python学习点滴记录-Day19
day19上课内容
-
上节课回顾
-
多对多添加
-
多对多解除
-
基于对象的正向查询和反向查询
-
一对一查询
-
多对多的增删改
-
基于双下划线的跨表查询
-
聚合函数与分组
-
FQ查询
上节课回顾:
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
单表操作:
添加
(1)表.objects.create(**kwargs)
(2)obj=表(**kwargs)
obj.save()
一对多的关联字段要建立在多的表中
models.ForeignKey(to='Publish',to_field='id')#与书籍对象关联的出版社对象,因为是一对多关系,所有出版社对象只能有一个
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 模版语法
1)自定义过滤器和标签
2)模版继承:
base.html {% block %} {% block%}
index(继承母板):extend "base.html" {% block %} {% block%}
2 ORM跨表添加
ORM一对多的添加
1、publish_obj=Publish.objects.get(id=2)
表.objects.create(titile='python',publisher=publish_obj)
2、表.objects.create(titile='python',publisher_id=2)
ORM多对多的添加
authors=modes.ManyToManyField('author')#与这本书关联的作者对象集合
绑定关系
obj1=models.Author.objects.get(name="作者1")
obj2=models.Author.objects.get(name="作者2")
book_obj.authors.add(obj1,obj2,...)
book_obj.authors.add(*[列表])
解除关系
book_obj.authors.remove(obj1,obj2,...)
book_obj.authors.remove(*[])
book_obj.authors.clear() 清空与这本书相关的所有作者
3 ORM跨表查询
一对一的跨表查询
正向反向是在于关联字段是在哪个表中,通过关联字段在的那个表查询就是正向查询,反之。
一对多的跨表查询
#查询python这本书出版社的地址(正向查询: 按字段) book_obj=Book.objects.get(title='python') book_obj.publisher.addr #查询指定出版社初版过的所有书籍名称以及价格(反向查询:按关联的表名(小写)_set) pub_obj=models.Publish.objects.get(name="云南出版社") book_list=pub_obj.book_set.all() for obj in book_list: print(obj.title,obj.price)
多对多的跨表查询
# 多对多的正向 查询: 按字段 # 查询 python这本书的所有作者的姓名和年龄 # book_python=models.Book.objects.get(title="python") # author_list=book_python.authors.all() # for obj in author_list: # print(obj.name,obj.age) # # book_pythons = models.Book.objects.filter(title="python") # for book_python in book_pythons: # author_list = book_python.authors.all() # for obj in author_list: # print(obj.name, obj.age) # 多对多的反向查询 按关联的表名(小写)_set # alex出版过的所有书籍的明显名称 # alex=models.Author.objects.get(name="alex") # book_list=alex.book_set.all() # for i in book_list: # print(i.title,i.price)


##################################################################################查询 练习部分start # 正向查询按字段,反向查询按表名_set # query_author=models.Author.objects.filter(name='作者1').first() # query_book=models.Book.objects.get(title='超级仙农')#查询超级仙农的出版社信息 # 查询云南出版社初版的书籍 反向 # yn_pub=models.Publish.objects.filter(name__contains='北京').first() # for i in yn_pub.book_set.all(): # print(i.id,i.title) # 查询指定书籍的所有作者 # bookObj=models.Book.objects.get(title__contains='橡皮擦') # for i in bookObj.authors.all(): # print(i.name) # 查询作者1写的所有书籍 # author1_obj=models.Author.objects.get(name__contains='1') # for i in author1_obj.book_set.all(): # print(i.title) ##################################################################################查询 练习部分end ##################################################################################新增 练习部分start # 参考add部分 # bookObj=models.Book.objects.get(title='阴间商人')#先定位到书籍的obj # l=['2','3']#模拟数据,不能随意,得是作者表中存在的 # bookObj.authors.add(*l)#为书籍绑定多个作者 ##################################################################################新增 练习部分end ##################################################################################删除 练习部分start # bookObj=models.Book.objects.get(title__contains='3') # bookObj.delete() #删除记录 # bookObj=models.Book.objects.get(title__contains='爬虫') # bookObj.authors.remove(models.Author.objects.get(name='作者3')) #解除部分绑定关系 # models.Book.objects.get(title__contains='爬虫').authors.add('3')上面解除完后再测试新增 ##################################################################################删除 练习部分end ##################################################################################双下划线查询 练习部分start # 格式大概为 models.表.objects.filter(条件).values(本表字段或者他表__他表字段) # print(models.Book.objects.filter(title__contains='书').values('price','title')) #获取指定书籍的的price和title字段,<QuerySet [{'price': Decimal('54.00'), 'title': '测试书籍new'}, {'price': Decimal('55.00'), 'title': '测试书籍orz'}]> # print(models.Book.objects.filter(title__contains='python').values_list('publish__name','publish__addr')) # 获取指定书籍的出版社名称和地址< QuerySet[('北京出版社', '北京')] > # print(models.Publish.objects.filter(name__contains='云南').values('book__title','book__price')) #查询指定出版社出版过的书籍信息 #<QuerySet [{'book__title': '超级仙农', 'book__price': Decimal('100.00')}, {'book__title': '渡灵天师', 'book__price': Decimal('101.00')}]> # print(models.Author.objects.filter(name__contains='老九').values('book__title')) # print(models.Author.objects.filter(name__contains='道门老九').values_list('book__title')) #获取指定作者写过的书籍信息<QuerySet [{'book__title': '超级仙农'}, {'book__title': '脑海中的橡皮擦'}, {'book__title': '阴间商人'}, {'book__title': 'python爬虫'}, {'book__title': '测试书籍orz'}]> ##################################################################################双下划线查询 练习部分end
基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。
关键点:正向查询按字段,反向查询按表名。
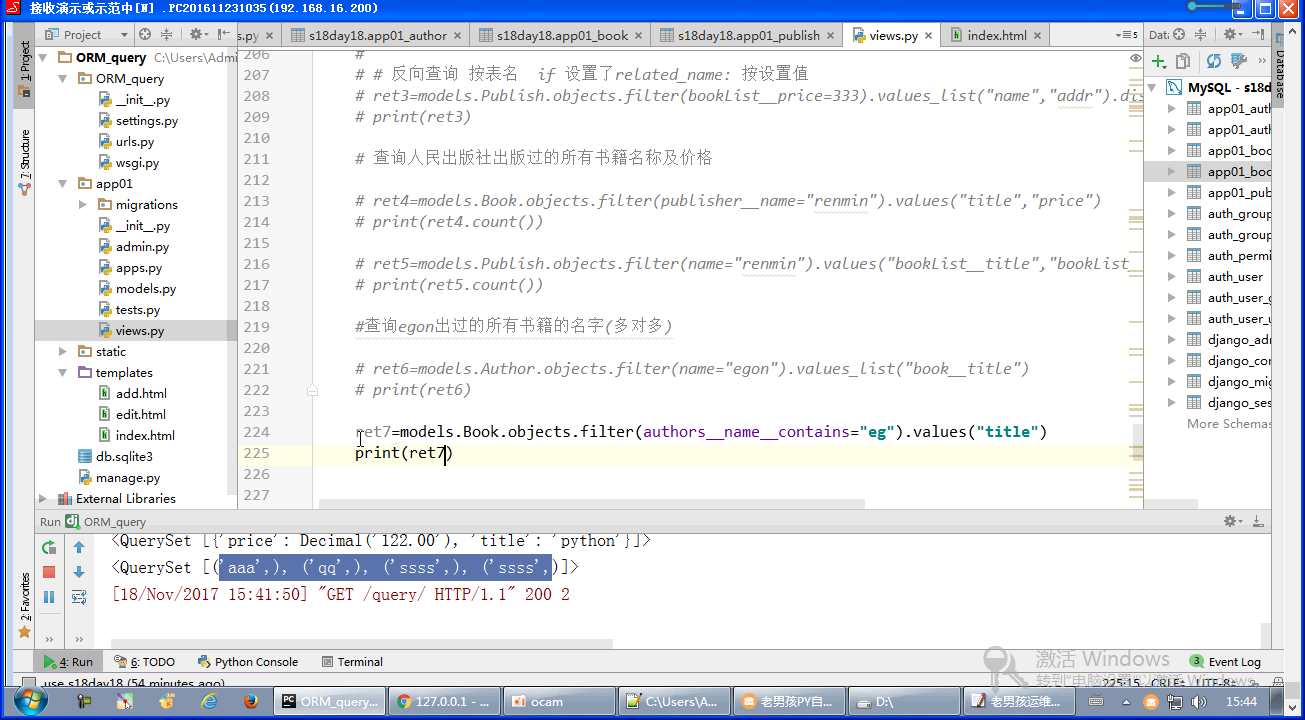
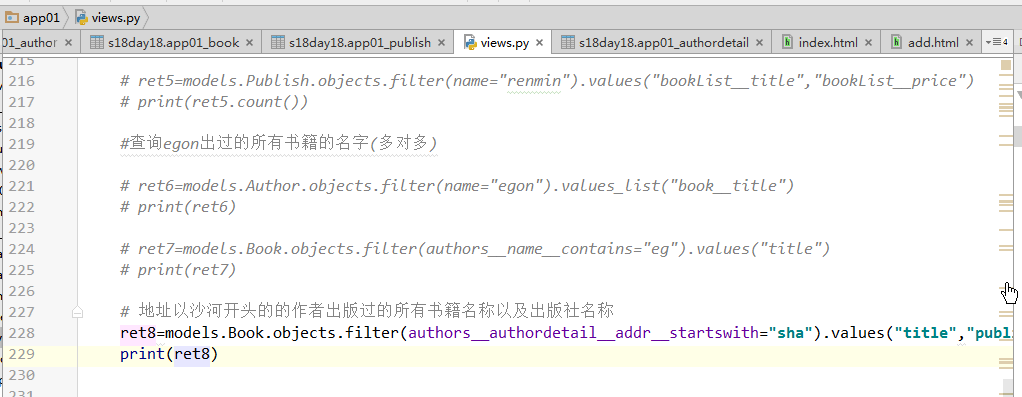
# 练习1: 查询人民出版社出版过的所有书籍的名字与价格(一对多) # 正向查询 按字段:publish queryResult=Book.objects .filter(publish__name="人民出版社") .values_list("title","price") # 反向查询 按表名:book queryResult=Publish.objects .filter(name="人民出版社") .values_list("book__title","book__price") # 练习2: 查询egon出过的所有书籍的名字(多对多) # 正向查询 按字段:authors: queryResult=Book.objects .filter(authors__name="yuan") .values_list("title") # 反向查询 按表名:book queryResult=Author.objects .filter(name="yuan") .values_list("book__title","book__price") # 练习3: 查询人民出版社出版过的所有书籍的名字以及作者的姓名 # 正向查询 queryResult=Book.objects .filter(publish__name="人民出版社") .values_list("title","authors__name") # 反向查询 queryResult=Publish.objects .filter(name="人民出版社") .values_list("book__title","book__authors__age","book__authors__name") # 练习4: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称 queryResult=Book.objects .filter(authors__authorDetail__telephone__regex="151") .values_list("title","publish__name")
注意:
反向查询时,如果定义了related_name ,则用related_name替换表名,例如: publish = ForeignKey(Blog, related_name='bookList'):
# 练习1: 查询人民出版社出版过的所有书籍的名字与价格(一对多) # 反向查询 不再按表名:book,而是related_name:bookList queryResult=Publish.objects .filter(name="人民出版社") .values_list("bookList__title","bookList__price")
聚合查询与分组查询
先了解sql中的聚合与分组概念
聚合:aggregate(*args, **kwargs)
