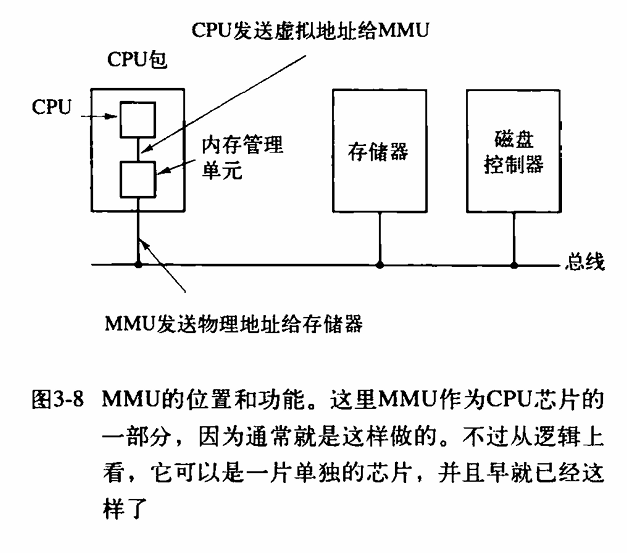
虚拟地址空间按照固定大小划分成被称为页面(page)的若干单元。在物理内存中对应的单元称为页框(page frame)。页面和页框的大小通常是一样的,在本例中是 4KB,但实际系统中的页面大小从 512 字节到 1GB。对应于 64KB 的虚拟地址空间和 32KB 的物理内存,可得到 16 个虚拟页面和 8 个页框。RAM 和磁盘之间的交换总是以整个页面为单元进行的。
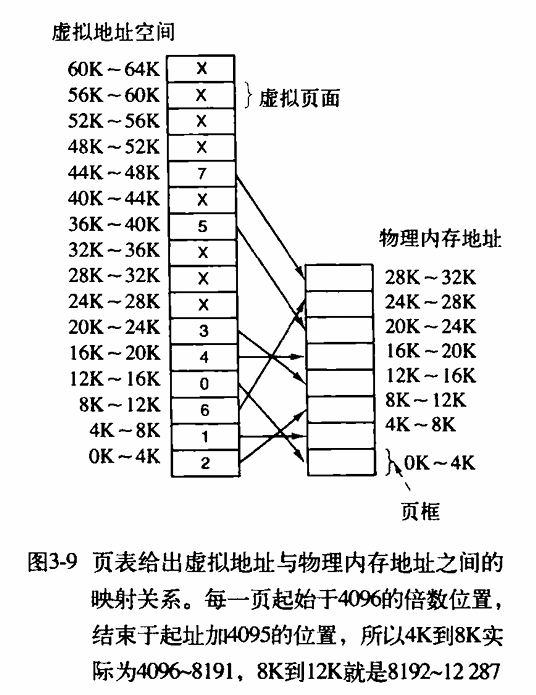
当程序试图访问地址时,例如执行下面这条指令:
MOV REG, 0
将虚拟地址 0 送到 MMU。MMU 看到虚拟地址落在页面 0(0~4095),根据其映射结果,这一页面对应的 是页框 2(8192~12 287),因此 MMU 把地址变换为 8192,并把地址 8192 送到总线上。内存对 MMU 一无所知,它只看到一个读或写地址 8192 的请求并执行它。MMU 从而有效地把所有从 0~4095 的虚拟地址映射到了 8192~12287 的物理地址。
同样地,指令
MOV REG, 8192
被有效地转换为
MOV REG, 24576
在上图中用叉号表示的其他页面并没有被映射。在实际的硬件中,用一个“在/不在”位(Present/Absent Bit)记录页面在内存中的实际存在情况。当程序访问了一个未映射的页面,例如执行指令
MOV REG, 32780
将会发生什么情况呢?虚拟页面 8(从 32768 开始)的第 12 个字节所对应的物理地址是什么呢?MMU 注意到该页面没有被映射(在图中用叉号表示),于是使 CPU 陷入到操作系统,这个陷阱称为缺页中断或缺页错误(Page Fault)。操作系统找到一个很少使用的页框且把它的内容写入磁盘(如果它不在磁盘上)。随后把需要访问的页面读到刚オ回收的页框中,修改映射关系,然后重新启动引起陷阱的指令。
例如,如果操作系统决定放弃页框 1,那么它将把虚拟页面 8 装入物理地址 4096,并对 MMU 映射做两处修改:
1. 首先,它要将虚拟页面 1 的表项标记为未映射,使以后任何对虚拟地址 4096~8191 的访问都导致陷阱。
