利用python进行数据分析3_Pandas的数据结构
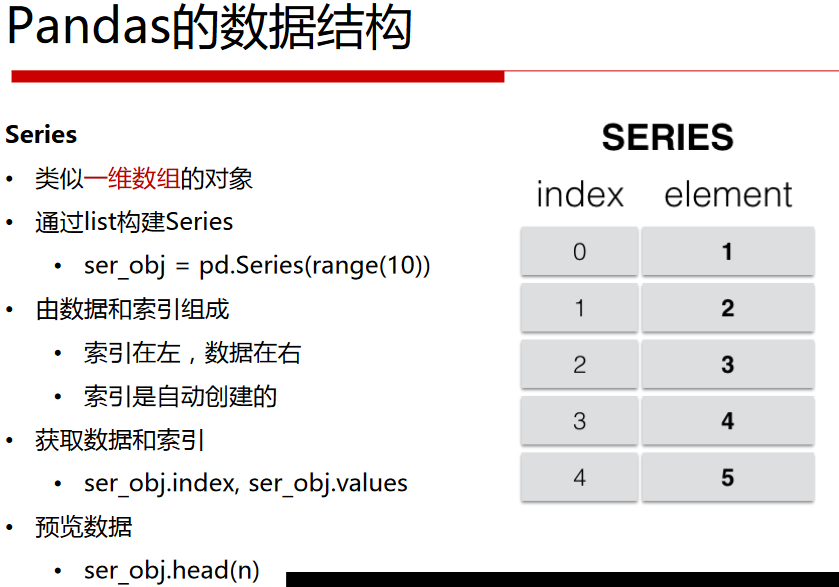

Series
#通过list构建Series ser_obj=pd.Series(range(10,20)) print(type(ser_obj))#<class 'pandas.core.series.Series'>
#获取数据 print(ser_obj) print(ser_obj.values) print(type(ser_obj.values))
结果:


0 10 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19 dtype: int64 [10 11 12 13 14 15 16 17 18 19] <class 'numpy.ndarray'>
#获取索引 print(ser_obj.index)#RangeIndex(start=0, stop=10, step=1) print(type(ser_obj.index))#<class 'pandas.core.indexes.range.RangeIndex'>
#预览数据 print(ser_obj.head())#默认五行 print(ser_obj.head(3))#指定行数
结果:
0 10 1 11 2 12 3 13 4 14 dtype: int64 0 10 1 11 2 12 dtype: int64
#通过索引获取数据 print(ser_obj[0],ser_obj[8])#10 18
#索引与数据的对应关系仍保持在数组运算的结果中 print(ser_obj) print(ser_obj * 2) print(ser_obj > 15) print(ser_obj[ser_obj>15])
结果:
0 10 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19 dtype: int64 0 20 1 22 2 24 3 26 4 28 5 30 6 32 7 34 8 36 9 38 dtype: int64 0 False 1 False 2 False 3 False 4 False 5 False 6 True 7 True 8 True 9 True dtype: bool 6 16 7 17 8 18 9 19 dtype: int64
#通过dict构建Series
year_data={2001:17.8,2002:20.1,2003:16.5}
ser_obj2=pd.Series(year_data)
print(ser_obj2.head())
print(ser_obj2.index)
结果:
2001 17.8 2002 20.1 2003 16.5 dtype: float64 Int64Index([2001, 2002, 2003], dtype='int64')
#name属性 ser_obj2.name='temp' ser_obj2.index.name='year' # ser_obj2.values.name='值' 错误,不能给value赋名称 print(ser_obj2.index) print(ser_obj2.values) print(ser_obj2)
结果:
Int64Index([2001, 2002, 2003], dtype='int64', name='year') [17.8 20.1 16.5] year 2001 17.8 2002 20.1 2003 16.5 Name: temp, dtype: float64
DataFrame



