tess4j图片识别 和训练语言库提高图片识别率
1.pom文件添加依赖

<!-- 图形验证码识别https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>
2.下载文件配置
链接:https://pan.baidu.com/s/1BsFJ7uTl-AEzcUEfuV9ESw
提取码:4wzp
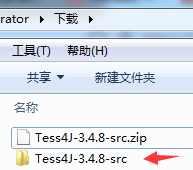
解压后显示
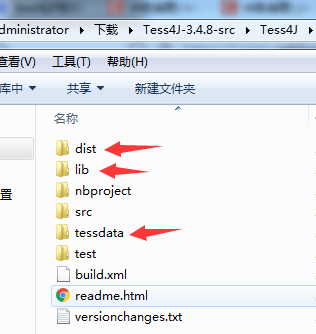
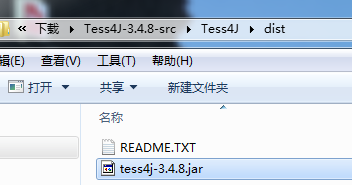
3.进入dist文件,拷贝文件tess4j-3.4.8.jar到lib文件下

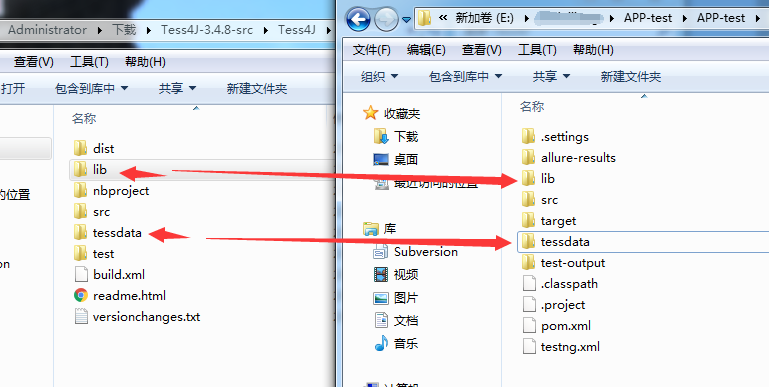
4.将lib文件和tessdata文件方到项目根目录
5.进入项目编码软件刷新项目目录
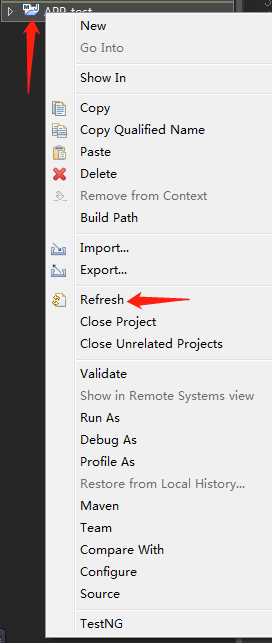
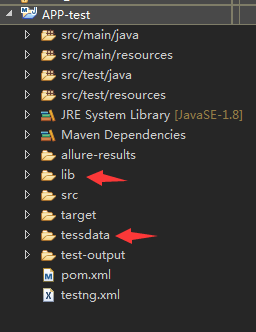
6.testdata可以放到项目文件目录下
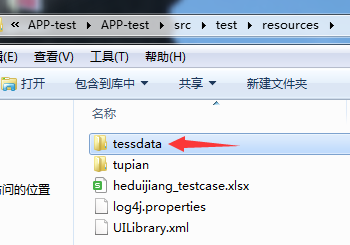
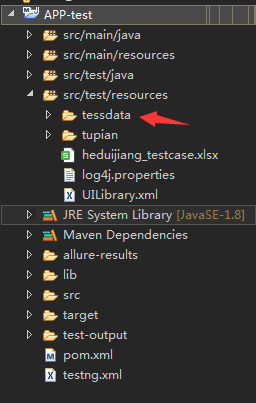
7.被识别的图片存放位置
新建目录,放在项目路径下
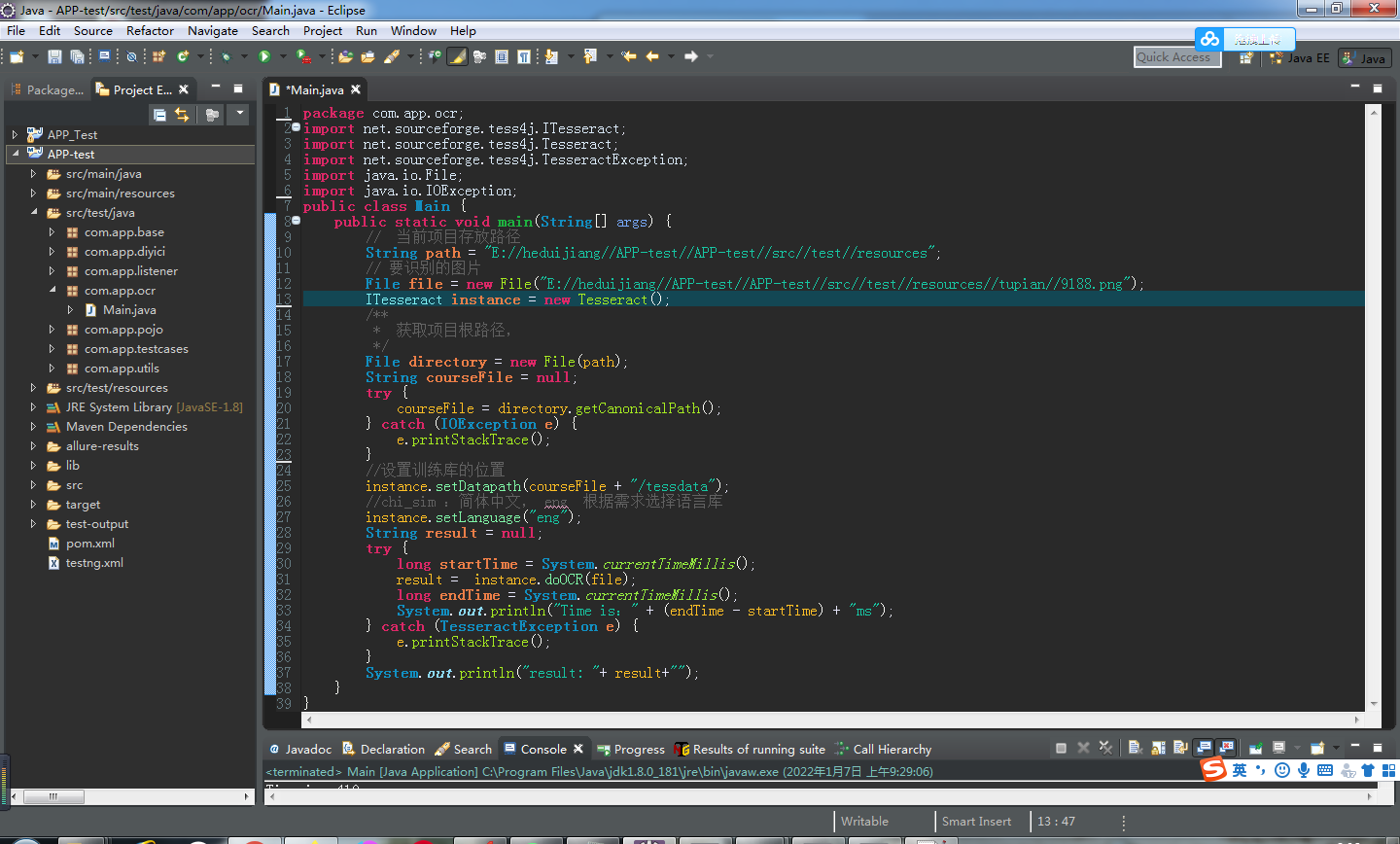
8.编写识别代码
package com.app.ocr;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
// 当前项目存放路径
String path = "E://heduijiang//APP-test//APP-test//src//test//resources";
