k-近邻算法
目录
一、概述
二、k-近邻算法的Python实现
1. 算法实现
2. 封装函数
三、k-近邻算法之约会网站配对效果判定
1. 准备数据
2. 分析数据
3. 数据归一化
4. 划分训练集和测试集
5. 分类器针对于约会网站的测试代码
四、算法总结
1. 优点
2. 缺点
一、概述
k-近邻算法(k-Nearest Neighbour algorithm),又称为KNN算法,是数据挖掘技术中原理最简单的算法。KNN的工作原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数据集中找到与新数据最邻近的k个实例,如果这k个实例的多数属于某个类别,那么新数据就属于这个类别。可以简单理解为:由那些离X最近的k个点来投票决定X归为哪一类。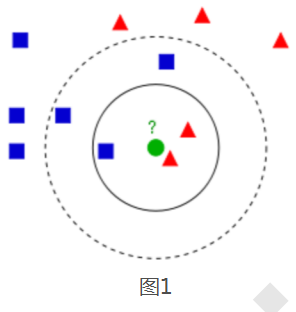
图1中有红色三角和蓝色方块两种类别,我们现在需要判断绿色圆点属于哪种类别:
(1)当k=3时,绿色圆点属于红色三角这种类别;
(2)当k=5时,绿色圆点属于蓝色方块这种类别。
举个简单的例子,可以用k-近邻算法分类一个电影是爱情片还是动作片。(打斗镜头和接吻镜头数量为虚构)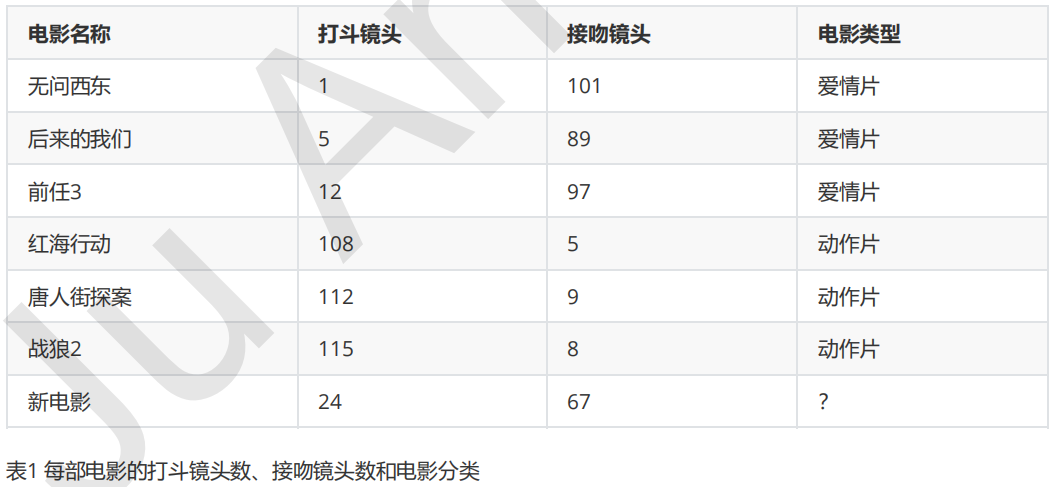
表1就是我们已有的数据集合,也就是训练样本集。这个数据集有两个特征——打斗镜头数和接吻镜头数。除此之外,我们也知道每部电影的所属类型,即分类标签。粗略看来,接吻镜头多的就是爱情片,打斗镜头多的就是动作片。以我们多年的经验来看,这个分类还算合理。如果现在给我一部新的电影,告诉我电影中的打斗镜头和接吻镜头分别是多少,那么我可以根据你给出的信息进行判断,这部电影是属于爱情片还是动作片。而k-近邻算法也可以像我们人一样做到这一点。但是,这仅仅是两个特征,如果把特征扩大到N个呢?我们人类还能凭经验“一眼看出”电影的所属类别吗?想想就知道这是一个非常困难的事情,但算法可以,这就是算法的魅力所在。
我们已经知道k-近邻算法的工作原理,根据特征比较,然后提取样本集中特征最相似数据(最近邻)的分类标签。那么如何进行比较呢?比如表1中新出的电影,我们该如何判断他所属的电影类别呢?如图2所示。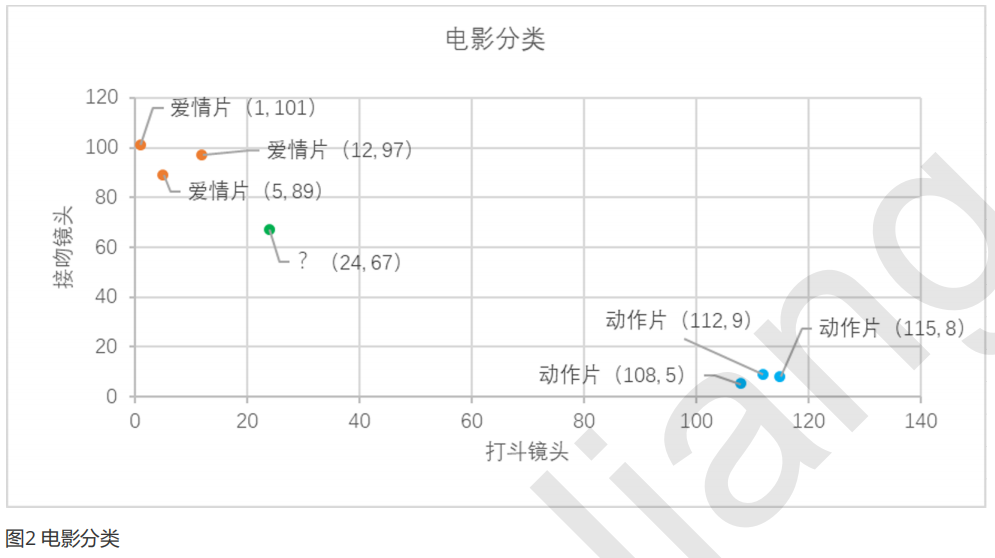
我们可以从散点图中大致推断,这个未知电影有可能是爱情片,因为看起来距离已知的三个爱情片更近一点。k-近邻算法是用什么方法进行判断呢?没错,就是距离度量。这个电影分类例子中有两个特征,也就是在二维平面中计算两点之间的距离,就可以用我们高中学过的距离计算公式: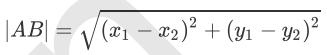 如果是多个特征扩展到N维空间,怎么计算?没错,我们可以使用欧氏距离(也称欧几里得度量),如下所示:
如果是多个特征扩展到N维空间,怎么计算?没错,我们可以使用欧氏距离(也称欧几里得度量),如下所示: 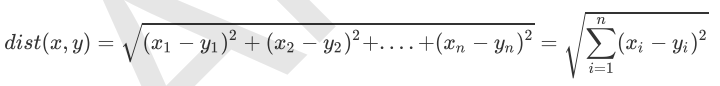
通过计算可以得到训练集中所有电影与未知电影的距离,如表2所示: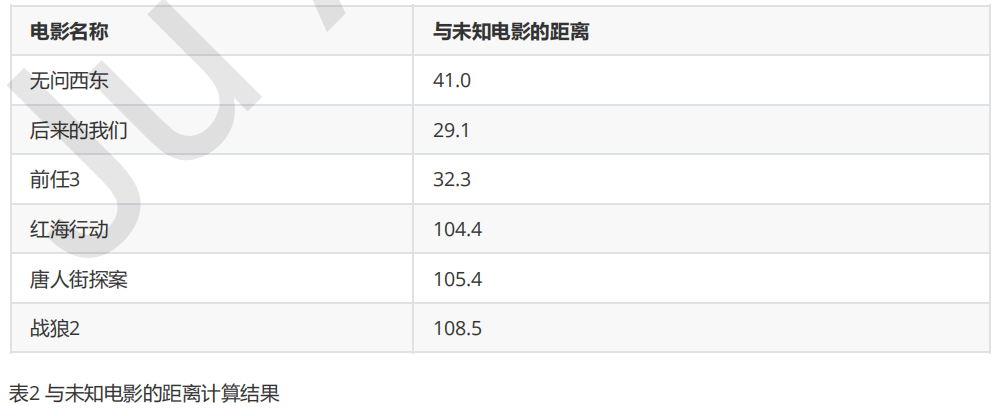
通过表2的计算结果,我们可以知道绿点标记的电影到爱情片《后来的我们》距离最近,为29.1。如果仅仅根据这个结果,判定绿点电影的类别为爱情片,这个算法叫做最近邻算法,而非k-近邻算法。k-近邻算法步骤如下:
(1) 计算已知类别数据集中的点与当前点之间的距离;
(2) 按照距离递增次序排序;
(3) 选取与当前点距离最小的k个点;
(4) 确定前k个点所在类别的出现频率;
(5) 返回前k个点出现频率最高的类别作为当前点的预测类别。
比如,现在K=4,那么在这个电影例子中,把距离按照升序排列,距离绿点电影最近的前4个的电影分别是《后来的我们》、《前任3》、《无问西东》和《红海行动》,这四部电影的类别统计为爱情片:动作片=3:1,出现频率最高的类别为爱情片,所以在k=4时,绿点电影的类别为爱情片。这个判别过程就是k-近邻算法。
二、k-近邻算法的Python实现
在了解k-近邻算法的原理及实施步骤之后,我们用python将这些过程实现。
1. 算法实现
1.1构建已经分类好的原始数据集
为了方便验证,这里使用python的字典dict构建数据集,然后再将其转化成DataFrame格式
#构建数据集
import pandas as pd
rowdata={'电影名称':['无问西东','后来的我们','前任3','红海行动','唐人街探案','战狼2'],
'打斗镜头':[1,5,12,108,112,115],
'接吻镜头':[101,89,97,5,9,8],
'电影类型':['爱情片','爱情片','爱情片','动作片','动作片','动作片']}
movie_data= pd.DataFrame(rowdata)
movie_data
结果:
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 | |
|---|---|---|---|---|
| 0 | 无问西东 | 1 | 101 | 爱情片 |
| 1 | 后来的我们 | 5 | 89 | 爱情片 |
| 2 | 前任3 | 12 | 97 | 爱情片 |
| 3 | 红海行动 | 108 | 5 | 动作片 |
| 4 | 唐人街探案 | 112 | 9 | 动作片 |
| 5 | 战狼2 | 115 | 8 | 动作片 |
1.2.计算已知类别数据集中的点与当前点之间的距离