import pandas as pd import numpy as np #通过ndarray构建DataFrame array=np.random.randn(5,4) print(array) df_obj=pd.DataFrame(array) print(df_obj.head())
结果:
[[ 0.6549588 -1.54224015 -0.14999869 -0.02010829] [-1.17871831 -0.41145691 1.72953394 1.52199536] [-1.11045884 0.11630374 -0.47437868 1.15345331] [-0.5421357 -0.81128728 -0.8076857 -0.84545337] [ 0.16660809 0.59636555 -0.5818692 0.42741729]] 0 1 2 3 0 0.654959 -1.542240 -0.149999 -0.020108 1 -1.178718 -0.411457 1.729534 1.521995 2 -1.110459 0.116304 -0.474379 1.153453 3 -0.542136 -0.811287 -0.807686 -0.845453 4 0.166608 0.596366 -0.581869 0.427417
#通过dict构建DataFrame
dict_data={'A':1,
'B':pd.Timestamp('20180321'),
'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='int32'),
'E':pd.Categorical(['python','java','c++','c#']),
'F':'ChinaHadoop'}
print(dict_data)
df_obj2=pd.DataFrame(dict_data)
print(df_obj2)
结果:
{'A': 1, 'B': Timestamp('2018-03-21 00:00:00'), 'C': 0 1.0
1 1.0
2 1.0
3 1.0
dtype: float32, 'D': array([3, 3, 3, 3]), 'E': [python, java, c++, c#]
Categories (4, object): [c#, c++, java, python], 'F': 'ChinaHadoop'}
A B C D E F
0 1 2018-03-21 1.0 3 python ChinaHadoop
1 1 2018-03-21 1.0 3 java ChinaHadoop
2 1 2018-03-21 1.0 3 c++ ChinaHadoop
3 1 2018-03-21 1.0 3 c# ChinaHadoop
#通过列索引获取列数据 print(df_obj2['A']) print(type(df_obj2['A'])) print(df_obj2.A)#尽量少用此方法,缺陷是:'A '(后边用空格)则本方法不适合
结果:
0 1 1 1 2 1 3 1 Name: A, dtype: int64 <class 'pandas.core.series.Series'> 0 1 1 1 2 1 3 1 Name: A, dtype: int64
#增加列 df_obj2['G']=df_obj2['D']+4 print(df_obj2.head())
结果:
A B C D E F G 0 1 2018-03-21 1.0 3 python ChinaHadoop 7 1 1 2018-03-21 1.0 3 java ChinaHadoop 7 2 1 2018-03-21 1.0 3 c++ ChinaHadoop 7 3 1 2018-03-21 1.0 3 c# ChinaHadoop 7
#删除列 del(df_obj2['G']) print(df_obj2.head())
结果:
A B C D E F 0 1 2018-03-21 1.0 3 python ChinaHadoop 1 1 2018-03-21 1.0 3 java ChinaHadoop 2 1 2018-03-21 1.0 3 c++ ChinaHadoop 3 1 2018-03-21 1.0 3 c# ChinaHadoop
索引对象 Index
print(type(ser_obj.index)) print(type(df_obj2.index)) print(df_obj2.index)
结果:
<class 'pandas.core.indexes.range.RangeIndex'> <class 'pandas.core.indexes.numeric.Int64Index'> Int64Index([0, 1, 2, 3], dtype='int64')
# 索引对象不可变 df_obj2.index[0] = 2
结果:
TypeError Traceback (most recent call last) <ipython-input-16-6367894e76d8> in <module>() 1 # 索引对象不可变 ----> 2 df_obj2.index[0] = 2 d:\Anaconda3\lib\site-packages\pandas\core\indexes\base.py in __setitem__(self, key, value) 1722 1723 def __setitem__(self, key, value): -> 1724 raise TypeError("Index does not support mutable operations") 1725 1726 def __getitem__(self, key): TypeError: Index does not support mutable operations

Series索引
import pandas as pd ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e']) print(ser_obj.head())
结果:
a 0 b 1 c 2 d 3 e 4 dtype: int32
# 行索引 print(ser_obj['a'])#0 print(ser_obj[0])#0
# 切片索引 print(ser_obj[1:3])#不包含终止索引 print(ser_obj['b':'d'])#包含终止索引
结果:
b 1 c 2 dtype: int32 b 1 c 2 d 3 dtype: int32
# 不连续索引 print(ser_obj[[0, 2, 4]])#里边是个list print(ser_obj[['a', 'e']])#里边是个list
结果:
a 0 c 2 e 4 dtype: int32 a 0 e 4 dtype: int32
# 布尔索引 ser_bool = ser_obj > 2 print(ser_bool) print(ser_obj[ser_bool]) print(ser_obj[ser_obj > 2])
结果:
a False b False c False d True e True dtype: bool d 3 e 4 dtype: int32 d 3 e 4 dtype: int32
DataFrame索引
import numpy as np import pandas as pd df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd']) print(df_obj.head())
结果:
a b c d
0 -0.595692 0.813699 -0.551327 -0.059703
1 0.339194 -2.335579 0.230472 -0.680213
2 -0.252306 0.212406 -0.979523 0.408522
3 0.216677 0.574524 -0.819607 2.170009
4 -1.099175 -0.665488 0.391421 -0.400642

