
数据结构与算法四:链表 如何基于链表实现 LRU缓存淘汰算法呢?
前言
知识让生活更具能量。希望我们在以后学习的路上携手同行。您的点赞、评论和打赏都是对我最大的鼓励。一个人能走多远要看与谁同行,希望能与优秀的您结交。
链表这种数据结构一个经典的应用场景就是LRU缓存淘汰算法。 缓存空间如果满了的话就需要对空间进行优化,清理一些不要的数据。常见的有三种策略:先进先出策略FIFO(first In,First Out)、最少使用策略(Least Frequently Used)、最近最少使用策略LRU(Least Recently Used)。
我之前用java写过一个缓存采用的就是第三种LRU策略。 缓存 这是我的项目,还请各位多多关注。
链表结构种类介绍
链表这种数据结构也分了很多小种类。主要的区别在于指针的多少,差别不是很大,下面我们来一一介绍。
单链表
单链表中的每一个节点,除了保存自身的数据,还包含了一个指针指向下一个节点。

从上图我们可以看到单链表有两个特殊的节点。 第一个节点是头节点,记录链表的基地址,有了它我们就可以遍历整个链表了。 最后一个节点是链表的尾节点。它指向的是一个空地址Null。
它的插入和删除的时间复杂度都是O(1)。因为链表在插入和删除数据的时候不用管节点的有序性。 只需要更改前一节点的指针就可以了。
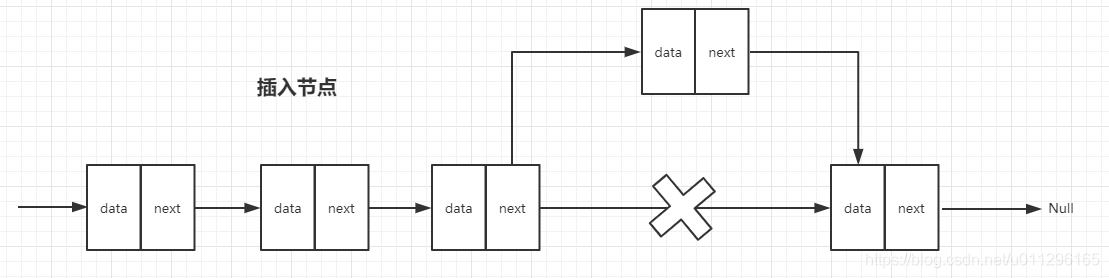