#计算已知类别数据集中的点与当前点之间的距离 new_data = [24,67] dist = list((((movie_data.iloc[:6,1:3]-new_data)**2).sum(1))**0.5)
movie_data.iloc[:6,1:3]
结果:
| 打斗镜头 | 接吻镜头 | |
|---|---|---|
| 0 | 1 | 101 |
| 1 | 5 | 89 |
| 2 | 12 | 97 |
| 3 | 108 | 5 |
| 4 | 112 | 9 |
| 5 | 115 | 8 |
(movie_data.iloc[:6,1:3]-new_data)
结果:
| 打斗镜头 | 接吻镜头 | |
|---|---|---|
| 0 | -23 | 34 |
| 1 | -19 | 22 |
| 2 | -12 | 30 |
| 3 | 84 | -62 |
| 4 | 88 | -58 |
| 5 | 91 | -59 |
((movie_data.iloc[:6,1:3]-new_data)**2).sum(1)
结果:


0 1685
1 845
2 1044
3 10900
4 11108
5 11762
dtype: int64
list((((movie_data.iloc[:6,1:3]-new_data)**2).sum(1))**0.5)
结果:
[41.048751503547585, 29.068883707497267, 32.31098884280702, 104.4030650891055, 105.39449701004318, 108.45275469069469]
1.3.将距离升序排列,然后选取距离最小的k个点
#将距离升序排列,然后选取距离最小的k个点
k=4
dist_l = pd.DataFrame({'dist': dist, 'labels': (movie_data.iloc[:6, 3])})
dr = dist_l.sort_values(by = 'dist')[: k]
pd.DataFrame({'dist': dist, 'labels': (movie_data.iloc[:6, 3])})
结果:
| dist | labels | |
|---|---|---|
| 0 | 41.048752 | 爱情片 |
| 1 | 29.068884 | 爱情片 |
| 2 | 32.310989 | 爱情片 |
| 3 | 104.403065 | 动作片 |
| 4 | 105.394497 | 动作片 |
| 5 | 108.452755 | 动作片 |
dist_l.sort_values(by = 'dist')[:4]
结果:
| dist | labels | |
|---|---|---|
| 1 | 29.068884 | 爱情片 |
| 2 | 32.310989 | 爱情片 |
| 0 | 41.048752 | 爱情片 |
| 3 | 104.403065 | 动作片 |
1.4.确定前k个点所在类别的出现频率
#确定前k个点所在类别的出现频率 re = dr.loc[:,'labels'].value_counts() re
结果:
爱情片 3 动作片 1 Name: labels, dtype: int64
re.index[0]#'爱情片'
1.5.选择频率最高的类别作为当前点的预测类别
result = [] result.append(re.index[0]) result#['爱情片']
2. 封装函数
完整的流程已经实现了,下面我们需要将这些步骤封装成函数,方便我们后续的调用。
import pandas as pd
"""
函数功能:KNN分类器
参数说明:
inX:需要预测分类的数据集
dataSet:已知分类标签的数据集(训练集)
k:k-近邻算法参数,选择距离最小的k个点
返回:
result:分类结果
"""
def classify0(inX,dataSet,k):
result=[]
dist = list((((movie_data.iloc[:6,1:3]-new_data)**2).sum(1))**0.5)
dist_l = pd.DataFrame({'dist': dist, 'labels': (movie_data.iloc[:6, 3])})
dr = dist_l.sort_values(by = 'dist')[: k]
re = dr.loc[:,'labels'].value_counts()
result.append(re.index[0])
return result
测试函数运行结果:
inX = new_data dataSet = movie_data k= 4 classify0(inX,dataSet,k)#['爱情片']
这就是我们使用k-近邻算法构建的一个分类器,根据我们的“经验”可以看出,分类器给的答案还是比较符合我们的预期的。
学习到这里,有人可能会问:”分类器何种情况下会出错?“或者”分类器给出的答案是否永远都正确?“答案一定是否定的,分类器并不会得到百分百正确的结果,我们可以使用很多种方法来验证分类器的准确率。此外,分类器的性能也会受到很多因素的影响,比如k的取值就在很大程度上影响了分类器的预测结果,还有分类器的设置、原始数据集等等。为了测试分类器的效果,我们可以把原始数据集分为两部分,一部分用来训练算法(称为训练集),一部分用来测试算法的准确率(称为测试集)。同时,我们不难发现,k-近邻算法没有进行数据的训练,直接使用未知的数据与已知的数据进行比较,得到结果。因此,可以说,k-近邻算法不具有显式的学习过程。