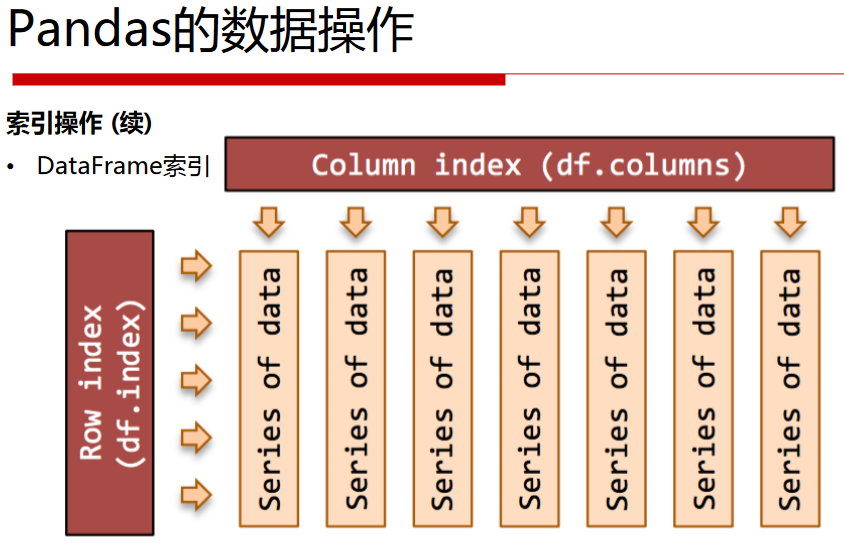
# 列索引
print('列索引')
print(df_obj['a']) # 返回Series类型
print(type(df_obj['a'])) # 返回Series类型
# 不连续索引
print('不连续索引')
print(df_obj[['a','c']])
print(type(df_obj[['a','c']])) # 返回DataFrame类型
结果:
列索引 0 -0.642820 1 1.734779 2 1.336593 3 -0.006249 4 0.456089 Name: a, dtype: float64 <class 'pandas.core.series.Series'> 不连续索引 a c 0 -0.642820 -0.491729 1 1.734779 -0.103878 2 1.336593 1.113933 3 -0.006249 0.922524 4 0.456089 -0.632876 <class 'pandas.core.frame.DataFrame'>

三种索引方式
# 标签索引 loc # Series print(ser_obj) print(ser_obj['b':'d'])#包含终止索引 print(ser_obj.loc['b':'d'])#包含终止索引 # DataFrame print(df_obj['a']) print(df_obj.loc[0:2, 'a'])#包含终止索引
结果:
a 0 b 1 c 2 d 3 e 4 dtype: int64 b 1 c 2 d 3 dtype: int64 b 1 c 2 d 3 dtype: int64 0 -0.630555 1 0.681242 2 -0.990568 3 1.596795 4 0.470956 Name: a, dtype: float64 0 -0.630555 1 0.681242 2 -0.990568 Name: a, dtype: float64
# 整型位置索引 iloc print(ser_obj) print(ser_obj[1:3])#不包含终止索引 print(ser_obj.iloc[1:3])#不包含终止索引 # DataFrame print(df_obj.iloc[0:2, 0]) # 注意和df_obj.loc[0:2, 'a']的区别 print(df_obj.iloc[0:2, 0:1])#不包含终止索引
结果:
a 0 b 1 c 2 d 3 e 4 dtype: int64 b 1 c 2 dtype: int64 b 1 c 2 dtype: int64 0 0.808593 1 -1.511858 Name: a, dtype: float64 a 0 0.808593 1 -1.511858
# 混合索引 ix 先按标签索引尝试操作,然后再按位置索引尝试操作(位置所以不包含终止索引) print(ser_obj.ix[1:3]) print(ser_obj.ix['b':'c']) # DataFrame print(df_obj.ix[0:2, 0]) # 先按标签索引尝试操作,然后再按位置索引尝试操作
结果:
b 1 c 2 dtype: int32 b 1 c 2 dtype: int32 0 -0.595692 1 0.339194 2 -0.252306 Name: a, dtype: float64