// 要识别的图片
File file = new File("E://heduijiang//APP-test//APP-test//src//test//resources//tupian//9188.png");
ITesseract instance = new Tesseract();
/**
* 获取项目根路径,
*/
File directory = new File(path);
String courseFile = null;
try {
courseFile = directory.getCanonicalPath();
} catch (IOException e) {
e.printStackTrace();
}
//设置训练库的位置
instance.setDatapath(courseFile + "/tessdata");
//chi_sim :简体中文, eng 根据需求选择语言库
instance.setLanguage("eng");
String result = null;
try {
long startTime = System.currentTimeMillis();
result = instance.doOCR(file);
long endTime = System.currentTimeMillis();
System.out.println("Time is:" + (endTime - startTime) + "ms");
} catch (TesseractException e) {
e.printStackTrace();
}
System.out.println("result: "+ result+"");
}
}
9.在图片文件下放入要识别的图片
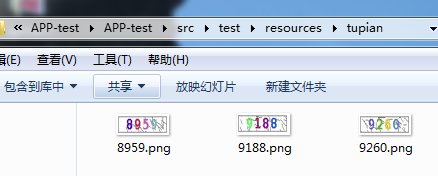
10.代码路径指定图片的绝对路径输入图片名称,进行识别
训练语言库适合自己的项目,自己编辑训练一个
1.截图自己的项目的图片

2.下载软件 jTessBoxEditorFX-2.3.1 和 tesseract-ocr-w64-setup-v5.0.0
链接:https://pan.baidu.com/s/1PUlfRKC5Xt4SWeBjfGKVUA
提取码:ad1q 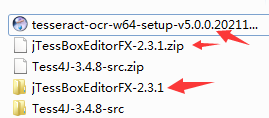
esseract-ocr-w64-setup-v5.0.0安装后配置环境变量,找到自己的安装的位置
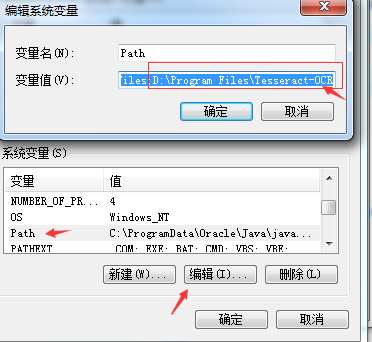
从https://digi.bib.uni-mannheim.de/tesseract/下载tesseract版本完成安装。配置好环境变量,打开命令行窗口执行tesseract -v 看到相关版本信息,则表示安装配置成功。
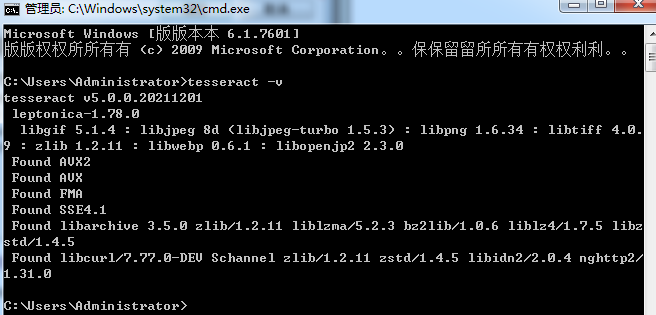
jTessBoxEditorFX-2.3.1 解压后显示
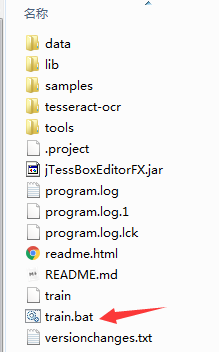
双击启动 train.bat

把图片文件夹放在此目录下,也可以在其它位置,这里我放到这个文件夹下
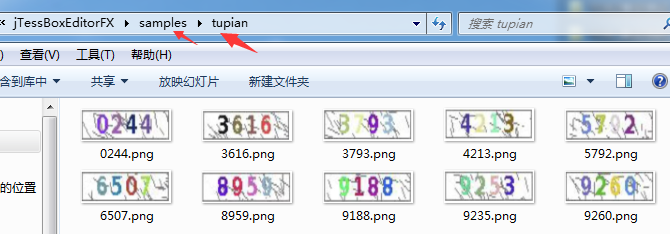
1、生成tif和box文件
可参照第一种方法生成。但这里介绍通过自定义图片使用jTessBoxEditor 合并tif

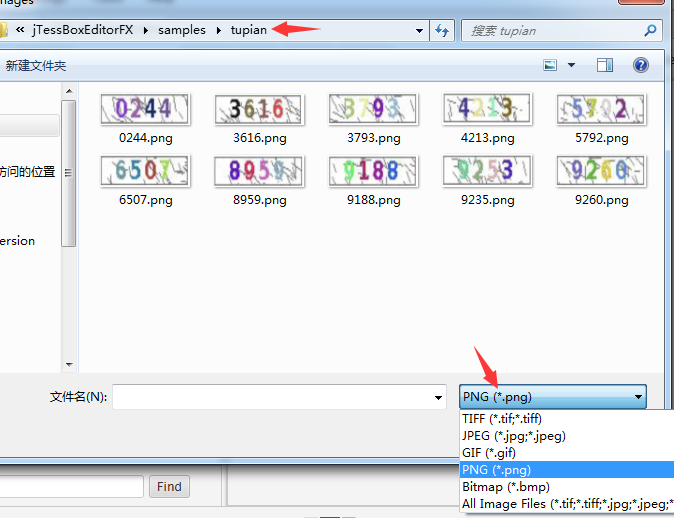
全选图片
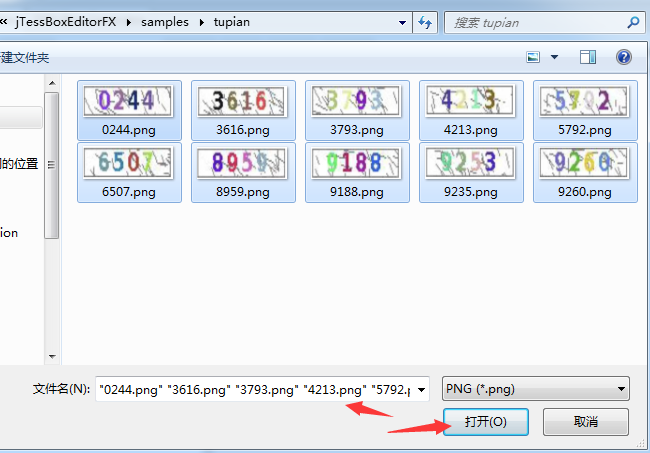
输入名字num.font.exp0.tif