三、k-近邻算法之约会网站配对效果
海伦一直使用在线约会网站寻找适合自己的约会对象,尽管约会网站会推荐不同的人选,但她并不是每一个都喜欢,经过一番总结,她发现曾经交往的对象可以分为三类:
- 不喜欢的人
- 魅力一般的人
- 极具魅力得人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,其中各字段分别为:
- 每年飞行常客里程
- 玩游戏视频所占时间比
- 每周消费冰淇淋公升数
1. 准备数据
#1.导入数据集
datingTest = pd.read_table('datingTestSet.txt',header=None)
datingTest.head()
结果:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 40920 | 8.326976 | 0.953952 | largeDoses |
| 1 | 14488 | 7.153469 | 1.673904 | smallDoses |
| 2 | 26052 | 1.441871 | 0.805124 | didntLike |
| 3 | 75136 | 13.147394 | 0.428964 | didntLike |
| 4 | 38344 | 1.669788 | 0.134296 | didntLike |
datingTest.shape#(1000, 4)
datingTest.info()
结果:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1000 entries, 0 to 999 Data columns (total 4 columns): 0 1000 non-null int64 1 1000 non-null float64 2 1000 non-null float64 3 1000 non-null object dtypes: float64(2), int64(1), object(1) memory usage: 31.3+ KB
2. 分析数据
使用 Matplotlib 创建散点图,查看各数据的分布情况。
%matplotlib inline import matplotlib as mpl import matplotlib.pyplot as plt
datingTest.shape[0]#1000 datingTest.iloc[1,-1]#'smallDoses'
datingTest.iloc[:,1]
结果:
0 8.326976 1 7.153469 2 1.441871 3 13.147394 4 1.669788 5 10.141740 6 6.830792 7 13.276369 8 8.631577 9 12.273169 10 3.723498 11 8.385879 12 4.875435 13 4.680098 14 15.299570 15 1.889461 16 7.516754 17 14.239195 18 0.000000 19 10.528555 20 3.540265 21 2.991551 22 5.297865 23 6.593803 24 2.816760 25 12.458258 26 0.000000 27 9.968648 28 1.364838 29 0.230453 ... 970 12.149747 971 9.149678 972 9.666576 973 3.620110 974 5.238800 975 14.715782 976 14.445740 977 13.609528 978 3.141585 979 0.000000 980 0.454750 981 0.510310 982 3.864171 983 6.724021 984 4.289375 985 0.000000 986 3.733617 987 2.002589 988 2.502627 989 6.382129 990 8.546741 991 2.694977 992 3.951256 993 9.856183 994 2.068962 995 3.410627 996 9.974715 997 10.650102 998 9.134528 999 7.882601 Name: 1, Length: 1000, dtype: float64
#把不同标签用颜色区分
Colors = []
for i in range(datingTest.shape[0]):
m = datingTest.iloc[i,-1]
if m=='didntLike':
Colors.append('black')
if m=='smallDoses':
Colors.append('orange')
if m=='largeDoses':
Colors.append('red')
#绘制两两特征之间的散点图
plt.rcParams['font.sans-serif']=['Simhei'] #图中字体设置为黑体
pl=plt.figure(figsize=(12,8))
fig1=pl.add_subplot(221)
plt.scatter(datingTest.iloc[:,1],datingTest.iloc[:,2],marker='.',c=Colors)
plt.xlabel('玩游戏视频所占时间比')
plt.ylabel('每周消费冰淇淋公升数')