运算与对齐
s1 = pd.Series(range(10, 20), index = range(10))
s2 = pd.Series(range(20, 25), index = range(5))
print('s1: ' )
print(s1)
print('')
print('s2: ')
print(s2)
结果:
s1: 0 10 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19 dtype: int64 s2: 0 20 1 21 2 22 3 23 4 24 dtype: int64
# Series 对齐运算 s1 + s2
结果:
0 30.0 1 32.0 2 34.0 3 36.0 4 38.0 5 NaN 6 NaN 7 NaN 8 NaN 9 NaN dtype: float64
import numpy as np
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b'])
df2 = pd.DataFrame(np.ones((3,3)), columns = ['a', 'b', 'c'])
print('df1: ')
print(df1)
print('')
print('df2: ')
print(df2)
结果:
df1: a b 0 1.0 1.0 1 1.0 1.0 df2: a b c 0 1.0 1.0 1.0 1 1.0 1.0 1.0 2 1.0 1.0 1.0
# DataFrame对齐操作 df1 + df2
结果:
| a | b | c | |
|---|---|---|---|
| 0 | 2.0 | 2.0 | NaN |
| 1 | 2.0 | 2.0 | NaN |
| 2 | NaN | NaN | NaN |
# 填充未对齐的数据进行运算 print(s1) print(s2) s1.add(s2, fill_value = -1)
结果:
0 10 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19 dtype: int32 0 20 1 21 2 22 3 23 4 24 dtype: int32 0 30.0 1 32.0 2 34.0 3 36.0 4 38.0 5 14.0 6 15.0 7 16.0 8 17.0 9 18.0 dtype: float64
df1.sub(df2, fill_value = 2.)#不会改变df1的值
结果:
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 0.0 | 1.0 |
| 1 | 0.0 | 0.0 | 1.0 |
| 2 | 1.0 | 1.0 | 1.0 |
# 填充NaN s3 = s1 + s2 print(s3)
结果:
0 30.0 1 32.0 2 34.0 3 36.0 4 38.0 5 NaN 6 NaN 7 NaN 8 NaN 9 NaN dtype: float64
s3_filled = s3.fillna(-1) print(s3_filled)
结果:
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 -1.0
6 -1.0
7 -1.0
8 -1.0
9 -1.0
dtype: float64
df3 = df1 + df2 print(df3)
结果:
a b c 0 2.0 2.0 NaN 1 2.0 2.0 NaN 2 NaN NaN NaN
df3.fillna(100, inplace = True) print(df3)
结果:
a b c
0 2.0 2.0 100.0
1 2.0 2.0 100.0
2 100.0 100.0 100.0

函数应用
# Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) print(df) print(np.abs(df))
结果:
0 1 2 3 0 -2.193022 -2.090432 -2.288651 -0.026022 1 -0.720957 -1.501025 -1.734828 -1.858286 2 0.300216 -3.391127 -0.872570 -0.686669 3 -2.552131 -1.452268 -1.188845 -0.597845 4 2.111044 -1.203676 -1.143487 -0.542755 0 1 2 3 0 2.193022 2.090432 2.288651 0.026022 1 0.720957 1.501025 1.734828 1.858286 2 0.300216 3.391127 0.872570 0.686669 3 2.552131 1.452268 1.188845 0.597845 4 2.111044 1.203676 1.143487 0.542755
# 使用apply应用行或列数据 #f = lambda x : x.max() print(df.apply(lambda x : x.max()))#默认 axis=0 每一列最大值
结果:
0 2.111044
1 -1.203676
2 -0.872570
3 -0.026022
dtype: float64
# 指定轴方向 print(df.apply(lambda x : x.max(), axis=1))#每一行最大值
结果:
0 -0.026022
1 -0.720957
2 0.300216
3 -0.597845
4 2.111044
dtype: float64
def f(x):
return x.max()
print(df.apply(f))#f后边不写括号
结果:
0 -0.113548
1 0.396976
2 -0.444515
3 -0.238868
dtype: float64
# 使用applymap应用到每个数据 f2 = lambda x : '%.2f' % x print(df.applymap(f2))
结果:
0 1 2 3
0 -2.19 -2.09 -2.29 -0.03
1 -0.72 -1.50 -1.73 -1.86
2 0.30 -3.39 -0.87 -0.69
3 -2.55 -1.45 -1.19 -0.60
4 2.11 -1.20 -1.14 -0.54

排序
s4 = pd.Series(range(10, 15), index = np.random.randint(5, size=5)) print(s4)
结果:
4 10
3 11
1 12
4 13
4 14
dtype: int32
# 索引排序 s4.sort_index()
结果:
1 12
3 11
4 10
4 13
4 14
dtype: int32
df4 = pd.DataFrame(np.random.randn(3, 4),
index=np.random.randint(3, size=3),
columns=np.random.randint(4, size=4))
print(df4)
结果:
3 2 2 1 2 0.244068 -1.977220 0.045238 -2.064546 2 0.218196 -0.419284 -0.698839 0.241649 2 0.296747 -0.021311 0.225724 -0.325439
#df4.sort_index(ascending=False) df4.sort_index(axis=1)
结果:
| 1 | 2 | 2 | 3 | |
|---|---|---|---|---|
| 2 | -2.064546 | -1.977220 | 0.045238 | 0.244068 |
| 2 | 0.241649 | -0.419284 | -0.698839 | 0.218196 |
| 2 | -0.325439 | -0.021311 | 0.225724 | 0.296747 |
# 按值排序 df4.sort_values(by=1)
结果:
| 3 | 2 | 2 | 1 | |
|---|---|---|---|---|
| 2 | 0.244068 | -1.977220 | 0.045238 | -2.064546 |
| 2 | 0.296747 | -0.021311 | 0.225724 | -0.325439 |
| 2 | 0.218196 | -0.419284 | -0.698839 | 0.241649 |