# 计算所有图书的平均价格 >>> from django.db.models import Avg >>> Book.objects.all().aggregate(Avg('price')) {'price__avg': 34.35}
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
>>> Book.objects.aggregate(average_price=Avg('price')) {'average_price': 34.35}
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> from django.db.models import Avg, Max, Min >>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price')) {'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
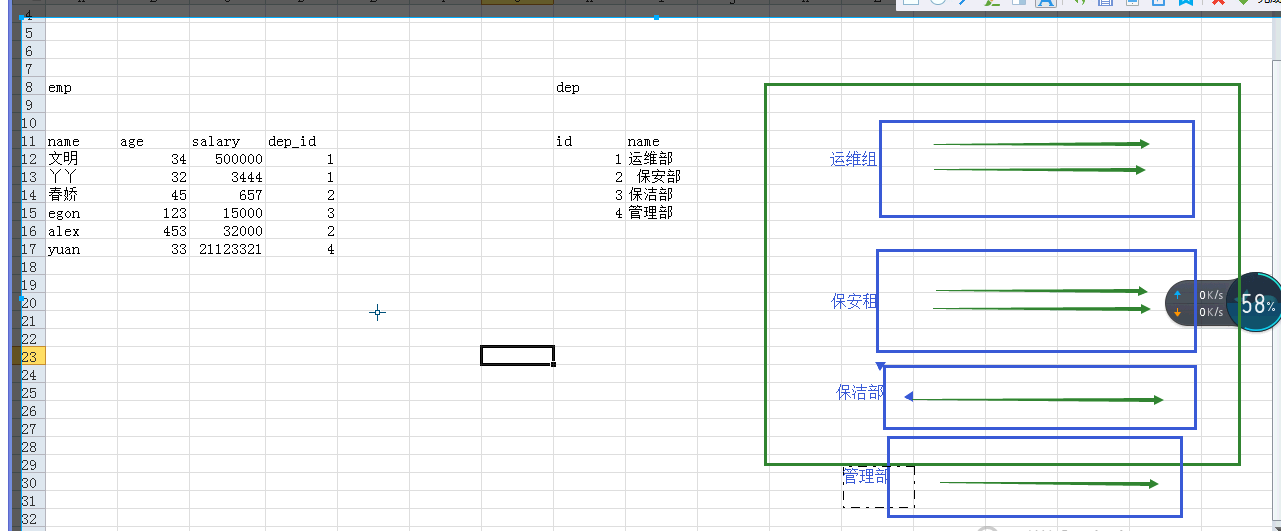
分组:annotate()
为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
(1) 练习:统计每一本书的作者个数
bookList=Book.objects.annotate(authorsNum=Count('authors')) for book_obj in bookList: print(book_obj.title,book_obj.authorsNum)
SELECT "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."pageNum", "app01_book"."publish_id", COUNT("app01_book_authors"."author_id") AS "authorsNum" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."nid" = "app01_book_authors"."book_id") GROUP BY "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."pageNum", "app01_book"."publish_id" sql
解析:
'''
Book.objects.annotate(authorsNum=Count('authors'))
拆分解析:
Book.objects等同于Book.objects.all(),翻译成的sql类似于: select id,name,.. from Book
这样得到的对象一定是每一本书对象,有n本书籍记录,就分n个组,不会有重复对象,每一组再由annotate分组统计。'''
(2) 如果想对所查询对象的关联对象进行聚合:
练习:统计每一个出版社的最便宜的书
publishList=Publish.objects.annotate(MinPrice=Min("book__price")) for publish_obj in publishList: print(publish_obj.name,publish_obj.MinPrice)
annotate的返回值是querySet,如果不想遍历对象,可以用上valuelist:
queryResult= Publish.objects
.annotate(MinPrice=Min("book__price"))
.values_list("name","MinPrice")
print(queryResult)
解析同上。
方式2:
queryResult=Book.objects.values("publish__name").annotate(MinPrice=Min('price')) # 思考: if 有一个出版社没有出版过书会怎样?
解析:
'''
查看 Book.objects.values("publish__name")的结果和对应的sql语句
可以理解为values内的字段即group by的字段'''
(3) 统计每一本以py开头的书籍的作者个数:
queryResult=Book.objects
.filter(title__startswith="Py")
.annotate(num_authors=Count('authors'))
(4) 统计不止一个作者的图书:
queryResult=Book.objects
.annotate(num_authors=Count('authors'))