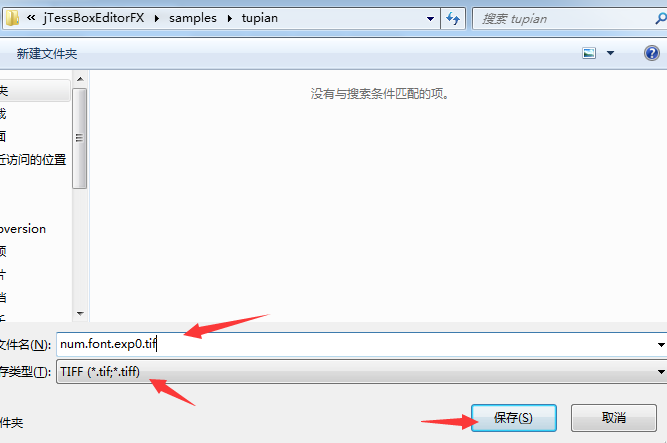
生成了文件
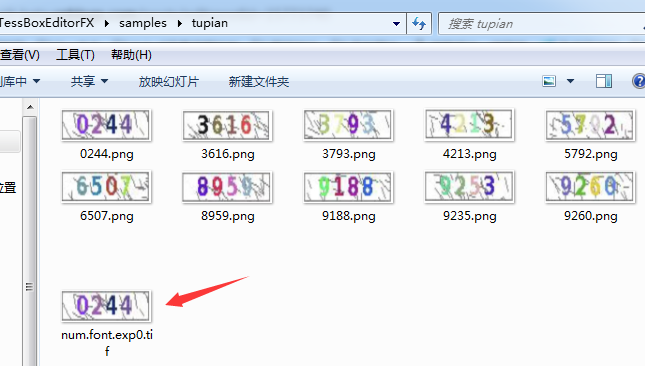
2、生成box文件
在生成图片文件夹下,打开cmd命令框
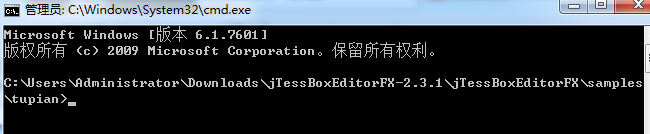
打开命令行执行命令tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox生成box文件,执行命令后输出如下:
D:\wspace\tess4j-demo2\test-data\num>tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
Tesseract Open Source OCR Engine v4.0.0.20181030 with Leptonica
Page 1
Page 2
Page 3
Page 4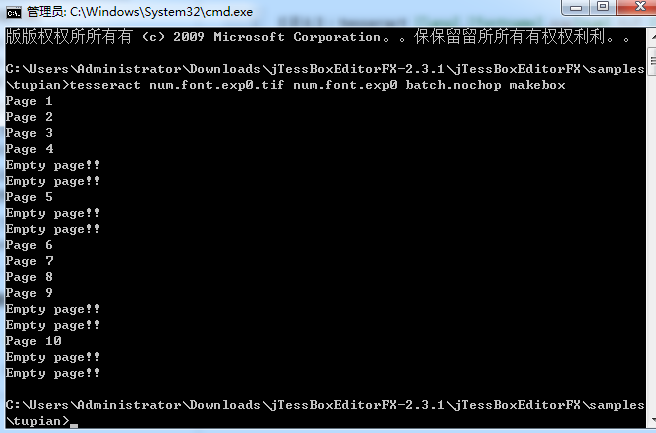
生成文件 box
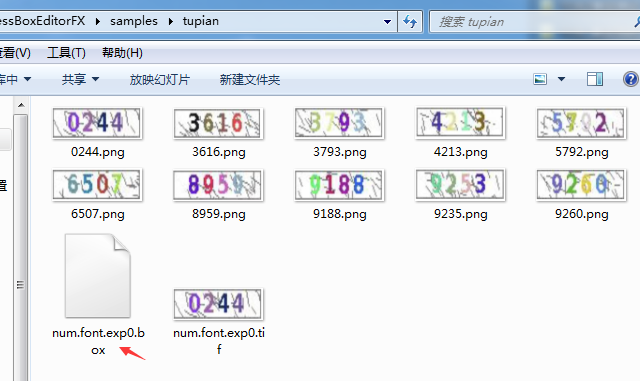
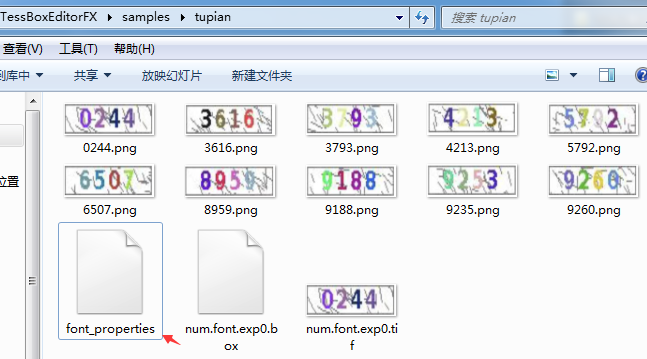
3、字符配置文件font_properties
在文件夹文件夹内,新建一个文本文件,名为font_properties,删掉.txt,用记事本打开,写入内容为:
font 0 0 0 0 0

准备环节
- 将5个tif文件,num.font.exp0.tif,生成的num.font.exp0.box文件,还有font_properties文件放在同一个目录下,如上面已经在一个目录下了
字符矫正
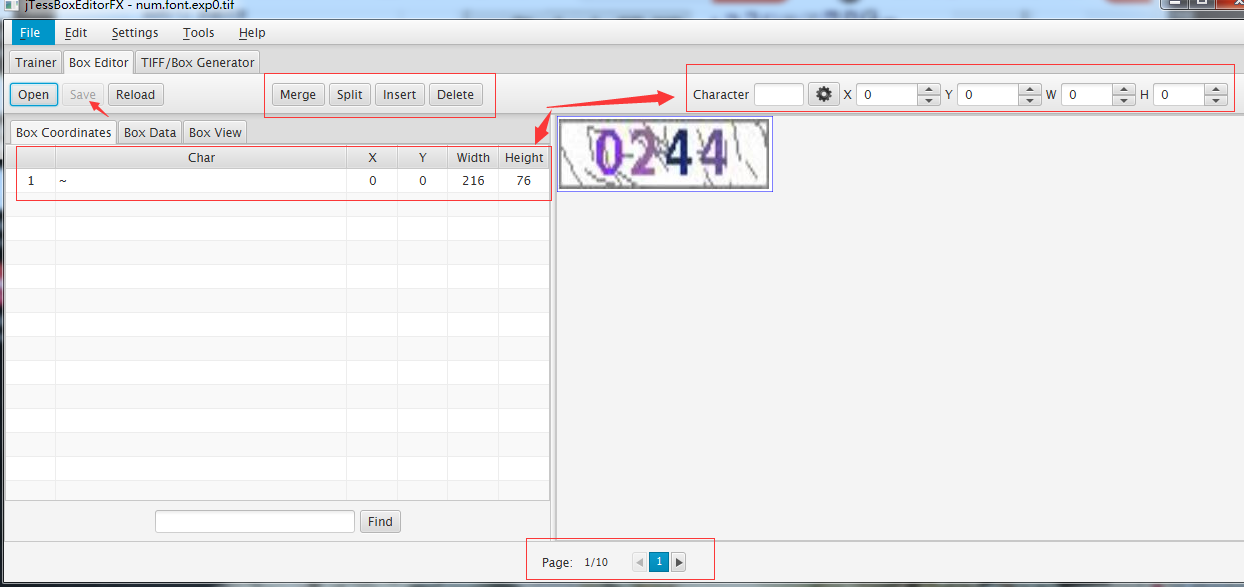
- 打开 jTessBoxEditor>【BOX Editor】> 【Open】,打开num.font.exp0.tif;矫正【Char】上的字符