处理缺失数据
df_data = pd.DataFrame([np.random.randn(3), [1., np.nan, np.nan],
[4., np.nan, np.nan], [1., np.nan, 2.]])
df_data.head()
结果:
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1.619463 | 0.548047 | -1.027003 |
| 1 | 1.000000 | NaN | NaN |
| 2 | 4.000000 | NaN | NaN |
| 3 | 1.000000 | NaN | 2.000000 |
# isnull df_data.isnull()
结果:
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | False | False | False |
| 1 | False | True | True |
| 2 | False | True | True |
| 3 | False | True | False |
# dropna df_data.dropna() #df_data.dropna(axis=1)
结果:
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1.619463 | 0.548047 | -1.027003 |
# fillna df_data.fillna(-100.)
结果:
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | -1.095289 | -1.064722 | 0.065256 |
| 1 | 1.000000 | -100.000000 | -100.000000 |
| 2 | 4.000000 | -100.000000 | -100.000000 |
| 3 | 1.000000 | -100.000000 | 2.000000 |
Pandas统计计算和描述

import numpy as np import pandas as pd
常用的统计计算
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd']) df_obj
结果:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0.715594 | 0.123322 | -0.628493 | -0.103682 |
| 1 | 0.783228 | 0.140333 | -0.211933 | -1.403887 |
| 2 | -0.713423 | -1.483364 | 0.276417 | -0.664303 |
| 3 | 1.580704 | -0.053138 | 0.562683 | -0.424985 |
| 4 | 2.046556 | -1.600219 | 0.021936 | 0.320219 |
df_obj.sum()
结果:
a 4.412658 b -2.873065 c 0.020610 d -2.276637 dtype: float64
df_obj.max()
结果:
a 2.046556 b 0.140333 c 0.562683 d 0.320219 dtype: float64
df_obj.min(axis=1)
结果:
0 -0.628493
1 -1.403887
2 -1.483364
3 -0.424985
4 -1.600219
dtype: float64
统计描述


df_obj.describe()
结果:
| a | b | c | d | |
|---|---|---|---|---|
| count | 5.000000 | 5.000000 | 5.000000 | 5.000000 |
| mean | 0.882532 | -0.574613 | 0.004122 | -0.455327 |
| std | 1.052045 | 0.887115 | 0.456436 | 0.646042 |
| min | -0.713423 | -1.600219 | -0.628493 | -1.403887 |
| 25% | 0.715594 | -1.483364 | -0.211933 | -0.664303 |
| 50% | 0.783228 | -0.053138 | 0.021936 | -0.424985 |
| 75% | 1.580704 | 0.123322 | 0.276417 | -0.103682 |
| max | 2.046556 | 0.140333 | 0.562683 | 0.320219 |

Pandas层级索引
import pandas as pd
import numpy as np
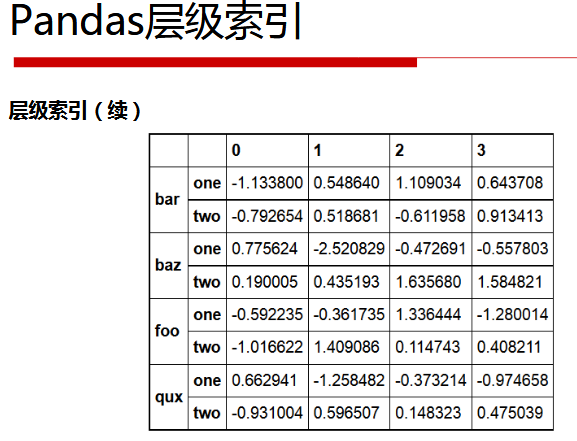
ser_obj = pd.Series(np.random.randn(12),
index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],
[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]])
print(ser_obj)
结果:
a 0 0.078539 1 0.643005 2 1.254099 b 0 0.569994 1 -1.267482 2 -0.751972 c 0 2.579259 1 0.566795 2 -0.796418 d 0 1.444369 1 -0.013740 2 -1.541993 dtype: float64
MultiIndex索引对象
print(type(ser_obj.index)) print(ser_obj.index)
结果:
<class 'pandas.indexes.multi.MultiIndex'> MultiIndex(levels=[['a', 'b', 'c', 'd'], [0, 1, 2]], labels=[[0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3], [0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]])
选取子集
# 外层选取 print(ser_obj['c'])
结果:
0 2.579259
1 0.566795
2 -0.796418
dtype: float64
# 内层选取 print(ser_obj[:, 2])
结果:
a 1.254099 b -0.751972 c -0.796418 d -1.541993 dtype: float64
交换分层顺序
print(ser_obj.swaplevel())
结果:
0 a 0.078539 1 a 0.643005 2 a 1.254099 0 b 0.569994 1 b -1.267482 2 b -0.751972 0 c 2.579259 1 c 0.566795 2 c -0.796418 0 d 1.444369 1 d -0.013740 2 d -1.541993 dtype: float64
交换并排序分层
print(ser_obj.swaplevel().sortlevel())
结果:
0 a 0.078539 b 0.569994 c 2.579259 d 1.444369 1 a 0.643005 b -1.267482 c 0.566795 d -0.013740 2 a 1.254099 b -0.751972 c -0.796418 d -1.541993 dtype: float64



