
Python基础(六)
今日主要内容
- 驻留机制
- 小数据池
- 代码块
- 深浅拷贝
- 集合
一、 驻留机制
(一)== 和 is
-
== :判断两边的内容是否相同
a = -6 b = -6 print(a == b) # True -
is :判断两边的内存地址是否相同
a = -6 b = -6 print(a is b) # Fales
(二)什么是驻留机制
- python中为了节省内存定义的一套规则,部分数据在重复定义的时候指向同一个内存空间,也就是内存地址是相同的
- 在驻留机制范围内的代码块和小数据池,在定义变量的时候都将履行驻留机制
- 代码块的优先级高于小数据池
(三)什么是代码块
- 一个py文件、一个函数、一个模块、一个类、终端中的每一行代码都是一个代码块
(四)小数据池和代码块的驻留范围
- 小数据池
- 数字:-5 ~ 256
- 字符串:
- 只包含数字、字母、下划线的全部字符串
- 在python3.6解释器中字符串使用乘的时候总长度不能超过20(只包含数字、字母、下划线)
- 在python3.7解释器中字符串使用乘的时候总长度不能超过4096(只包含数字、字母、下划线)
- 布尔值
- True
- False
- 代码块
- 数字:-5 ~ 正无穷
- 字符串:
- 全部字符串(包含数字、字母、下划线、特殊字符、中文等)
- 使用乘的时候总长度不能超过20(只包含数字、字母、下划线)
- 布尔值
- True
- False
(五)指定驻留
-
指定任意字符串,屡行驻留机制,重复定义都指向一个内存空间,即内存地址相同
from sys import intern # intern:拘禁、软禁 a = intern("hello!@" * 20) b = intern("hello!@" * 20) print(a is b) # True
(六)驻留机制的优点
- 提升效率
- 节约内存
二、深浅拷贝
(一)为什么会有深浅拷贝
-
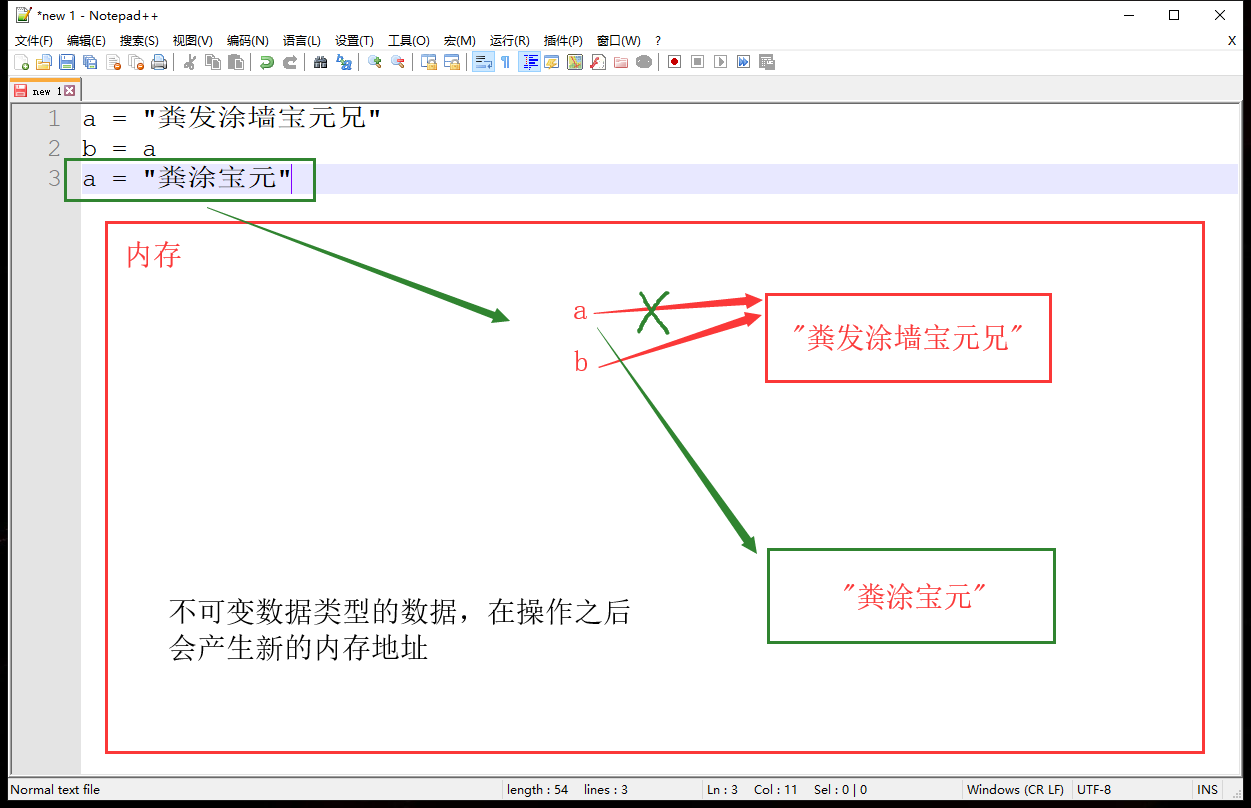
不可变类型数据(如字符串),在对数据进行操作的时候都会开辟一个新的内存空间储存操作后的数据,两个数据的内存地址是不相同的