- 操作截图:
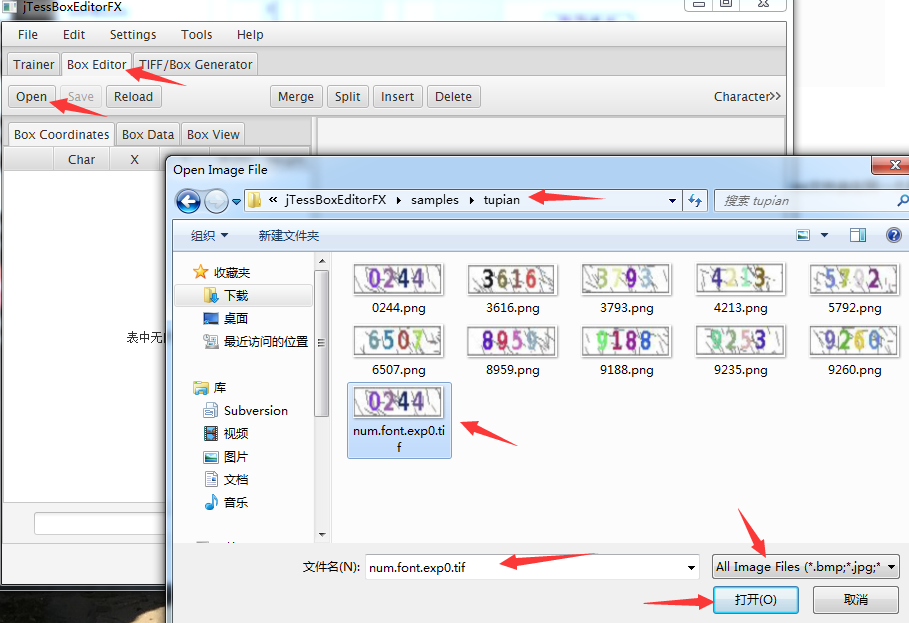
开始进行编写识别
insert 添加
delete 删除
merge 合并
split 分离 几乎不用此按钮


只选择x值调


依次循环,第一张完成后,切换第二张 最后点击保存
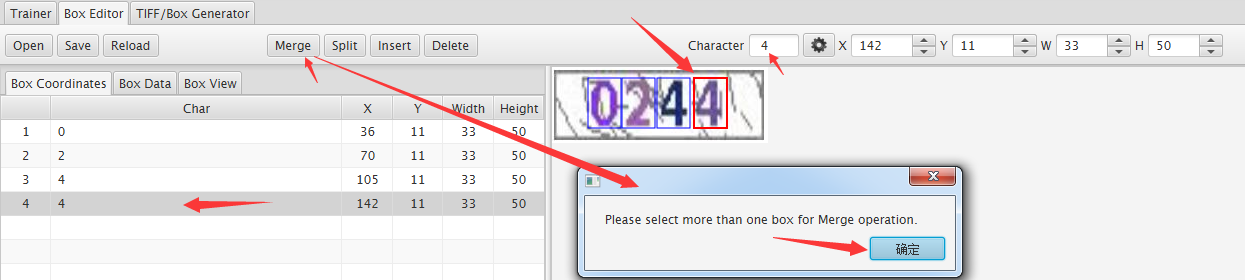
所有图片编辑完后,点击 Save 保存即可
8.执行批处理文件
- 【注意】:执行该批处理文件前,先要目录下创建font_properties文件 ,也就是滴 5 步
- 在目标目录下,新建一个txt文件,复制代码,重命名为 do.bat,直接更改后缀名就可以
- 代码如下
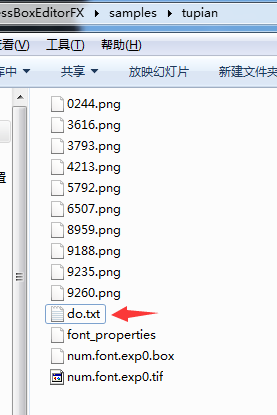
打开复制代码-保存
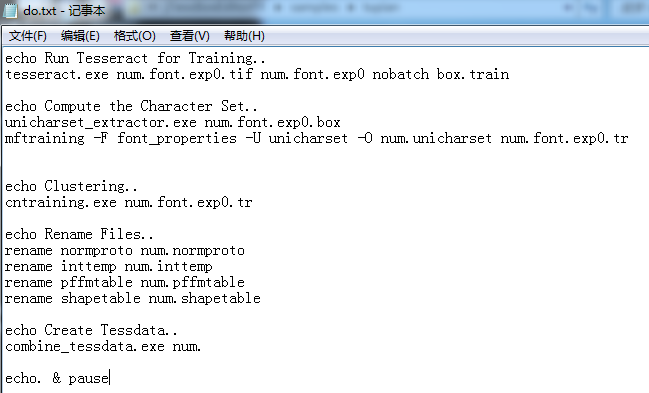
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
修改为 .bat文件

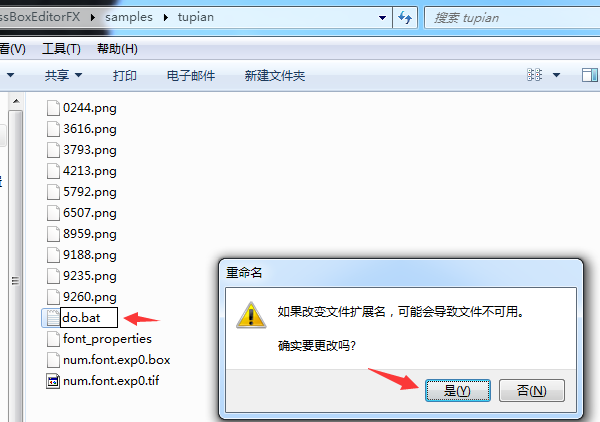
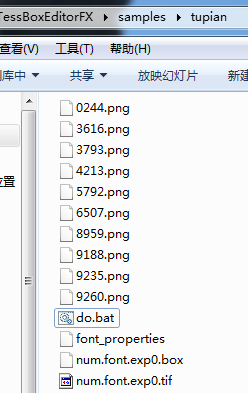
双击do.bat文件前
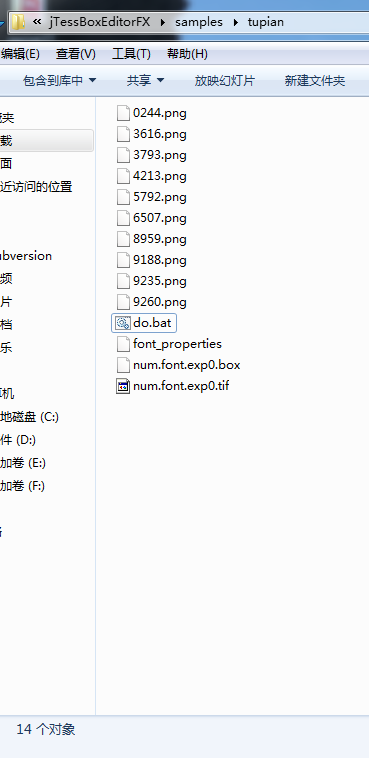
双击do.bat文件后
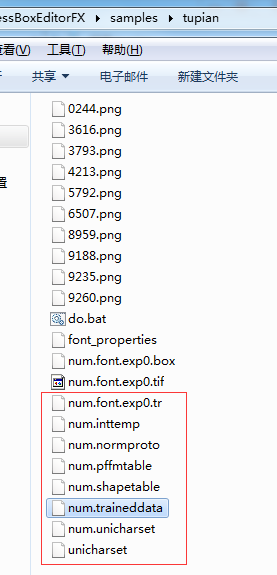
9.拷贝 num.trainddata 文件
- 最后将 num.trainddata 复制到 Tesseract-OCR 安装目录下的 tessdata 文件夹
- 【注意】:这里是【Tesseract-OCR 安装目录下的 tessdata 文件夹】

在图片文件下 输入cmd