2. 随后把虚拟页面 8 的表项的叉号改为 1,因此在引起陷阱的指令重新启动时,它将把虚拟地址 32780 映射为物理地址 4108(4096+12)。
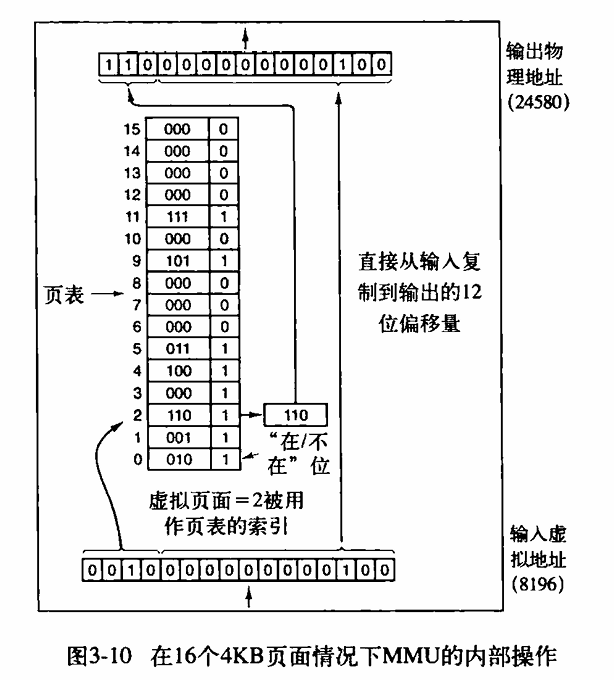
下面査看一下 MMU 的内部结构以便了解它是怎么工作的,以及了解为什么我们选用的页面大小都是 2 的整数次幕。在上图中可以看到一个虚拟地址的例子,虚拟地址 8196(二进制是 0010000000000100)用上图所示的 MMU 映射机制进行映射,输入的 16 位虚拟地址被分为 4 位的页号和 12 位的偏移量。4 位的页号可以表示 16 个页面,12 位的偏移可以为一页内的全部 4096 个字节编址。
可用页号作为页表(page table)的索引,以得出对应于该虚拟页面的页框号。如果“在/不在”位是 0,则将引起一个操作系统陷阱。如果该位是 1,则将在页表中査到的页框号复制到输出寄存器的高 3 位中,再加上输入虚拟地址中的低 12 位偏移量。如此就构成了 15 位的物理地址。输出寄存器的内容随即被作为物理地址送到内存总线。
3.3.2 页表
3.3.3 加速分页的过程
1. 转换检测缓冲区
大多数程序总是对少量的页面进行多次的访问,而不是相反。因此,只有很少的页表项会被反复读取,而其他的页表项很少被访问。
因此,可以有这样的一种解决方案,为计算机设置一个小型的硬件设备,将虚拟地址直接映射到物理地址,而不必再访问页表。这种设备称为转换检测缓冲区(Translation Lookaside Buffer, TLB),有时又称为相联存储器(associate memory)或快表。它通常在 MMU 中,包含少量的表项,在此例中为 8 个,在实际中很少会超过 256 个。每个表项记录了一个页面的相关信息,包括虚拟页号、页面的修改位、保护码(读/写/执行权限)和该页所对应的物理页框。除了虚拟页号(不是必须放在页表中),这些域与页表中的域是一对应的。另外还有一位用来记录这个表项是否有效(即是否在使用)。
2. 软件 TLB 管理
3.3.4 针对大内存的页表
1. 多级页表
2. 倒排页表
3.4 页面置换算法
为什么需要页面置换算法?