分组与聚合
GroupBy对象
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print(df_obj)
结果:
data1 data2 key1 key2 0 -0.943078 0.820645 a one 1 -1.429043 0.142617 b one 2 0.832261 0.843898 a two 3 0.906262 0.688165 b three 4 0.541173 0.117232 a two 5 -0.213385 -0.098734 b two 6 -1.291468 -1.186638 a one 7 1.186941 0.809122 a three
# dataframe根据key1进行分组
print(type(df_obj.groupby('key1')))
结果:
<class 'pandas.core.groupby.DataFrameGroupBy'>
# data1列根据key1进行分组 print(type(df_obj['data1'].groupby(df_obj['key1'])))
结果:
<class 'pandas.core.groupby.SeriesGroupBy'>
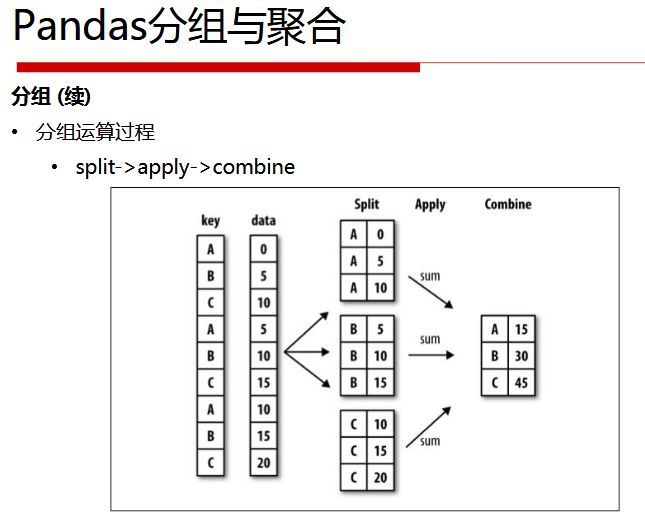
# 分组运算
grouped1 = df_obj.groupby('key1')
print(grouped1.mean())
grouped2 = df_obj['data1'].groupby(df_obj['key1'])
print(grouped2.mean())
结果:
data1 data2 key1 a 0.065166 0.280852 b -0.245389 0.244016 key1 a 0.065166 b -0.245389 Name: data1, dtype: float64
# size 查看分组结果中的个数 print(grouped1.size()) print(grouped2.size())
结果:
key1 a 5 b 3 dtype: int64 key1 a 5 b 3 dtype: int64
# 按列名分组
df_obj.groupby('key1')
结果:
<pandas.core.groupby.DataFrameGroupBy object at 0x00000224B6DA5DD8>
# 按自定义key分组,列表 self_def_key = [1, 1, 2, 2, 2, 1, 1, 1] df_obj.groupby(self_def_key).size()
结果:
1 5
2 3
dtype: int64
# 按自定义key分组,多层列表 df_obj.groupby([df_obj['key1'], df_obj['key2']]).size()
结果:
key1 key2 a one 2 three 1 two 2 b one 1 three 1 two 1 dtype: int64
# 按多个列多层分组 grouped2 = df_obj.groupby(['key1', 'key2']) print(grouped2.size())
结果:
key1 key2 a one 2 three 1 two 2 b one 1 three 1 two 1 dtype: int64
# 多层分组按key的顺序进行 grouped3 = df_obj.groupby(['key2', 'key1']) print(grouped3.mean()) print() print(grouped3.mean().unstack())
结果:
data1 data2 key2 key1 one a -1.117273 -0.182997 b -1.429043 0.142617 three a 1.186941 0.809122 b 0.906262 0.688165 two a 0.686717 0.480565 b -0.213385 -0.098734 data1 data2 key1 a b a b key2 one -1.117273 -1.429043 -0.182997 0.142617 three 1.186941 0.906262 0.809122 0.688165 two 0.686717 -0.213385 0.480565 -0.098734