再次输入命令 tesseract num1.jpg num01 -l num
num1.jpg 换成自己的图片
遇到问题 mftraining.exe 停止运行
解决方法 替换此文件就可以

用上面安装的软件,找到此路径下这个文件直接替换就可
找到本地文件位置
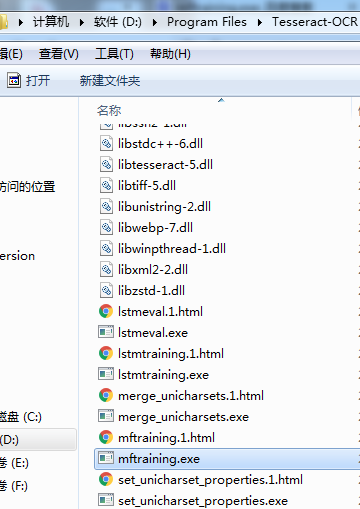
下载可以启动的文件
链接:https://pan.baidu.com/s/1NklBXlIi3W4D30O20lvXdw
提取码:d2pb
地址只把替换的文件拿出来了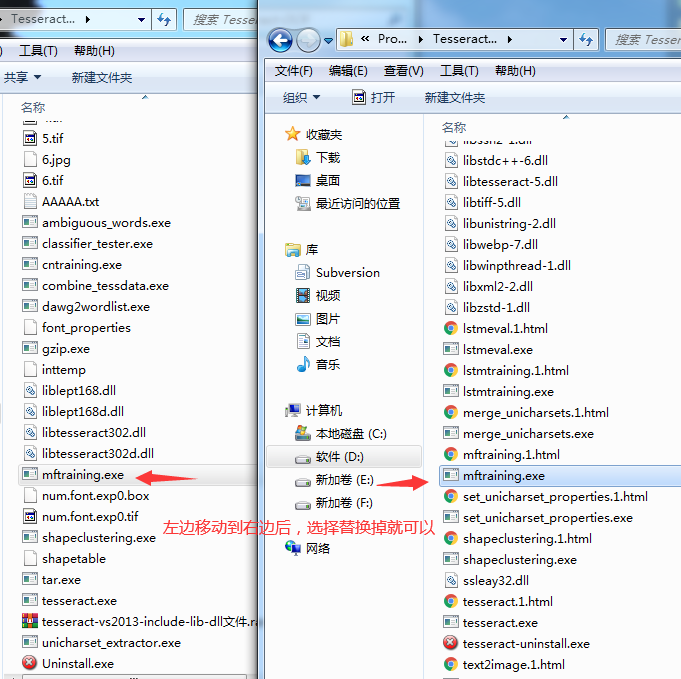
然后在执行 do.bat 就不报错了
其他
基于图片识别的识别率不高,所以我们一般先做图片的处理再进行识别。这个时候我们可以用到Tess4J专门提供的ImageHelper。里面分别有如下方法:
getScaledInstance 放大图片
getSubImage 截取图片
convertImageToBinary 转二进制
convertImageToGrayscale 将图像转换为灰度
invertImageColor 反转图像颜色
rotateImage 旋转影像
//图片转图片流
BufferedImage img = ImageIO.read(file);
// 这里对图片黑白处理,增强识别率.这里先通过截图,截取图片中需要识别的部分
img = ImageHelper.convertImageToGrayscale(img);
// 图片锐化,自己使用中影响识别率的主要因素是针式打印机字迹不连贯,所以锐化反而降低识别率
// img = ImageHelper.convertImageToBinary(img);
// 图片放大5倍,增强识别率(很多图片本身无法识别,放大7倍时就可以轻易识,但是考滤到客户电脑配置低,针式打印机打印不连贯的问题,这里就放大7倍)