因为当发生缺页中断的时候,操作系统必须从内存中选择一个页面将其换出内存,以便为即将调入的页面腾出空间。这是请求调页。
| 算法 | 注释 |
|---|---|
| 最优算法 | 不可实现,但可用作基准 |
| NRU(Not Recently Used,最近未使用)算法 | LRU 的很粗糙的近似,看页面的标记位,确定是否被使用 |
| FIFO(先进先出)算法 | 可能抛弃重要页面 |
| 第二次机会算法 | 比 FIFO 有较大的改善 |
| 时钟算法 | 现实的 |
| *LRU(Least Recently Used,最近最少使用)算法 | 很优秀,但很难实现 |
| NFU(Not Recently Used,最不经常使用)算法 | LRU 的相对粗略的近似,计数器 |
| *老化算法 | 非常近似 LRU 的有效算法 |
| 工作集算法 | 实现起来开销很大 |
| 工作集时钟算法 | 好的有效算法 |
这里提到的 LRU 为何很难实现?
3.5 分页系统中的设计问题
前面讨论了分页系统如何工作,介绍了基本的页面置换算法。当然,只了解基本机制是不够的。要设计一个系统,必须知道如何是这个系统工作的更好,需要从全局考虑一些问题。下面是一些能过使得整个系统工作得更好的策略。
除了分页以外,还有哪些策略能够使得更个系统、分页系统工作得更好。
3.5.1 局部分配策略和全局分配策略
局部分配就是每个进程只在自己圈子里折腾,全局分配策略就是统筹调度。一般情况下,全局分配工作得比局部分配好。因为局部分配时间长了,会在进程内部产生空闲页框(内部碎片),导致浪费。随着工作集的增长,会有颠簸产生。
3.5.2 负载控制
当然,即使用最有页面置换算法并对进程采用理想的全局页框分配,系统也会发生颠簸。因为一些进程需要更多的内存,但是没有进程需要更少的内存。所以这种情况下,唯一的解决方法就是暂时从内存中去掉一些进程,从而减少了资源竞争。一个可行的方法是将进程交换到磁盘中去,并释放它们的页面。所以,即使是分页,也需要交换,这个交换指的是整个进程交换出去,而不是交换只页面。
当然也要考虑多道程序设计的道数,总之,这是一个需要平衡的问题。
3.5.3 页面大小
页面大小也是操作系统的一个可以选择的参数。要确定最佳页面大小需要在几个相互矛盾的因素之间进行平衡。
利用率方面
一般而言,任意一个正文段、数据段或者堆栈段很可能不会恰好装满整个页面,平均的情况下,最后一个页面中有一半是空的。这就造成了浪费,这种浪费称为内部碎片(internal fragmentation)。内存中有 n 个段、页面大小为 p 字节时,会有 np/2 字节被内部碎片浪费掉。从这方面考虑,使用小页面好。
传输方面
但是,页面越小,页表就越大。一个 32KB 的程序只需要 4 个 8KB 的页面,却需要 64 个 512 字节的页面。内存和磁盘之间的传输一般是一次一页,传输中的大部分时间都花在了寻道和旋转延迟上,所以传输一个小页面所用的时间和传输一个大页面所用的时间是相同的。所以,装入 64 个 512 字节的页面可能需要 64x10ms,而装入 4 个 8KB 的页面可能只需要 4x10ms。
TLB 方面
此外,小页面能够更好地利用 TLB 空间。假设程序使用的内存为 1MB,工作单元为 64KB。若使用 4KB 的页,则程序将至少占用 TLB 中的 16 个表项;而使用 2MB 的页时,1 个 TLB 表项就足够了。由于 TLB 表项相对稀缺,且对于性能而言至关重要,因此在条件允许的情况下使用大页面是值得的。为了进行必要的平衡,操作系统有时会为系统中的不同部分使用不同的页面大小。例如,内核使用大页面,而用户进程则使用小页面。
数学角度分析
最后一点可以从数学上进行分析,假设进程平均大小是\(s\)个字节,页面大小是\(p\)个字节,每个页表项需要\(e\)个字节。那么每个进程需要的页数大约是\(\frac{s}{p}\),占用了\(\frac{se}{p}\)个字节的页表空间。内部碎片在最后一页浪费的内存是\(\frac{p}{2}\)。因此,由页表和内部碎片损失造成的全部开销是以下两项之和:
显然,当页面较小时,第一项大,在页面较大时,第二项大。最优值一定在页面大小中间的某个值时取得,通过对\(p\)一次求导,得到方程:
从而可以从这个方程得到最优页面大小的公式,结果是:
因此,对于\(s=1MB\),每个页表项\(e=8B\),最优页面大小是 4KB。商用计算机使用的页面大小一般在 512B 到 64KB 之间,以前的典型值是 1KB,而现在更常见的页面大小是 4KB 或 8KB。
3.5.4 分离指令空间和数据空间
说白了,就是把进程的一个地址空间分成两个部分,一个是指令,一个是数据。这样做的好处是,可以使得指令和数据的访问模式不同,从而可以采用不同的页面置换算法。例如,指令一般是顺序执行的,所以可以采用 FIFO 算法,而数据一般是随机访问的,所以可以采用 LRU 算法。
不过这种做法也有缺点,就是会增加页表的大小,因为每个进程都有两个页表。
3.5.5 共享页面
让分页系统更高效的另一个方法是共享页面。共享页面就是多个进程共享同一个页面。显然,由于这样做避免了一份数据在内存中有两份副本,因此效率更高。而且并不是所以页面都可以共享,比如只读的代码段可以共享,但是可能被修改的数据段则不能贡献。
下面讲共享页面的实现。
如果实现了上述的指令空间和数据空间分离,让多个进程实现页面共享就会非常简单。一个典型的实现是,每个进程有两个指针,一个指向 I 空间页表,一个指向 D 空间页表。当一个进程被调度运行时,它使用合适的指针来定位页表,并设置 MMU。当然没有分类的 I 空间和 D 空间也可以实现共享页面,只是机制较为复杂。
当两个或多个进程在共享页面的时候,存在一个问题。假设进程 A 和进程 B 在共享页面,当进程 A 退出时,A 的页面会被回收,但是这些页面还在被进程 B 使用,这就会导致进程 B 发生大量的缺页中断,才能把这些页面重新调回。
所以,当进程 A 退出时,必须考虑它使用的页面当中,有哪些是共享页面。它需要遍历所有的页表,才能知道一个页面是否被共享。这是一个非常耗时的工作,且需要专门的数据结构。
共享数据段比共享代码段复杂,但也不是不可能。比如在 UNIX 系统中,一个进程使用fork()创建一个子进程后,父进程和子进程需要共享代码段和数据段。在分页系统中,通常的做法是,让这两个进程拥有各自的页表,但是页表指向相同的页面集合。这样在使用fork()进行进程的创建时,不会发生页面的复制,然后,两个进程映射到的数据内容都是只读的。
如果两个进程都不写数据,这种状况就可以一直保持下去。但是只要一个进程写了一点数据,就会触发“只读保护”,陷入内核。然后会生成一份需要修改的页面的副本,每个进程在其副本上写数据,这样就不会触发“只读保护”。这种策略意味着,那些从来不会执行写操作的页面是不需要复制的,只有实际修改的页面才需要复制。这种方法成为写时复制(Copy On Write,COW),它通过减少复制提高了性能。
*3.5.6 共享库
上面介绍了共享页面,总结就是,对于多次打开的程序,代码段可以多个进程共享一份,数据段则根据需要,对于要修改的部分,每个进程保有私有的部分,不需要修改的部分,则只有一份。
除了这个以外,还有一种更通用的方式,就是共享库。现代操作系统中,有很多大型库被使用。先来考虑一下传统的链接:
ld *.o -lc -lm
这个命令会链接目录下的所有目标文件,并扫描两个库,/usr/lib/libc.a和/usr/lib/libm.a。任何在目标文件中没有被定义的函数被称作外部未定义函数(undefined externals)。链接器会在这些库中寻找这些外部未定义函数。如果找到了,就将其加载到可执行文件中。
为每一个程序单独链接这些经常被使用的库,不仅会浪费大量的磁盘空间,在把这些程序装载进内存的时候也会浪费大量的内存,因为系统不知道可以共享哪些库。而这就是共享库被引入的原因。
当链接器链接共享库的时候,并不会把外部未定义函数加载进来,而是会在运行时加载一段可以绑定到被调用函数的存根例程(stub routine)。然后依赖于系统和配置,共享库和程序可能被一起装载进来,或者在其所包含的函数被调用的时候被加载进来。如果某个程序以进加载共享库了,那么这个共享库就没有必要再被加载进来了,这正式共享库的关键。
什么是“存根例程”?