a = "粪发涂墙宝元兄" b = a a = "粪涂宝元" print(a is b) # False print(a) # 粪涂宝元 print(b) # 粪发涂墙宝元兄- 不可变类型数据在操作之后都会产生新的内存地址
![]()
-
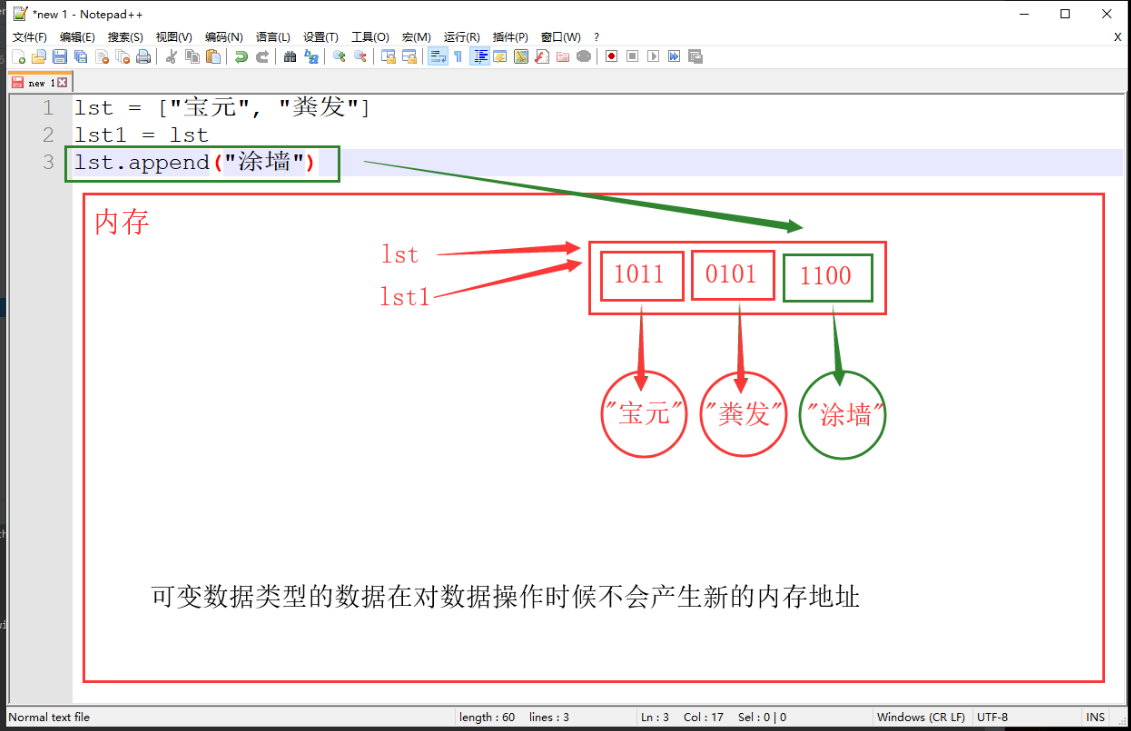
可变类型数据(如列表),在对数据进行操作的时候在原有列表进行修改,不会产生新的列表,所以一旦将列表赋值给另一个变量,一个列表变化另一个列表也随之变化
lst = ["宝元", "粪发"] lst1 = lst lst.append("涂墙") print(lst is lst1) # True print(lst) # ['宝元', '粪发', '涂墙'] print(lst1) # ['宝元', '粪发', '涂墙']- 可变类型数据,在操作后不会产生新的内存地址,而是在原有的数据上进行变化
![]()
-
总结:
- 多个变量指向同一个内存空间时:
- 若此数据类型为不可变类型(整型、字符串),修改则会开辟新的内存空间,产生新的内存地址
- 若此数据类型为可变类型(列表、字典),修改则会在原数据上进行修改,不会产生新的内存地址