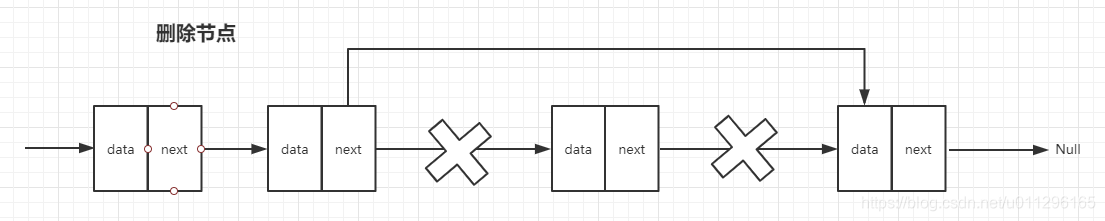
但是链表的随机访问速度就比较低了,他只能通过循环遍历来查询值, 没有办法像数组那样通过计算公式来取值。 他的随机查询复杂度为O(n)。
循环链表
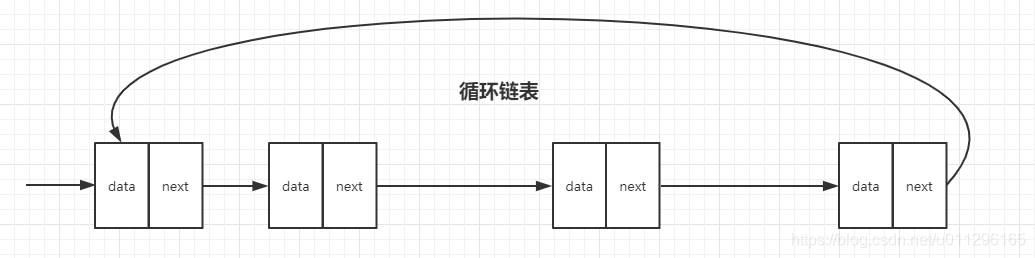
循环链表是一种特殊的单链表。它和单链表的区别就是尾结点指向头节点。当要处理的数据具有环形结构特点时,就特别适合采用循环链表。比如约瑟夫斯问题
双向链表
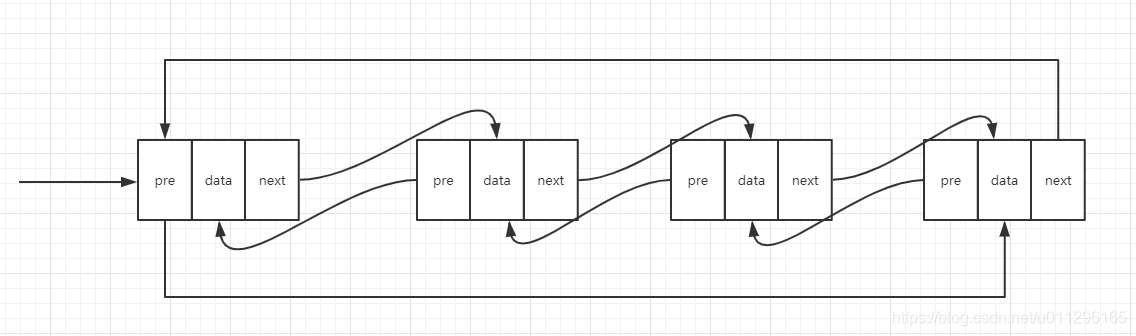
双向链表每一个节点都有两个指向,分别指向前一个节点的地址,和后一个节点的地址。

双向链表支持O(1)复杂度查询前驱节点。因为这一点双向链表比单向链表的优化就可以体现出来了。 比如: 插入或者删除给定指针指向的节点
假如我们现在在操作的是单向链表,我们想要删除给定指针指向的节点,那么还需要找到这个节点的上一个节点才行。 而去循环上一个节点的时间复杂度为O(n),根据时间复杂度分析加法法则,虽然删除这个操作本身的时间复杂度为O(1),但是查询复杂度加上删除复杂度的结果就为O(n)。
但是我们双向链表本身就包含了前驱节点的指针。 就省去循环遍历因此删除给定指针指向的节点的时间复杂度就为O(1)。 同理插入操作也是一样的。java语言中的LinkHashMap就运用了双向链表的数据结构。
还有一种双向循环链表和双向链表类似。
如何基于链表实现 LRU缓存淘汰算法呢?