值得注意的是,当一个共享库被加载使用时,并不是一次性把整个库装入内存,而是根据需要,以页面为单外进行装载,因此没有被调用的函数是不会被加载进内存的。
综上所述,使用了共享库之后,外部未定义函数的加载推迟到了运行时,但是多个进程可以共享一个库中被调用的函数。
此外,还有一个小问题需要解决。例如现在有两个进程都在使用一个库,进程 A 在地址 36K 处调用了库中的函数,而这个函数在库中的偏移量为 12,那么这个函数会被重定位到 36K+12。这在不使用共享库的时候没有问题,但是,此时第二个进程 B 也使用了库中的函数,而库在进程 B 中被重定位到了 24K,那么同样的函数,在进程 B 中就会被重定位到 24K+12,这显然是不行的。当然,可以对这种情况也使用写时复制,但这样做就和共享库的初衷违背了。
仔细理解上面这段话。
有一个更好的解决方法,就是通过一个选项告诉编译器不要使用绝对地址的指令。相反,只能使用相对地址的指令。例如,几乎总是使用向前(或者向后)调转 n 个字节。这样,通过避免使用绝对地址,这个问题就可以被解决。这里,只使用相对偏移量的代码,被称为位置无关代码(Position-Independent Code,PIC,编译器选项:-fPIC)。
3.5.7 内存映射文件
其实上面的共享库,就是一种“内存映射文件”的特例。这种机制的核心思想是:进程发起一个系统调用,把文件映射到其虚拟地址空间的一部分。
在多数实现中,在使用映射共享页面时,不会实际读入页面的内容,而是在访问页面时才被每次一页地读入。当进程退出或者解除文件映射时,所改动的页面会被写入磁盘文件中。
扩展一下,当多个进程同时映射一个文件的时候,它们就可以通过共享内存来通信。一个进程在共享内存上完成写操作,此刻当另一个进程在映射到这文件的虚拟地址空间上执行读操作时,它就可以立刻看到上一个进程写操作的结果。显然,这个机制可以提供一个进程间高带宽的通道,而且这种应用很普遍。
3.5.8 清除策略
前文提到了负载控制,这里介绍一种负载控制的实际策略。
当系统中的空闲页框较多时,分页系统的工作状态最佳。所以可以引入一个进程,定期检查内存的状态。如果空闲页框较少,这个进程就使用之前提到的页面置换算法,选择一些页面,将其置换到的磁盘上。如果这些页面在装入内存之后被修改过,则将它们写回磁盘。这个进程被称为分页守护进程(Paging Daemon)。
为了提高效率,被分页守护进程置换出去的页面如果没有被修改,这个页面是不会被写回到磁盘的,而是将其加入到“空闲页框缓冲池”中。当下次这个页面被需要时,且其该页面对应的页框没有被覆盖的话,则可以直接恢复该页面。
一种实现清除策略的方法是使用一个双指针时钟(相当于一个读写分离的缓冲,前指针和后指针之间的页面是干净页面)。前指针由分页守护进程控制,当它指向脏页面时,就把该页面写回磁盘,前指针向前移动;当它指向干净页面时,仅仅指针向前移动。后指针用于页面置换。现在,由于分页守护进程的工作,后指针命中干净页面的概率会增加。
分页守护进程相当于提前做了换页的工作,减少了缺页中断的发生。
分页守护进程相当于预先调页,缺页中断是请求调页。
3.5.9 虚拟内存接口
多进程共享内存,进程间相互通知。
3.6 有关实现的问题
3.6.1 与分页有关的工作
操作系统要在下面的四段时间里做与分页相关的工作:进程创建时,进程执行时,缺页中断时和进
程终止时。下面将分别对这四个时期进行简短的分析。
当在分页系统中创建一个新进程时,操作系统要确定程序和数据在初始时有多大,并为它们创建一个页表。操作系统还要在内存中为页表分配空间并对其进行初始化。当进程被换出时,页表不需要驻留在内存中,但当进程运行时,它必须在内存中。另外,操作系统要在磁盘交换区中分配空间,以便在一个进程换出时在磁盘上有放置此进程的空间。操作系统还要用程序正文和数据对交换区进行初始化,这样当新进程发生缺页中断时,可以调入需要的页面。某些系统直接从磁盘上的可执行文件对程序正文进行分页,以节省磁盘空间和初始化时间。最后,操作系统必须把有关页表和磁盘交换区的信息存储在进程表中。