fig2=pl.add_subplot(222)
plt.scatter(datingTest.iloc[:,0],datingTest.iloc[:,1],marker='.',c=Colors)
plt.xlabel('每年飞行常客里程')
plt.ylabel('玩游戏视频所占时间比')
fig3=pl.add_subplot(223)
plt.scatter(datingTest.iloc[:,0],datingTest.iloc[:,2],marker='.',c=Colors)
plt.xlabel('每年飞行常客里程')
plt.ylabel('每周消费冰淇淋公升数')
plt.show()
结果: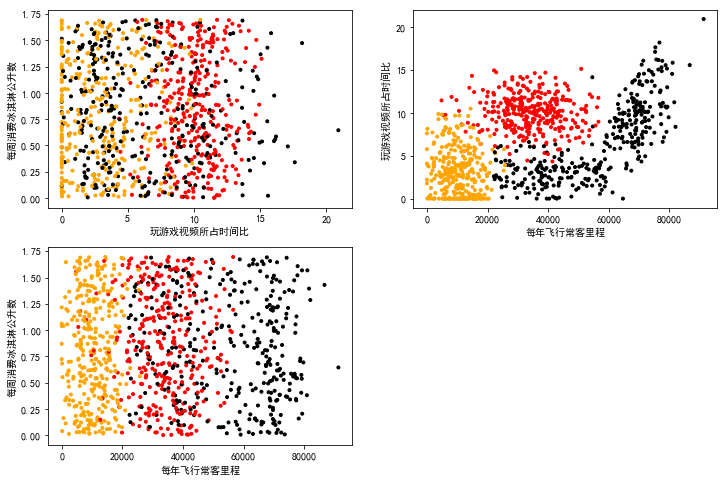
3. 数据归一化
下表是提取的4条样本数据,如果我们想要计算样本1和样本2之间的距离,可以使用欧几里得计算公式: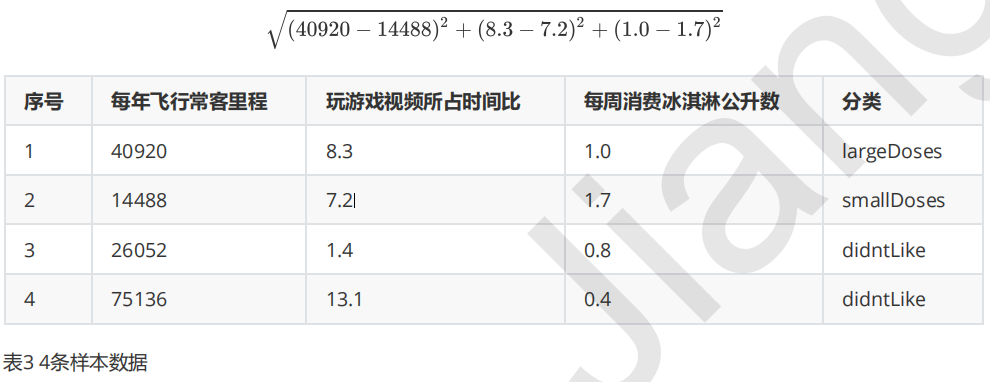
我们很容易发现,上面公式中差值最大的属性对计算结果的影响最大,也就是说每年飞行常客里程对计算结果的影响远远大于其他两个特征,原因仅仅是因为它的数值比较大,但是在海伦看来这三个特征是同等重要的,所以接下来我们要进行数值归一化的处理,使得这三个特征的权重相等。
数据归一化的处理方法有很多种,比如0-1标准化、Z-score标准化、Sigmoid压缩法等等,在这里我们使用最简单的0-1标准化,公式如下: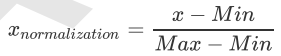
"""
函数功能:归一化
参数说明:
dataSet:原始数据集
返回:0-1标准化之后的数据集
"""
def minmax(dataSet):
minDf = dataSet.min()
maxDf = dataSet.max()
normSet = (dataSet - minDf )/(maxDf - minDf)
return normSet
将我们的数据集带入函数,进行归一化处理:
datingT = pd.concat([minmax(datingTest.iloc[:, :3]), datingTest.iloc[:,3]], axis=1) datingT.head()
结果:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0.448325 | 0.398051 | 0.562334 | largeDoses |
| 1 | 0.158733 | 0.341955 | 0.987244 | smallDoses |
| 2 | 0.285429 | 0.068925 | 0.474496 | didntLike |
| 3 | 0.823201 | 0.628480 | 0.252489 | didntLike |
| 4 | 0.420102 | 0.079820 | 0.078578 | didntLike |
4. 划分训练集和测试集
前面概述部分我们有提到,为了测试分类器的效果,我们可以把原始数据集分为训练集和测试集两部分,训练集用来训练模型,测试集用来验证模型准确率。
关于训练集和测试集的切分函数,网上一搜一大堆,Scikit Learn官网上也有相应的函数比如model_selection 类中的train_test_split 函数也可以完成训练集和测试集的切分。
通常来说,我们只提供已有数据的90%作为训练样本来训练模型,其余10%的数据用来测试模型。这里需要注意的10%的测试数据一定要是随机选择出来的,由于海伦提供的数据并没有按照特定的目的来排序,所以我们这里可以随意选择10%的数据而不影响其随机性。
"""
函数功能:切分训练集和测试集
参数说明:
dataSet:原始数据集
rate:训练集所占比例
返回:切分好的训练集和测试集
"""
def randSplit(dataSet,rate=0.9):
n = dataSet.shape[0]
m = int(n*rate)
train = dataSet.iloc[:m,:]
test = dataSet.iloc[m:,:]
test.index = range(test.shape[0])
return train,test
train,test = randSplit(datingT)
train
结果:
0 1 2 3 0 0.448325 0.398051 0.562334 largeDoses 1 0.158733 0.341955 0.987244 smallDoses 2 0.285429 0.068925 0.474496 didntLike 3 0.823201 0.628480 0.252489 didntLike 4 0.420102 0.079820 0.078578 didntLike 5 0.799722 0.484802 0.608961 didntLike 6 0.393851 0.326530 0.715335 largeDoses 7 0.467455 0.634645 0.320312 largeDoses 8 0.739507 0.412612 0.441536 didntLike 9 0.388757 0.586690 0.889360 largeDoses 10 0.550459 0.177993 0.490309 didntLike 11 0.693250 0.400867 0.984636 didntLike 12 0.061015 0.233059 0.429367 smallDoses 