img = ImageHelper.getScaledInstance(img, img.getWidth() * 7, img.getHeight() * 7);
package com.app.ocr;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import net.sourceforge.tess4j.util.ImageHelper;
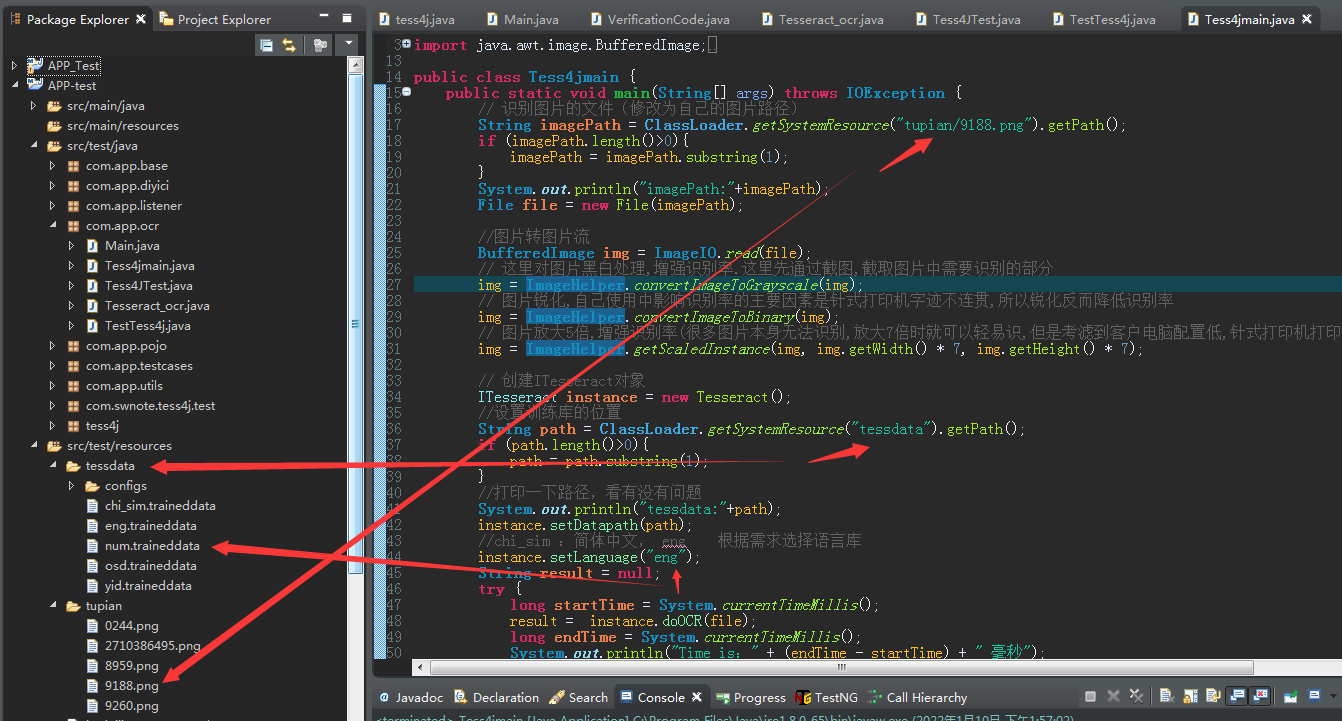
public class Tess4jmain {
public static void main(String[] args) throws IOException {
// 识别图片的文件(修改为自己的图片路径)
String imagePath = ClassLoader.getSystemResource("tupian/9188.png").getPath();
if (imagePath.length()>0){
imagePath = imagePath.substring(1);
}
System.out.println("imagePath:"+imagePath);
File file = new File(imagePath);
//图片转图片流
BufferedImage img = ImageIO.read(file);
// 这里对图片黑白处理,增强识别率.这里先通过截图,截取图片中需要识别的部分
img = ImageHelper.convertImageToGrayscale(img);
// 图片锐化,自己使用中影响识别率的主要因素是针式打印机字迹不连贯,所以锐化反而降低识别率
img = ImageHelper.convertImageToBinary(img);
// 图片放大5倍,增强识别率(很多图片本身无法识别,放大7倍时就可以轻易识,但是考滤到客户电脑配置低,针式打印机打印不连贯的问题,这里就放大7倍)
img = ImageHelper.getScaledInstance(img, img.getWidth() * 7, img.getHeight() * 7);
// 创建ITesseract对象
ITesseract instance = new Tesseract();
//设置训练库的位置
String path = ClassLoader.getSystemResource("tessdata").getPath();
if (path.length()>0){
path = path.substring(1);
}
//打印一下路径,看有没有问题
System.out.println("tessdata:"+path);
instance.setDatapath(path);
//chi_sim :简体中文, eng 根据需求选择语言库
instance.setLanguage("eng");
String result = null;
try {
long startTime = System.currentTimeMillis();
result = instance.doOCR(file);
long endTime = System.currentTimeMillis();
System.out.println("Time is:" + (endTime - startTime) + " 毫秒");
} catch (TesseractException e) {
e.printStackTrace();
}
System.out.println("result: "+result);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号