当调度一个进程执行时,必须为新进程重置 MMU,刷新 TLB,以清除以前的进程遗留的痕迹。新进程的页表必须成为当前页表,通常可以通过复制该页表或者把一个指向它的指针放进某个硬件寄存器来完成。有时,在进程初始化时可以把进程的部分或者全部页面装入内存中以减少缺页中断的发生,例如,PC(程序计数器)所指的页面肯定是需要的。
当缺页中断发生时,操作系统必须通过读硬件寄存器来确定是哪个虚拟地址造成了缺页中断。通过该信息,它要计算需要哪个页面,并在磁盘上对该页面进行定位。它必须找到合适的页框来存放新页面,必要时还要置换老的页面,然后把所需的页面读入页框。最后,还要回退程序计数器,使程序计数器指向引起缺页中断的指令,并重新执行该指令。
当进程退出的时候,操作系统必须释放进程的页表、页面和页面在硬盘上所占用的空间。如果某些页面是与其他进程共享的,当最后一个使用它们的进程终止的时候,オ可以释放内存和磁盘上的页面。
3.6.2 缺页中断处理
现在终于可以讨论缺页中断发生的细节了。缺页中断发生时的事件顺序如下:
- 硬件陷入内核,在堆栈中保存程序计数器。大多数机器将当前指令的各种状态信息保存在特殊的 CPU 寄存器中。
- 启动一个汇编代码例程保存通用寄存器和其他易失的信息,以免被操作系统破坏。这个例程将操作系统作为一个函数来调用。
- 当操作系统发现一个缺页中断时,尝试发现需要哪个虚拟页面。通常一个硬件寄存器包含了这一信息,如果没有的话,操作系统必须检索程序计数器,取出这条指令,用软件分析这条指令,看看它在缺页中断时正在做什么。
- 一旦知道了发生缺页中断的虚拟地址,操作系统检査这个地址是否有效,并检査存取与保护是否一致。如果不一致,向进程发出一个信号或杀掉该进程。如果地址有效且没有保护错误发生,系统则检査是否有空闲页框。如果没有空闲页框,执行页面置换算法寻找一个页面来淘汰。
- 如果选择的页框“脏”了,安排该页写回磁盘,并发生一次上下文切换,挂起产生缺页中断的进程,让其他进程运行直至磁盘传输结束。无论如何,该页框被标记为忙,以免因为其他原因而被其他进程占用。
- 一旦页框“干净”后(无论是立刻还是在写回磁盘后),操作系统查找所需页面在磁盘上的地址,132 通过磁盘操作将其装入。该页面正在被装入时,产生缺页中断的进程仍然被挂起,并且如果有其他可运行的用户进程,则选择另一个用户进程运行。
- 当磁盘中断发生时,表明该页已经被装入,页表已经更新可以反映它的位置,页框也被标记为正 常状态。
- 恢复发生缺页中断指令以前的状态,程序计数器重新指向这条指令。
- 调度引发缺页中断的进程,操作系统返回调用它的汇编语言例程。
- 该例程恢复寄存器和其他状态信息,返回到用户空间继续执行,就好像缺页中断没有发生过一样。
3.6.3 指令备份
3.6.4 锁定内存中的页面
假设一个进程因需要从磁盘中读入数据而挂起,而轮到另一个进程时,这个进程产生了一个缺页中断,恰好将前一个进程接收磁盘读入内容的页面置换了出去。这样会导致一部分数据被读入到了之前的页面,一部分数据被读入到了之后的页面。
对于这种情况,有一个办法可以解决,那就是把正在做 I/O 操作的页面锁住,使其不会被置换出内存。锁住一个页面,通常被称为在内存中钉住(pinning)一个页面。 CUDA 里面有类似的概念,Pinned Memory。
另一种方法是在内核缓冲区中完成所有 I/O 操作,然后在将数据复制到用户页面。
3.6.5 后备存储
在磁盘上分配页面空间的最简单的算法是在磁盘上设置特殊的交换分区,甚至从文件系统划分一块独立的磁盘(以平衡 I/O 负载)。大多数 UNIX 是这样处理的。在这个分区里没有普通的文件系统,这样就消除了将文件偏移转换成块地址的开销。取而代之的是,始终使用相应分区的起始块号。
当系统启动时,该交换分区为空,并在内存中以单独的项给出它的起始和大小。在最简单的情况下,当第一个进程启动时,留出与这个进程一样大的交换区块,剩余的为总空间减去这个交换分区。当新进程启动后,它们同样被分配与其核心映像同等大小的交换分区。进程结束后,会释放其磁盘上的交换区。交换分区以空闲块列表的形式组织。