LRU只是一种算法,它的设计原则:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。
我们实现思路如下:
当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。
在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
在我们实战使用双向链表设计缓存的时候经常使用HashMap加上双向链表这种数据结构来实现。 我文中介绍的我写的缓存项目就是采用的这种方式。
代码demo
/**
*
* LRU(Least Recently Used)缓存算法
* 使用HashMap+双向链表,使get和put的时间复杂度达到O(1)。
* 读缓存时从HashMap中查找key,更新缓存时同时更新HashMap和双向链表,双向链表始终按照访问顺序排列。
*
*/
public class LRUCache {
/**
* @param args
* 测试程序,访问顺序为[[1,1],[2,2],[1],[3,3],[2],[4,4],[1],[3],[4]],其中成对的数调用put,单个数调用get。
* get的结果为[1],[-1],[-1],[3],[4],-1表示缓存未命中,其它数字表示命中。
*/
public static void main(String[] args) {
LRUCache cache = new LRUCache(2);
cache.put(1, 1);
cache.put(2, 2);
System.out.println(cache.get(1));
cache.put(3, 3);
System.out.println(cache.get(2));
cache.put(4, 4);
System.out.println(cache.get(1));
System.out.println(cache.get(3));
System.out.println(cache.get(4));
}
// 缓存容量
private final int capacity;
// 用于加速缓存项随机访问性能的HashMap
private HashMap<Integer, Entry> map;
// 双向链表头结点,该侧的缓存项访问时间较早
private Entry head;
// 双向链表尾结点,该侧的缓存项访问时间较新
private Entry tail;
public LRUCache(int capacity) {
this.capacity = capacity;
map = new HashMap<Integer, Entry>((int)(capacity / 0.75 + 1), 0.75f);
head = new Entry(0, 0);
tail = new Entry(0, 0);
head.next = tail;
tail.prev = head;
}
/**
* 从缓存中获取key对应的值,若未命中则返回-1
* @param key 键
* @return key对应的值,若未命中则返回-1
*/
public int get(int key) {
if (map.containsKey(key)) {
Entry entry = map.get(key);
popToTail(entry);
return entry.value;
}
return -1;
}
/**
* 向缓存中插入或更新值
* @param key 待更新的键
* @param value 待更新的值
*/
public void put(int key, int value) {
if (map.containsKey(key)) {
Entry entry = map.get(key);
entry.value = value;
popToTail(entry);
}
else {
Entry newEntry = new Entry(key, value);
if (map.size() >= capacity) {
Entry first = removeFirst();
map.remove(first.key);
}
addToTail(newEntry);
map.put(key, newEntry);
}
}
/**
* 缓存项的包装类,包含键、值、前驱结点、后继结点
* @author wjg
*
*/
class Entry {
int key;
int value;
Entry prev;
Entry next;
Entry(int key, int value) {
this.key = key;
this.value = value;
}
}
// 将entry结点移动到链表末端
private void popToTail(Entry entry) {
Entry prev = entry.prev;
Entry next = entry.next;
prev.next = next;
next.prev = prev;
Entry last = tail.prev;
last.next = entry;
tail.prev = entry;
entry.prev = last;
entry.next = tail;
}
// 移除链表首端的结点
private Entry removeFirst() {
Entry first = head.next;
Entry second = first.next;
head.next = second;
second.prev = head;
return first;
}
// 添加entry结点到链表末端
private void addToTail(Entry entry) {
Entry last = tail.prev;
last.next = entry;
tail.prev = entry;
entry.prev = last;
entry.next = tail;
}
}
值得一提的是,Java API中其实已经有数据类型提供了我们需要的功能,就是LinkedHashMap这个类。该类内部也是采用HashMap+双向链表实现的。使用这个类实现LRU就简练多了。
/**
*
* 一个更简单实用的LRUCache方案,使用LinkedHashMap即可实现。
* LinkedHashMap提供了按照访问顺序排序的方案,内部也是使用HashMap+双向链表。
* 只需要重写removeEldestEntry方法,当该方法返回true时,LinkedHashMap会删除最旧的结点。
*
*
*/
public class LRUCacheSimple {
/**
* @param args
*/
public static void main(String[] args) {
LRUCacheSimple cache = new LRUCacheSimple(2);
cache.put(1, 1);
cache.put(2, 2);
System.out.println(cache.get(1));
cache.put(3, 3);
System.out.println(cache.get(2));
cache.put(4, 4);
System.out.println(cache.get(1));
System.out.println(cache.get(3));
System.out.println(cache.get(4));
}
private LinkedHashMap<Integer, Integer> map;
private final int capacity;
public LRUCacheSimple(int capacity) {
this.capacity = capacity;
map = new LinkedHashMap<Integer, Integer>(capacity, 0.75f, true){
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
};
}
public int get(int key) {
return map.getOrDefault(key, -1);
}
public void put(int key, int value) {
map.put(key, value);
}
}
只需要覆写LinkedHashMap的removeEldestEntry方法,在缓存已满的情况下返回true,内部就会自动删除最老的元素。
以上内容均为读书所得, 想看更多内容请关注微信公众号。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号