.filter(num_authors__gt=1)
(5) 根据一本图书作者数量的多少对查询集 QuerySet进行排序:
Book.objects.annotate(num_authors=Count('authors')).order_by('num_authors')
(6) 查询各个作者出的书的总价格:
# 按author表的所有字段 group by
queryResult=Author.objects
.annotate(SumPrice=Sum("book__price"))
.values_list("name","SumPrice")
print(queryResult)
# 按authors__name group by
queryResult2=Book.objects.values("authors__name")
.annotate(SumPrice=Sum("price"))
.values_list("authors__name","SumPrice")
print(queryResult2)
F查询与Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
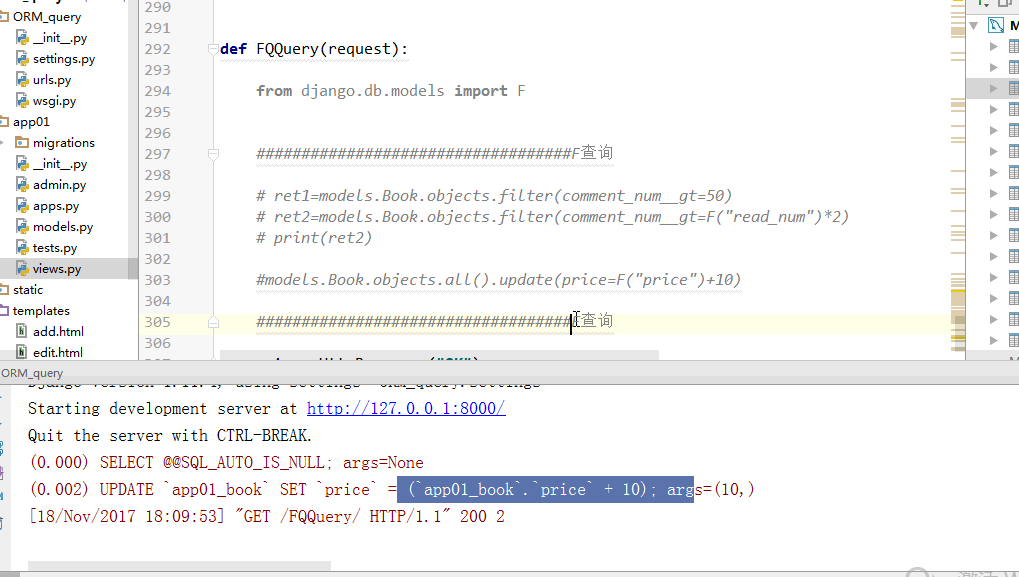
# 查询评论数大于收藏数的书籍 from django.db.models import F Book.objects.filter(commnetNum__lt=F('keepNum'))
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
# 查询评论数大于收藏数2倍的书籍
Book.objects.filter(commnetNum__lt=F('keepNum')*2)修改操作也可以使用F函数,比如将每一本书的价格提高30元:
Book.objects.all().update(price=F("price")+30)
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
from django.db.models import Q Q(title__startswith='Py')
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon"))
等同于下面的SQL WHERE 子句:
WHERE name ="yuan" OR name ="egon"
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(publishDate__year=2017)).values_list("title")
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017),
title__icontains="python"
)
修改表记录
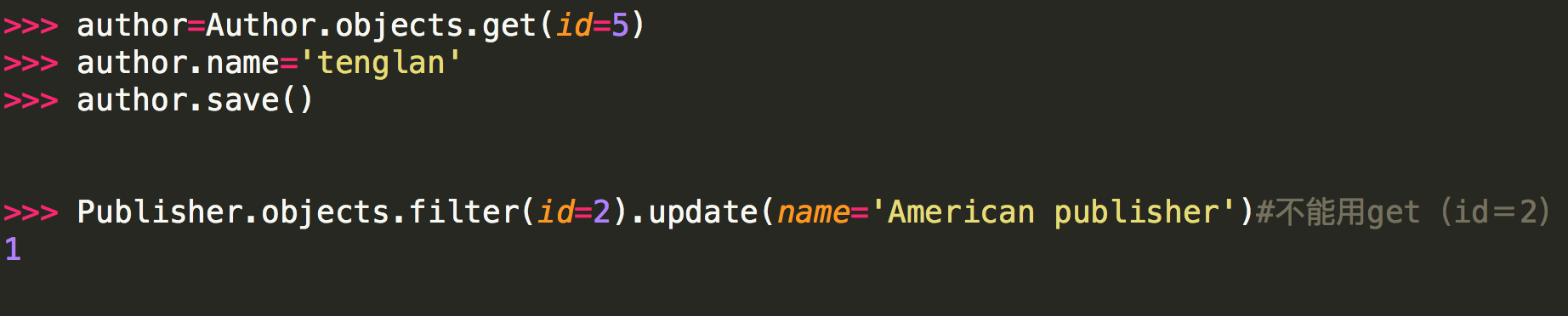
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分
删除表记录
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如:
你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
例如,下面的代码将删除 pub_date 是2005年的 Entry 对象:
Entry.objects.filter(pub_date__year=2005).delete()要牢记这一点:无论在什么情况下,QuerySet 中的 delete() 方法都只使用一条 SQL 语句一次性删除所有对象,而并不是分别删除每个对象。如果你想使用在 model 中自定义的 delete() 方法,就要自行调用每个对象的delete 方法。(例如,遍历 QuerySet,在每个对象上调用 delete()方法),而不是使用 QuerySet 中的 delete()方法。
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
b = Blog.objects.get(pk=1)# This will delete the Blog and all of its Entry objects.b.delete()要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
Entry.objects.all().delete()
课上视频截图
正向按字段,反向按表名_set