GroupBy对象分组迭代
# 单层分组
for group_name, group_data in grouped1:
print(group_name)
print(group_data)
结果:
a data1 data2 key1 key2 0 -0.943078 0.820645 a one 2 0.832261 0.843898 a two 4 0.541173 0.117232 a two 6 -1.291468 -1.186638 a one 7 1.186941 0.809122 a three b data1 data2 key1 key2 1 -1.429043 0.142617 b one 3 0.906262 0.688165 b three 5 -0.213385 -0.098734 b two
# 多层分组
for group_name, group_data in grouped2:
print(group_name)
print(group_data)
结果:
('a', 'one') data1 data2 key1 key2 0 -0.943078 0.820645 a one 6 -1.291468 -1.186638 a one ('a', 'three') data1 data2 key1 key2 7 1.186941 0.809122 a three ('a', 'two') data1 data2 key1 key2 2 0.832261 0.843898 a two 4 0.541173 0.117232 a two ('b', 'one') data1 data2 key1 key2 1 -1.429043 0.142617 b one ('b', 'three') data1 data2 key1 key2 3 0.906262 0.688165 b three ('b', 'two') data1 data2 key1 key2 5 -0.213385 -0.098734 b two
# GroupBy对象转换list list(grouped1)
结果:
[('a', data1 data2 key1 key2 0 -0.943078 0.820645 a one 2 0.832261 0.843898 a two 4 0.541173 0.117232 a two 6 -1.291468 -1.186638 a one 7 1.186941 0.809122 a three), ('b', data1 data2 key1 key2 1 -1.429043 0.142617 b one 3 0.906262 0.688165 b three 5 -0.213385 -0.098734 b two)]
# GroupBy对象转换dict dict(list(grouped1))
结果:
{'a': data1 data2 key1 key2
0 -0.943078 0.820645 a one
2 0.832261 0.843898 a two
4 0.541173 0.117232 a two
6 -1.291468 -1.186638 a one
7 1.186941 0.809122 a three, 'b': data1 data2 key1 key2
1 -1.429043 0.142617 b one
3 0.906262 0.688165 b three
5 -0.213385 -0.098734 b two}
# 按列分组
print(df_obj.dtypes)
print('-------------------')
# 按数据类型分组
print(df_obj.groupby(df_obj.dtypes, axis=1).size())
print('-------------------')
print(df_obj.groupby(df_obj.dtypes, axis=1).sum())
结果:
data1 float64 data2 float64 key1 object key2 object dtype: object ------------------- float64 2 object 2 dtype: int64 ------------------- float64 object 0 -0.186118 aone 1 -1.092694 bone 2 0.362797 atwo 3 1.281174 bthree 4 -0.853131 atwo 5 -1.619557 btwo 6 -0.210457 aone 7 1.539713 athree
其他分组方法
df_obj2 = pd.DataFrame(np.random.randint(1, 10, (5,5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['A', 'B', 'C', 'D', 'E'])
df_obj2.ix[1, 1:4] = np.NaN
df_obj2
结果:
| a | b | c | d | e | |
|---|---|---|---|---|---|
| A | 1 | 1.0 | 1.0 | 6.0 | 5 |
| B | 2 | NaN | NaN | NaN | 6 |
| C | 5 | 5.0 | 7.0 | 5.0 | 7 |
| D | 2 | 8.0 | 5.0 | 6.0 | 2 |
| E | 5 | 1.0 | 4.0 | 4.0 | 4 |
# 通过字典分组
mapping_dict = {'a':'python', 'b':'python', 'c':'java', 'd':'C', 'e':'java'}
print(df_obj2.groupby(mapping_dict, axis=1).size())
print(df_obj2.groupby(mapping_dict, axis=1).count()) # 非NaN的个数
print(df_obj2.groupby(mapping_dict, axis=1).sum())
结果:
C 1 java 2 python 2 dtype: int64 C java python A 1 2 2 B 0 1 1 C 1 2 2 D 1 2 2 E 1 2 2 C java python A 3.0 12.0 12.0 B 0.0 7.0 3.0 C 5.0 10.0 13.0 D 2.0 11.0 7.0 E 8.0 9.0 12.0
# 通过函数分组
df_obj3 = pd.DataFrame(np.random.randint(1, 10, (5,5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['AA', 'BBB', 'CC', 'D', 'EE'])
#df_obj3
def group_key(idx):
"""
idx 为列索引或行索引
"""
#return idx
return len(idx)#按照索引名称长度进行分组
df_obj3.groupby(group_key).size()
# 以上自定义函数等价于
#df_obj3.groupby(len).size()
结果:
1 1
2 3
3 1
dtype: int64
# 通过索引级别分组
columns = pd.MultiIndex.from_arrays([['Python', 'Java', 'Python', 'Java', 'Python'],
['A', 'A', 'B', 'C', 'B']], names=['language', 'index'])
df_obj4 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=columns)
df_obj4
结果:
| language | Python | Java | Python | Java | Python |
|---|---|---|---|---|---|
| index | A | A | B | C | B |
| 0 | 1 | 6 | 4 | 7 | 2 |
| 1 | 9 | 7 | 2 | 2 | 4 |
| 2 | 3 | 9 | 9 | 7 | 5 |
| 3 | 1 | 6 | 1 | 6 | 6 |
| 4 | 5 | 1 | 7 | 3 | 6 |
# 根据language进行分组 print(df_obj4.groupby(level='language', axis=1).sum()) print(df_obj4.groupby(level='index', axis=1).sum())
结果:
language Java Python 0 7 16 1 13 21 2 13 10 3 16 14 4 10 21 index A B C 0 12 9 2 1 14 15 5 2 9 9 5 3 17 5 8 4 12 16 3

