
数据结构与算法二最好、最坏、平均、均摊时间复杂度
前言
知识让生活更具能量。希望我们在以后学习的路上携手同行。您的点赞、评论和打赏都是对我最大的鼓励。一个人能走多远要看与谁同行,希望能与优秀的您结交。
我们在上一章, 主要是介绍了一下时间复杂度的分析,接下来接着跟大家聊一下时间复杂度的知识点。
最好、最坏情况时间复杂度
我们可以尝试分析下面的代码
//n表示数据array的长度
int find(int[] array,int n, int x){
int i = 0;
int pos = i;
for(; i<n ; ++i){
if(array[i] = x){
pos = i;
}
}
return pos;
}
这段代码的功能是:在一个无序是的数组中找出x所在的位置。如果没有找到,就返回-1。
我们可以用让一章的内容分析出,这段代码阶位最高的为for循环中的代码,代码复杂度为O(n)。
大家可以看出,这段代码的效率不是很高,我们是可以对代码的效率进行优化的。如果我们中途找到这x的值就可以直接退出for循环。
int find(int[] array,int n, int x){
int i = 0;
int pos = i;
for(; i<n ; ++i){
if(array[i] = x){
pos = i;
break;
}
}
return pos;
}
这个时侯,我们就不可以用O(n)表示这段代码的时间复杂度了。
因为,要查找的变量x可能出现在数组的任意位置。如果数据中的第一个元素正好是要查找的变量x,那就不需要继续遍历剩下的n-1个数据了,那时间复杂度为O(1), 如果x所在的位置为最后一个元素,那么这段代码的时间复杂度为O(n)。
这个时间我们要引入新的概念最好时间复杂度,最坏时间复杂度。上面第一种情况就对应我们最好时间复杂度,第二情况就对我们最坏时间复杂度。
平均时间复杂度
因为出现最好时间复杂度和最坏时间复杂度的情况不是很大, 我们引入了一个新的概念,平时时间复杂度。
我们就来分析一下刚才的例子,要查找的变量x在数组中的位置,有n+1种情况:在数组的0~n-1位置中和不在数组中。我们把每种情况下,需要遍历的元素个数累加起来,然后在除以n+1,
就可以得到需要遍历的元素个数的平均值:
1
+
2
+
.
.
.
.
+
n
+
n
n
+
1
=
n
(
n
+
3
)
2
(
n
+
1
)
\frac{1+2+ ....+n+n}{n+1}=\frac{n(n+3)}{2(n+1)}
n+11+2+....+n+n=2(n+1)n(n+3)
时间复杂度的大O表示法中,可以省略掉系数、低阶、常量。把公式简化之后得到平均时间复杂度为O(n)。这并不是最终的答案,我们还要将概率加入到中才可以得到最终的结果。
我们假设x在数组中与不在数组中的概率都是1/2。另外,要查找的数据出现在0~n-1这n个位置的概率也是一样的,为1/n。根据概念乘法法则,x数据出现在``0~n-1的任意位置的概率为1/(2n)。
我们将概率加到上面的公式中,那平均时间复杂度为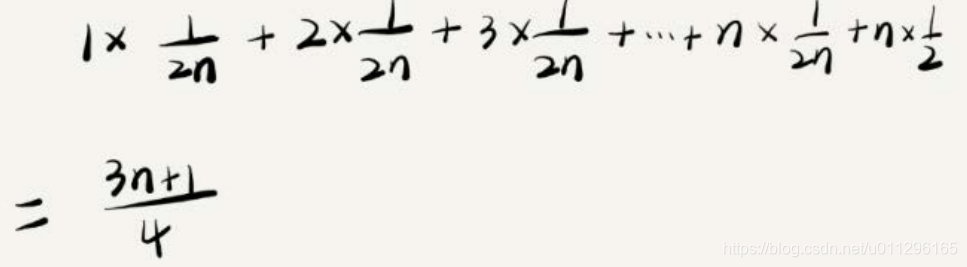
这个值就是概率论中的加权平均值,也叫作期望值。
引入概率之后,前面那段代码的加权平均值为(3n+1)/4。用大O表示法来表示,去掉系数和常量,最终结果为O(n)。
均推时间复杂度
我们先看一下代码
int[] array = new int[n]
int count =0 ;
void insert(int val){
if(count == array.length()){
int sum = 0;
for(int i = 0; i<array.length(); ++i){
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count]=val;
++count;
}
这段代码的实现了一个往数据中插入数据的功能。当数组满了之后,也就是代码中的count==array.length()时,我们用for循环遍历数组求和,并清空数组,将求和之后的sum值放到数组中的第一个位置,然后再将新的数据插入。但如果数组一开始就有空闲空间,则直接将数据插入数组。
我们先使用上面的三种复杂度分析法分析这段代码:
最好的情况下,数组中有空闲空间,我们只需要将数据添加到数据即可,所以最好情况时间复杂度为O(1)。
最坏的情况下,数组中没有空闲空间了,我们需要先做一次遍历求和,然后再将数据插入,所以最坏情况时间复杂度为O(n)。
那平均时间复杂度是多少呢?(重点)
假设数组的长度是n,根据数据插入的位置不同,我们可以分为n种情况 ,每种情况的时间复杂度都为O(1)。除此之外,还有一种“额外”的情况,就是在数组没有空闲空间时插入一个数据,这个时间复杂度为O(n)。而且 ,这n+1种情况发生的概率一样,都是1/(n+1)。所以,根据加权平均的计算方法,我们求得的平均时间复杂度为
1
∗
1
n
+
1
+
1
∗
1
n
+
1
+
.
.
.
.
.
+
n
∗
1
n
+
1
=
O
(
1
)
1*\frac{1}{n+1} +1*\frac{1}{n+1}+.....+n*\frac{1}{n+1} = O(1)
1∗n+11+1∗n+11+.....+n∗n+11=O(1)。
我们通过对比前面两个例子find() 和insert()。会发现他们两个不同点。
首先,find()方法只有在特殊的情况下复杂度才为O(1)。但insert()方法在大部分情况下,时间复杂度都为O(1)。只有在特殊的情况下,复杂度才为O(n)。
第二个不同点,对于insert()方法,时间复杂度O(1)和时间复杂度O(n)是规律出现的。一般一个O(n)之后就跟着n-1个O(1)操作。
针对这种情况,我们可以使用均推分析法,看下面的分析:
每一次O(n)的插入操作,都会跟着n-1次O(1)的插入操作,所以把耗时多的那次操作均推到接下来的n-1次耗时少的操作上,均推下来, 这一组连续操作的均摊时间复杂度就是O(1)。
规律: 对一个数据结构进行一组连续操作中,大部份情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系 ,这个时间,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上
总结:
在这两篇文章中,我们主要学习了时间复杂度的几种分析方法。 大O时间复杂度分析法中平均,均摊分析最难,但是也最不常用。 多多练习练习分析分析,应该就会了。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2020-08-14 IK分词器基础安装入门