13 0.559333 0.223721 0.368321 didntLike 14 0.847699 0.731360 0.194879 didntLike 15 0.478488 0.090321 0.112212 didntLike 16 0.672313 0.359321 0.748369 didntLike 17 0.763347 0.680671 0.153555 didntLike 18 0.171672 0.000000 0.737168 smallDoses 19 0.312119 0.503293 0.769428 largeDoses 20 0.071072 0.169234 0.484741 smallDoses 21 0.413134 0.143004 0.491491 didntLike 22 0.247828 0.253252 0.376041 smallDoses 23 0.315340 0.315201 0.109748 largeDoses 24 0.216263 0.134649 0.994506 smallDoses 25 0.403055 0.595538 0.382717 largeDoses 26 0.062899 0.000000 0.976924 smallDoses 27 0.312984 0.476528 0.430886 largeDoses 28 0.074589 0.065243 0.377102 smallDoses 29 0.455896 0.011016 0.679218 didntLike ... ... ... ... ... 870 0.560253 0.087403 0.597598 didntLike 871 0.386335 0.483667 0.682090 largeDoses 872 0.468660 0.540643 0.050246 largeDoses 873 0.703286 0.398771 0.818841 didntLike 874 0.169119 0.011555 0.421646 smallDoses 875 0.157790 0.501097 0.999678 smallDoses 876 0.069473 0.444063 0.842632 smallDoses 877 0.154624 0.204089 0.078510 smallDoses 878 0.070010 0.000000 0.111133 smallDoses 879 0.096348 0.039060 0.084110 smallDoses 880 0.475847 0.072105 0.384508 didntLike 881 0.419993 0.447429 0.030162 largeDoses 882 0.373254 0.480528 0.324174 largeDoses 883 0.337657 0.531167 0.583112 largeDoses 884 0.243654 0.538543 0.426649 largeDoses 885 0.314715 0.496374 0.149720 largeDoses 886 0.625278 0.185406 0.812594 didntLike 887 0.793444 0.653904 0.014277 didntLike 888 0.309993 0.503211 0.460594 largeDoses 889 0.108422 0.000000 0.544773 smallDoses 890 0.721144 0.196312 0.640072 didntLike 891 0.083760 0.388103 0.867306 smallDoses 892 0.781052 0.372711 0.030206 didntLike 893 0.056183 0.133354 0.644440 smallDoses 894 0.150220 0.297665 0.168851 smallDoses 895 0.243665 0.486131 0.979099 largeDoses 896 0.165350 0.000000 0.808206 smallDoses 897 0.054967 0.359158 0.080380 smallDoses 898 0.111106 0.393932 0.058181 smallDoses 899 0.389710 0.698530 0.735519 largeDoses 900 rows × 4 columns
test
结果:
0 1 2 3 0 0.513766 0.170320 0.262181 didntLike 1 0.089599 0.154426 0.785277 smallDoses 2 0.611167 0.172689 0.915245 didntLike 3 0.012578 0.000000 0.195477 smallDoses 4 0.110241 0.187926 0.287082 smallDoses 5 0.812113 0.705201 0.681085 didntLike 6 0.729712 0.490545 0.960202 didntLike 7 0.130301 0.133239 0.926158 smallDoses 8 0.557755 0.722409 0.780811 largeDoses 9 0.437051 0.247835 0.131156 largeDoses 10 0.722174 