机器学习中梯度下降法和牛顿法的比较
在机器学习的优化问题中,梯度下降法和牛顿法是常用的两种凸函数求极值的方法,他们都是为了求得目标函数的近似解。在逻辑斯蒂回归模型的参数求解中,一般用改良的梯度下降法,也可以用牛顿法。由于两种方法有些相似,我特地拿来简单地对比一下。下面的内容需要读者之前熟悉两种算法。
梯度下降法
梯度下降法用来求解目标函数的极值。这个极值是给定模型给定数据之后在参数空间中搜索找到的。迭代过程为:
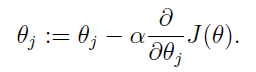
可以看出,梯度下降法更新参数的方式为目标函数在当前参数取值下的梯度值,前面再加上一个步长控制参数alpha。梯度下降法通常用一个三维图来展示,迭代过程就好像在不断地下坡,最终到达坡底。为了更形象地理解,也为了和牛顿法比较,这里我用一个二维图来表示:
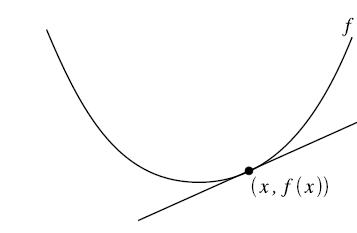
懒得画图了直接用这个展示一下。在二维图中,梯度就相当于凸函数切线的斜率,横坐标就是每次迭代的参数,纵坐标是目标函数的取值。每次迭代的过程是这样:
- 首先计算目标函数在当前参数值的斜率(梯度),然后乘以步长因子后带入更新公式,如图点所在位置(极值点右边),此时斜率为正,那么更新参数后参数减小,更接近极小值对应的参数。
- 如果更新参数后,当前参数值仍然在极值点右边,那么继续上面更新,效果一样。
- 如果更新参数后,当前参数值到了极值点的左边,然后计算斜率会发现是负的,这样经过再一次更新后就会又向着极值点的方向更新。
根据这个过程我们发现,每一步走的距离在极值点附近非常重要,如果走的步子过大,容易在极值点附近震荡而无法收敛。解决办法:将alpha设定为随着迭代次数而不断减小的变量,但是也不能完全减为零。
梯度下降法的缺点:
(1)靠近极小值时收敛速度减慢;
(2)直线搜索时可能会产生一些问题;
(3)可能会“之字形”地下降。
梯度下降的算法调优:
在使用梯度下降时,需要进行调优。哪些地方需要调优呢?
1. 算法的步长选择。在前面的算法描述中,我提到取步长为1,但是实际上取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否则要增大步长。前面说了。步长太大,会导致迭代过快,甚至有可能错过最优解。步长太小,迭代速度太慢,很长时间算法都不能结束。所以算法的步长需要多次运行后才能得到一个较为优的值。
2. 算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
3.归一化。由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据归一化,也就是对于每个特征x,求出它的期望x¯¯¯和标准差std(x),然后转化为: 这样特征的新期望为0,新方差为1,迭代次数可以大大加快。
这样特征的新期望为0,新方差为1,迭代次数可以大大加快。
牛顿法
首先得明确,牛顿法是为了求解函数值为零的时候变量的取值问题的,具体地,当要求解 f(θ)=0时,如果 f可导,那么可以通过迭代公式

来迭代求得最小值。通过一组图来说明这个过程。
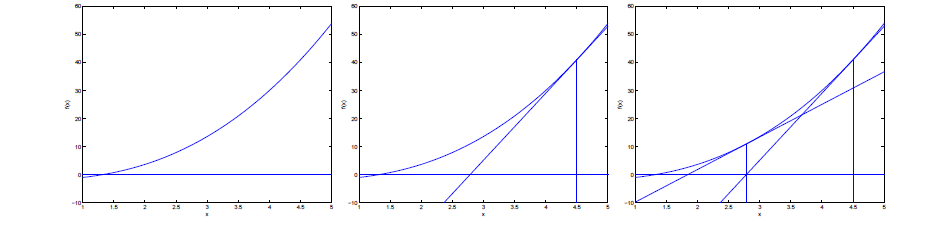
当应用于求解最大似然估计的值时,变成ℓ′(θ)=0的问题。这个与梯度下降不同,梯度下降的目的是直接求解目标函数极小值,而牛顿法则变相地通过求解目标函数一阶导为零的参数值,进而求得目标函数最小值。那么迭代公式写作:
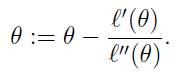
当θ是向量时,牛顿法可以使用下面式子表示:
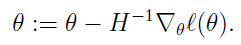
其中H叫做海森矩阵,其实就是目标函数对参数θ的二阶导数。
通过比较牛顿法和梯度下降法的迭代公式,可以发现两者及其相似。海森矩阵的逆就好比梯度下降法的学习率参数alpha。牛顿法收敛速度相比梯度下降法很快,而且由于海森矩阵的的逆在迭代中不断减小,起到逐渐缩小步长的效果。
牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号