聚合
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randint(1,10, 8),
'data2': np.random.randint(1,10, 8)}
df_obj5 = pd.DataFrame(dict_obj)
print(df_obj5)
结果:
data1 data2 key1 key2 0 4 2 a one 1 7 1 b one 2 2 8 a two 3 9 4 b three 4 3 2 a two 5 8 5 b two 6 6 8 a one 7 9 3 a three
# 内置的聚合函数
print(df_obj5.groupby('key1').sum())
print(df_obj5.groupby('key1').max())
print(df_obj5.groupby('key1').min())
print(df_obj5.groupby('key1').mean())
print(df_obj5.groupby('key1').size())
print(df_obj5.groupby('key1').count())
print(df_obj5.groupby('key1').describe())
结果:
data1 data2 key1 a 24 23 b 24 10 data1 data2 key2 key1 a 9 8 two b 9 5 two data1 data2 key2 key1 a 2 2 one b 7 1 one data1 data2 key1 a 4.8 4.600000 b 8.0 3.333333 key1 a 5 b 3 dtype: int64 data1 data2 key2 key1 a 5 5 5 b 3 3 3 data1 data2 key1 a count 5.000000 5.000000 mean 4.800000 4.600000 std 2.774887 3.130495 min 2.000000 2.000000 25% 3.000000 2.000000 50% 4.000000 3.000000 75% 6.000000 8.000000 max 9.000000 8.000000 b count 3.000000 3.000000 mean 8.000000 3.333333 std 1.000000 2.081666 min 7.000000 1.000000 25% 7.500000 2.500000 50% 8.000000 4.000000 75% 8.500000 4.500000 max 9.000000 5.000000
# 自定义聚合函数
def peak_range(df):
"""
返回数值范围
"""
#print type(df) #参数为索引所对应的记录
return df.max() - df.min()
print(df_obj5.groupby('key1').agg(peak_range))
print(df_obj.groupby('key1').agg(lambda df : df.max() - df.min()))
结果:
data1 data2 key1 a 7 6 b 2 4 data1 data2 key1 a 2.478410 2.030536 b 2.335305 0.786899


# 应用多个聚合函数
# 同时应用多个聚合函数
print(df_obj.groupby('key1').agg(['mean', 'std', 'count', peak_range])) # 默认列名为函数名
结果:
data1 data2 mean std count peak_range mean std count peak_range key1 a 0.065166 1.110226 5 2.478410 0.280852 0.875752 5 2.030536 b -0.245389 1.167982 3 2.335305 0.244016 0.403130 3 0.786899
print(df_obj.groupby('key1').agg(['mean', 'std', 'count', ('range', peak_range)])) # 通过元组提供新的列名
结果:
data1 data2 mean std count range mean std count range key1 a 0.065166 1.110226 5 2.478410 0.280852 0.875752 5 2.030536 b -0.245389 1.167982 3 2.335305 0.244016 0.403130 3 0.786899
# 每列作用不同的聚合函数
dict_mapping = {'data1':'mean',
'data2':'sum'}
print(df_obj.groupby('key1').agg(dict_mapping))
结果:
data2 data1 key1 a 1.404259 0.065166 b 0.732047 -0.245389
dict_mapping = {'data1':['mean','max'],
'data2':'sum'}
print(df_obj.groupby('key1').agg(dict_mapping))
结果:
data2 data1 sum mean max key1 a 1.404259 0.065166 1.186941 b 0.732047 -0.245389 0.906262