0.184918 0.074908 didntLike 11 0.719578 0.167690 0.016377 didntLike 12 0.690193 0.526749 0.251657 didntLike 13 0.403745 0.182242 0.386039 didntLike 14 0.401751 0.528543 0.222839 largeDoses 15 0.425931 0.421948 0.590885 largeDoses 16 0.294479 0.534140 0.871767 largeDoses 17 0.506678 0.550039 0.248375 largeDoses 18 0.139811 0.372772 0.086617 largeDoses 19 0.386555 0.485440 0.807905 largeDoses 20 0.748370 0.508872 0.408589 didntLike 21 0.342511 0.461926 0.897321 largeDoses 22 0.380770 0.515810 0.774052 largeDoses 23 0.146900 0.134351 0.129138 smallDoses 24 0.332683 0.469709 0.818801 largeDoses 25 0.117329 0.067943 0.399234 smallDoses 26 0.266585 0.531719 0.476847 largeDoses 27 0.498691 0.640661 0.389745 largeDoses 28 0.067687 0.057949 0.493195 smallDoses 29 0.116562 0.074976 0.765075 smallDoses ... ... ... ... ... 70 0.588465 0.580790 0.819148 largeDoses 71 0.705258 0.437379 0.515681 didntLike 72 0.101772 0.462088 0.808077 smallDoses 73 0.664085 0.173051 0.169156 didntLike 74 0.200914 0.250428 0.739211 smallDoses 75 0.250293 0.703453 0.886825 largeDoses 76 0.818161 0.690544 0.714136 didntLike 77 0.374076 0.650571 0.214290 largeDoses 78 0.155062 0.150176 0.249725 smallDoses 79 0.102188 0.000000 0.070700 smallDoses 80 0.208068 0.021738 0.609152 smallDoses 81 0.100720 0.024394 0.008994 smallDoses 82 0.025035 0.184718 0.363083 smallDoses 83 0.104007 0.321426 0.331622 smallDoses 84 0.025977 0.205043 0.006732 smallDoses 85 0.152981 0.000000 0.847443 smallDoses 86 0.025188 0.178477 0.411431 smallDoses 87 0.057651 0.095729 0.813893 smallDoses 88 0.051045 0.119632 0.108045 smallDoses 89 0.192631 0.305083 0.516670 smallDoses 90 0.304033 0.408557 0.075279 largeDoses 91 0.108115 0.128827 0.254764 smallDoses 92 0.200859 0.188880 0.196029 smallDoses 93 0.041414 0.471152 0.193598 smallDoses 94 0.199292 0.098902 0.253058 smallDoses 95 0.122106 0.163037 0.372224 smallDoses 96 0.754287 0.476818 0.394621 didntLike 97 0.291159 0.509103 0.510795 largeDoses 98 0.527111 0.436655 0.429005 largeDoses 99 0.479408 0.376809 0.785718 largeDoses 100 rows × 4 columns
5. 分类器针对于约会网站的测试代码
接下来,我们一起来构建针对于这个约会网站数据的分类器,上面我们已经将原始数据集进行归一化处理然后也切分了训练集和测试集,所以我们的函数的输入参数就可以是train、test和k(k-近邻算法的参数,也就是选择的距离最小的k个点)。
"""
函数功能:k-近邻算法分类器
参数说明:
train:训练集
test:测试集
k:k-近邻参数,即选择距离最小的k个点
返回:预测好分类的测试集
"""
def datingClass(train,test,k):
n = train.shape[1] - 1
m = test.shape[0]
result = []
for i in range(m):