3.6.6 策略和机制的分离
3.7 分段
目前为止讨论的地址空间都是一维的,对于许多问题来说,在运行的时候会产生好几个不同的区域来存储不同类型的数据。随着程序的不断运行,这些区域的增长速度不同,一个区域可能会被装满,而其它区域可能还有很多空闲;或者多个动态增加的区域之间可能产生碰撞。可以用分段来解决这个问题。
分段就是把原来一维的地址空间分成多个相互独立的部分,称之为段(segment)。每个段构成一个独立的地址空间,它们可以独立地增长或减小而不会影响其它的段。这样的话,就将原来一维的地址空间变成了二维的地址空间,程序在这种模型中指示一个地址,需要提供两部分的地址,一个段号和一个段内地址。
这样做不仅能解决上述的问题,还能带来许多其它的好处。比如,如果一个进程中的每个过程都在一个独立的段中,且起始地址是 0,那么把单独编译好的过程链接在一起的操作就可以得到很大的简化。当组成的程序的所有过程都被编译和链接好了之后,一个对段 n 中过程的调用将使用两部分组成的地址(n 0)来寻址到字 0(入口点)。
而且,如果某个段被重新编译过之后,即使新版本的程序比老版本的程序要大,也不需要对其它的过程进行修改(因为没有修改它们的起始地址)。在一维的地址中,过程被一个挨着一个紧紧地放在一起,中间没有空隙,因此修改一个过程的大小会影响其它无关过程的起始地址,而这又要修改调用了这些被移动过的过程的所有过程。
分段也有助于几个进程之间共享数据。这方面最常见的例子就是共享库,可以再看看前面的笔记。为了解决多个进程使用一个共享库造成的产生的地址不一致的问题,编译共享库的时候让编译器生成位置无关代码,共享库中的地址采用相对地址。这其实就是分段的思想。
3.7.1 纯分段的实现
天哪,看到这里想起大学的时候其实学习过分页和分段,那时候只顾着准备考试,稀里糊涂的,用的一本薄薄的教材,现在全忘了,是时候补课了……
分段和分页不同的是,页面是定长的,而段不是。因此,系统运行一段时间之后,内存会被划分成许多块(不定长的内存单元),一些块包含着段,一些块成为了空闲区,这种现象称为棋盘形碎片或外部碎片(external fragmentation)。
3.7.2 分段和分页的结合:MULTICS
类似两级分页。
先分段,段内分页。MULTICS 中的一个地址由两部分构成:段号和段内地址。段内地址又进一步分为页号和页内的偏移量。
段号查段表->段描述符->页表存在->页号查页表->对应页的物理地址->加上页内偏移->得到物理地址。
MULTICS 系统的内存管理机制可以看作是一种两级页表的实现。第一级是段表,它将逻辑地址空间分为多个段,每个段有自己的页表。第二级是页表,它将每个段进一步分为多个页。
实际的物理地址映射发生在第二级,即页表级别。每个页表项包含了对应页的物理基址。逻辑地址中的页内偏移被加到这个物理基址上,得到的结果就是实际的物理地址。
所以这个过程可以理解为:段号用来选择页表,页号用来在页表中选择页,页内偏移用来在页中选择具体的字节。
3.7.3 分段和分页的结合:Intel x86
Intel x86 的分段机制和 MULTICS 的分段机制在设计理念和实现方式上都有一些差别。
-
Intel x86 的分段机制主要是为了支持向后兼容和内存保护。在早期的 x86 架构中,由于物理地址空间的限制,分段机制可以让程序员使用更大的逻辑地址空间。
-
Intel x86 的分段机制则更简单,它只使用了一级的地址转换机制。段选择器用来查找段描述符,得到段的基地址;偏移量则是相对于段基地址的一个偏移,用于选择段内的一个特定位置。
总的来说,MULTICS 的分段机制更复杂,更灵活,更适合于大型的、模块化的程序;而 Intel x86 的分段机制则更简单,更直接,更适合于小型的、单一的程序。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App