#python3默认是Unicode,Unicode是万国码,不管中文字符还是英文,所有的每个字符都占2个字节空间,16位
#python2默认是ascii码
#ascii码不能存中文,一个英文只能占一个字节,8位;utf-8是可变长的字符编码(可认为Unicode的扩展集),所有英文字符仍按ASCII码形式,即1个字节,所有中文字符按3个字节储存。gbk和gb2312两个字节表示一个中文。
#utf-8是Unicode的扩展集,Unicode格式写的内容在utf-8中不会乱码
#Python2用中文,要声明utf-8(# -*- coding:utf-8 -*- )或者gbk(# -*- coding:gbk -*- ),python3不用声明# -*- coding:utf-8 -*-
#有关编码这方面的内容看博客http://www.cnblogs.com/yuanchenqi/articles/5956943.html,一定要看
# utf-8(# -*- coding:utf-8 -*- )或者gbk(# -*- coding:gbk -*- )的声明只是说明的是文件编码
#打印系统默认编码
import sys
print sys.getdefaultencoding()
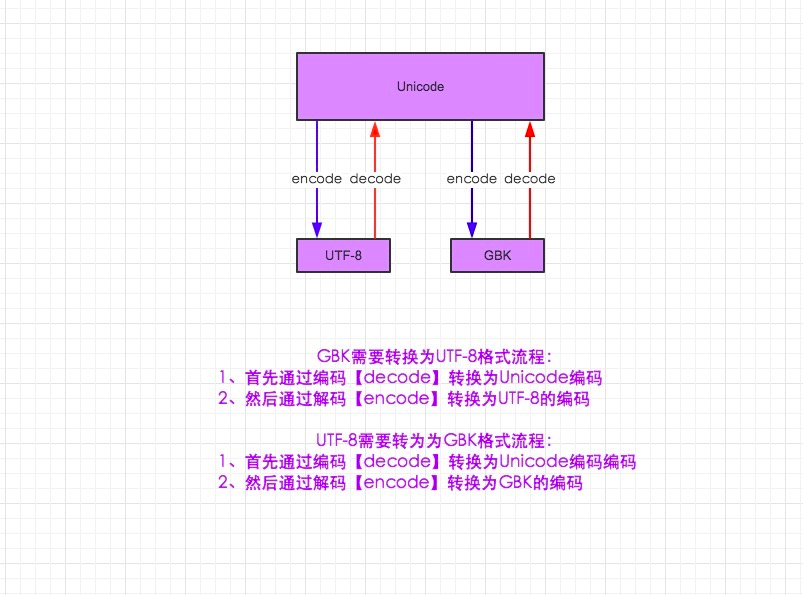
上图适用于Python2
#在Python2中
# -*- coding:utf-8 -*-
#utf-8变成gbk,也可变成gb2312
utf8= "我爱北京天安门"#utf-8格式
utf8_to_unicode = utf8.decode("utf-8")#先解码utf-8就变成Unicode格式
print utf8_to_unicode
utf8_to_unicode_to_gbk=utf8_to_unicode.encode("gbk")#再编码成gbk
print utf8_to_unicode_to_gbk
#gbk变成utf-8
gbk_to_utf8=utf8_to_unicode_to_gbk.decode("gbk").encode("utf-8")
print gbk_to_utf8
s=u'我前边加u表示我是Unicode字符串'#如果对Unicode字符串解码是解不出来的,产生错误,因为本身就是Unicode字符串。
print s#在utf-8环境中打印是正确的
s_to_gbk=s.encode('gbk')#unicode可以直接转成gbk,所有的进行转换之前都要解码成Unicode,本身就是Unicode的就不用解码了