dist = list((((train.iloc[:, :n] - test.iloc[i, :n]) ** 2).sum(1))**5)
dist_l = pd.DataFrame({'dist': dist, 'labels': (train.iloc[:, n])})
dr = dist_l.sort_values(by = 'dist')[: k]
re = dr.loc[:, 'labels'].value_counts()
result.append(re.index[0])
result = pd.Series(result)
test['predict'] = result
acc = (test.iloc[:,-1]==test.iloc[:,-2]).mean()
print(f'模型预测准确率为{acc}')
return test
最后,测试上述代码能否正常运行,使用上面生成的测试集和训练集来导入分类器函数之中,然后执行并查看分类结果。
datingClass(train,test,5)
结果:模型预测准确率为0.95
| 0 | 1 | 2 | 3 | predict | |
|---|---|---|---|---|---|
| 0 | 0.513766 | 0.170320 | 0.262181 | didntLike | didntLike |
| 1 | 0.089599 | 0.154426 | 0.785277 | smallDoses | smallDoses |
| 2 | 0.611167 | 0.172689 | 0.915245 | didntLike | didntLike |
| 3 | 0.012578 | 0.000000 | 0.195477 | smallDoses | smallDoses |
| 4 | 0.110241 | 0.187926 | 0.287082 | smallDoses | smallDoses |
| 5 | 0.812113 | 0.705201 | 0.681085 | didntLike | didntLike |
| 6 | 0.729712 | 0.490545 | 0.960202 | didntLike | didntLike |
| 7 | 0.130301 | 0.133239 | 0.926158 | smallDoses | smallDoses |
| 8 | 0.557755 | 0.722409 | 0.780811 | largeDoses | largeDoses |
| 9 | 0.437051 | 0.247835 | 0.131156 | largeDoses | didntLike |
| 10 | 0.722174 | 0.184918 | 0.074908 | didntLike | didntLike |
| 11 | 0.719578 | 0.167690 | 0.016377 | didntLike | didntLike |
| 12 | 0.690193 | 0.526749 | 0.251657 | didntLike | didntLike |
| 13 | 0.403745 | 0.182242 | 0.386039 | didntLike | didntLike |
| 14 | 0.401751 | 0.528543 | 0.222839 | largeDoses | largeDoses |
| 15 | 0.425931 | 0.421948 | 0.590885 | largeDoses | largeDoses |
| 16 | 0.294479 | 0.534140 | 0.871767 | largeDoses | largeDoses |
| 17 | 0.506678 | 0.550039 | 0.248375 | largeDoses | largeDoses |
| 18 | 0.139811 | 0.372772 | 0.086617 | largeDoses | smallDoses |
| 19 | 0.386555 | 0.485440 | 0.807905 | largeDoses | largeDoses |
| 20 | 0.748370 | 0.508872 | 0.408589 | didntLike | didntLike |
| 21 | 0.342511 | 0.461926 | 0.897321 | largeDoses | largeDoses |
| 22 | 0.380770 | 0.515810 | 0.774052 | largeDoses | largeDoses |
| 23 | 0.146900 | 0.134351 | 0.129138 | smallDoses | smallDoses |
| 24 | 0.332683 | 0.469709 | 0.818801 | largeDoses | largeDoses |
| 25 | 0.117329 | 0.067943 | 0.399234 | smallDoses | smallDoses |
| 26 | 0.266585 | 0.531719 | 0.476847 | largeDoses | largeDoses |
| 27 | 0.498691 | 0.640661 | 0.389745 | largeDoses | largeDoses |
| 28 | 0.067687 | 0.057949 | 0.493195 | smallDoses | smallDoses |
| 29 | 0.116562 | 0.074976 | 0.765075 | smallDoses | smallDoses |
| ... | ... | ... | ... | ... | ... |
| 70 | 0.588465 | 0.580790 | 0.819148 | largeDoses | largeDoses |
| 71 | 0.705258 | 0.437379 | 0.515681 | didntLike | didntLike |
| 72 | 0.101772 | 0.462088 | 0.808077 | smallDoses | smallDoses |
| 73 | 0.664085 | 0.173051 | 0.169156 | didntLike | didntLike |
| 74 | 0.200914 | 0.250428 | 0.739211 | smallDoses | smallDoses |
| 75 | 0.250293 | 0.703453 | 0.886825 | largeDoses | largeDoses |
| 76 | 0.818161 | 0.690544 | 0.714136 | didntLike | didntLike |
| 77 | 0.374076 | 0.650571 | 0.214290 | largeDoses | largeDoses |
| 78 | 0.155062 | 0.150176 | 0.249725 | smallDoses | smallDoses |
| 79 | 0.102188 | 0.000000 | 0.070700 | smallDoses | smallDoses |
| 80 | 0.208068 | 0.021738 | 0.609152 | smallDoses | smallDoses |
| 81 | 0.100720 | 0.024394 | 0.008994 | smallDoses | smallDoses |
| 82 | 0.025035 | 0.184718 | 0.363083 | smallDoses | smallDoses |
| 83 | 0.104007 | 0.321426 | 0.331622 | smallDoses | smallDoses |
| 84 | 0.025977 | 0.205043 | 0.006732 | smallDoses | smallDoses |
| 85 | 0.152981 | 0.000000 | 0.847443 | smallDoses | smallDoses |
| 86 | 0.025188 | 0.178477 | 0.411431 | smallDoses | smallDoses |
| 87 | 0.057651 | 0.095729 | 0.813893 | smallDoses | smallDoses |
| 88 | 0.051045 | 0.119632 | 0.108045 | smallDoses | smallDoses |
| 89 | 0.192631 | 0.305083 | 0.516670 | smallDoses | smallDoses |
| 90 | 0.304033 | 0.408557 | 0.075279 | largeDoses | largeDoses |
| 91 | 0.108115 | 0.128827 | 0.254764 | smallDoses | smallDoses |
| 92 | 0.200859 | 0.188880 | 0.196029 | smallDoses | smallDoses |
| 93 | 0.041414 | 0.471152 | 0.193598 | smallDoses | smallDoses |
| 94 | 0.199292 | 0.098902 | 0.253058 | smallDoses | smallDoses |
| 95 | 0.122106 | 0.163037 | 0.372224 | smallDoses | smallDoses |
| 96 | 0.754287 | 0.476818 | 0.394621 | didntLike | didntLike |
| 97 | 0.291159 | 0.509103 | 0.510795 | largeDoses | largeDoses |
| 98 | 0.527111 | 0.436655 | 0.429005 | largeDoses | largeDoses |
| 99 | 0.479408 | 0.376809 | 0.785718 | largeDoses | largeDoses |
100 rows × 5 columns
从结果可以看出,我们模型的准确率还不错,这是一个不错的结果了。
四、算法总结
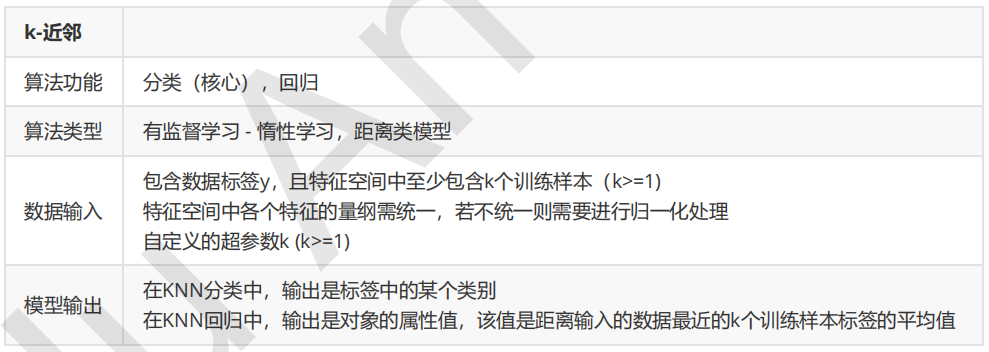
1. 优点
- 简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归
- 可用于数值型数据和离散型数据
- 无数据输入假定
- 适合对稀有事件进行分类
2.缺点
- 计算复杂性高;空间复杂性高
- 计算量太大,所以一般数值很大的时候不用这个,但是单个样本又不能太少,否则容易发生误分
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)
- 可理解性比较差,无法给出数据的内在含义