- 利用深浅拷贝则可以解决可变数据类型修改数据,多个变量同时修改的问题
- 深浅拷贝只针对于可变数据类型
- 多个变量指向同一个内存空间时:
(二)浅拷贝
-
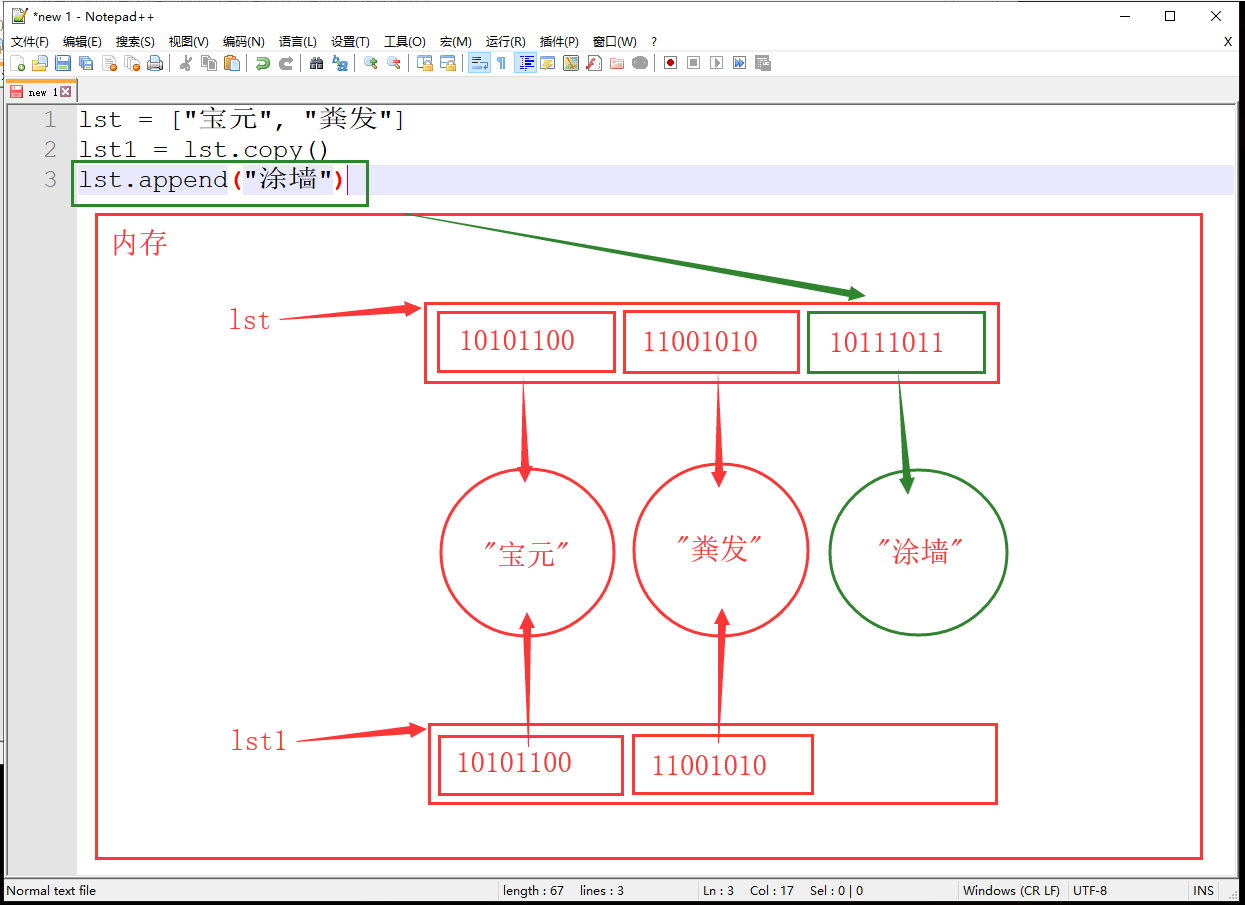
浅拷贝方法:
lst1 = lst.copy()
lst = ["宝元", "粪发"] lst1 = lst.copy() lst.append("涂墙") print(lst) # ['宝元', '粪发', '涂墙'] print(lst1) # ['宝元', '粪发']- 对数据全部切片也是浅拷贝
lst = ["宝元", "粪发"] lst1 = lst[:] lst.append("涂墙") print(lst) # ['宝元', '粪发', '涂墙'] print(lst1) # ['宝元', '粪发'] -
浅拷贝之后,对数据修改时内存的变化
- 新增数据
![]()
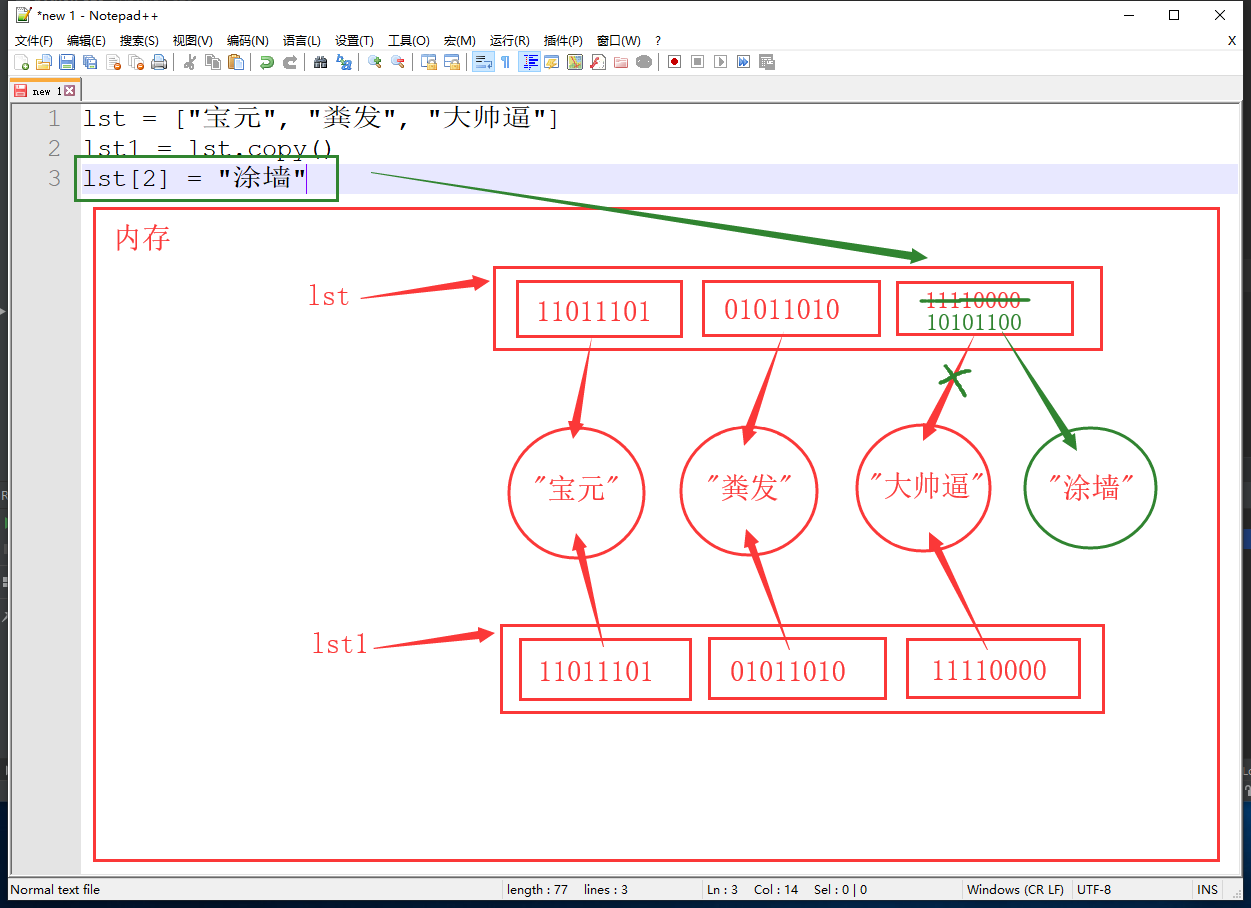
- 修改数据
![]()
-
总结:
- 通过浅拷贝得到的列表与原列表的内存地址不同,但列表中储存的元素内存地址相同,也就是说复制了一个列表但共用相同的元素
- 浅拷贝之后对列表进行修改,另一个列表不会变化,因为此时两个列表不是指向的同一个内存空间
(三)深拷贝
-
现在解决了可变类型数据(如列表)多个变量指向同一空间的问题,但是如果列表中再嵌套一个可变类型数据,情况又不一样了
- 向列表中嵌套的列表添加元素
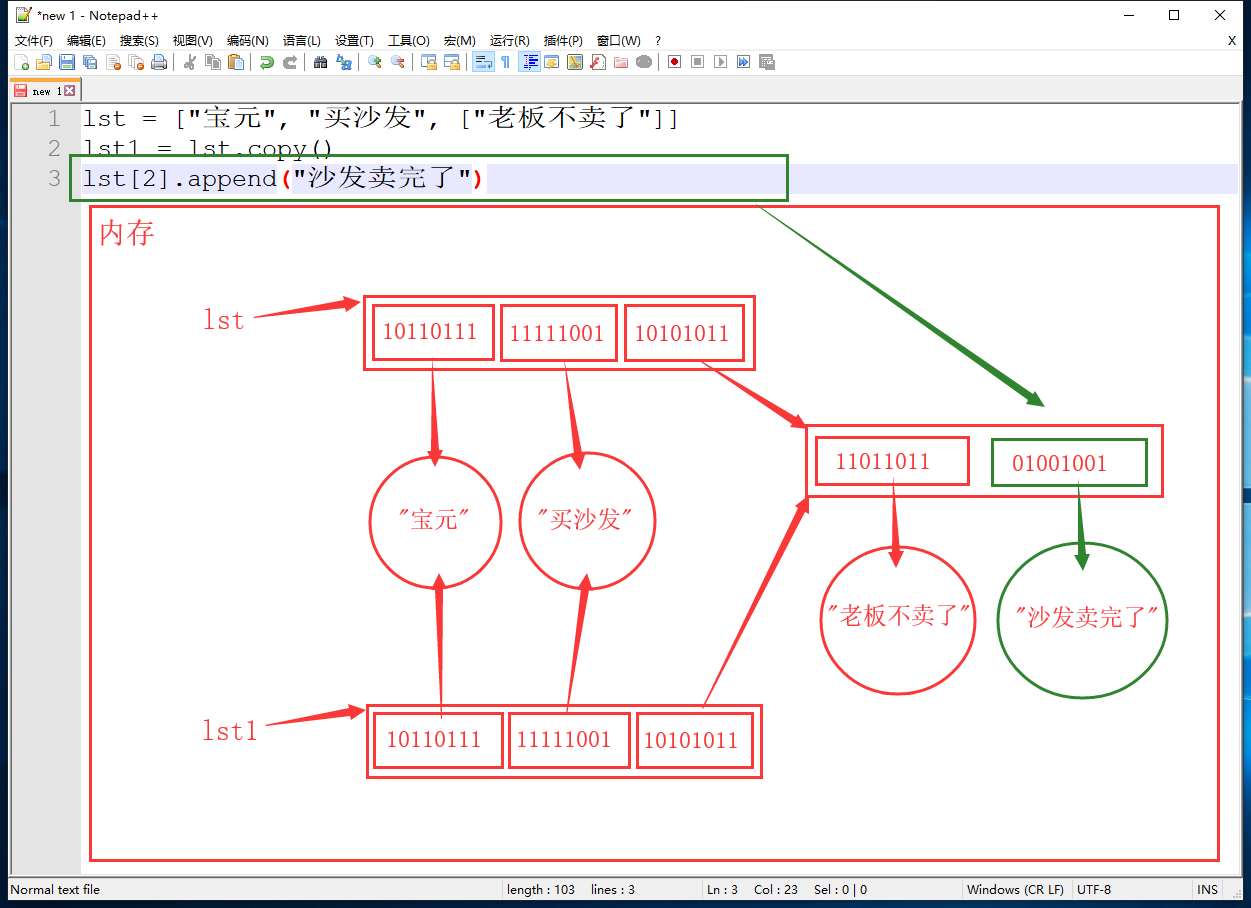
lst = ["宝元", "买沙发", ["老板不卖了"]] lst1 = lst.copy() lst[2].append("沙发卖完了") print(lst) # ['宝元', '买沙发', ['老板不卖了', '沙发卖完了']] print(lst1) # ['宝元', '买沙发', ['老板不卖了', '沙发卖完了']]- 当列表嵌套列表,向内层列表中添加元素时,浅拷贝内存的变化
![]()
-
由于浅拷贝只复制了外层列表中的数据的内存地址,导致原列表和copy列表都指向了内层列表的内存空间,当内层列表中添加数据时,两个列表都会发生变化,此时就要引出深拷贝
-
深拷贝方法
-
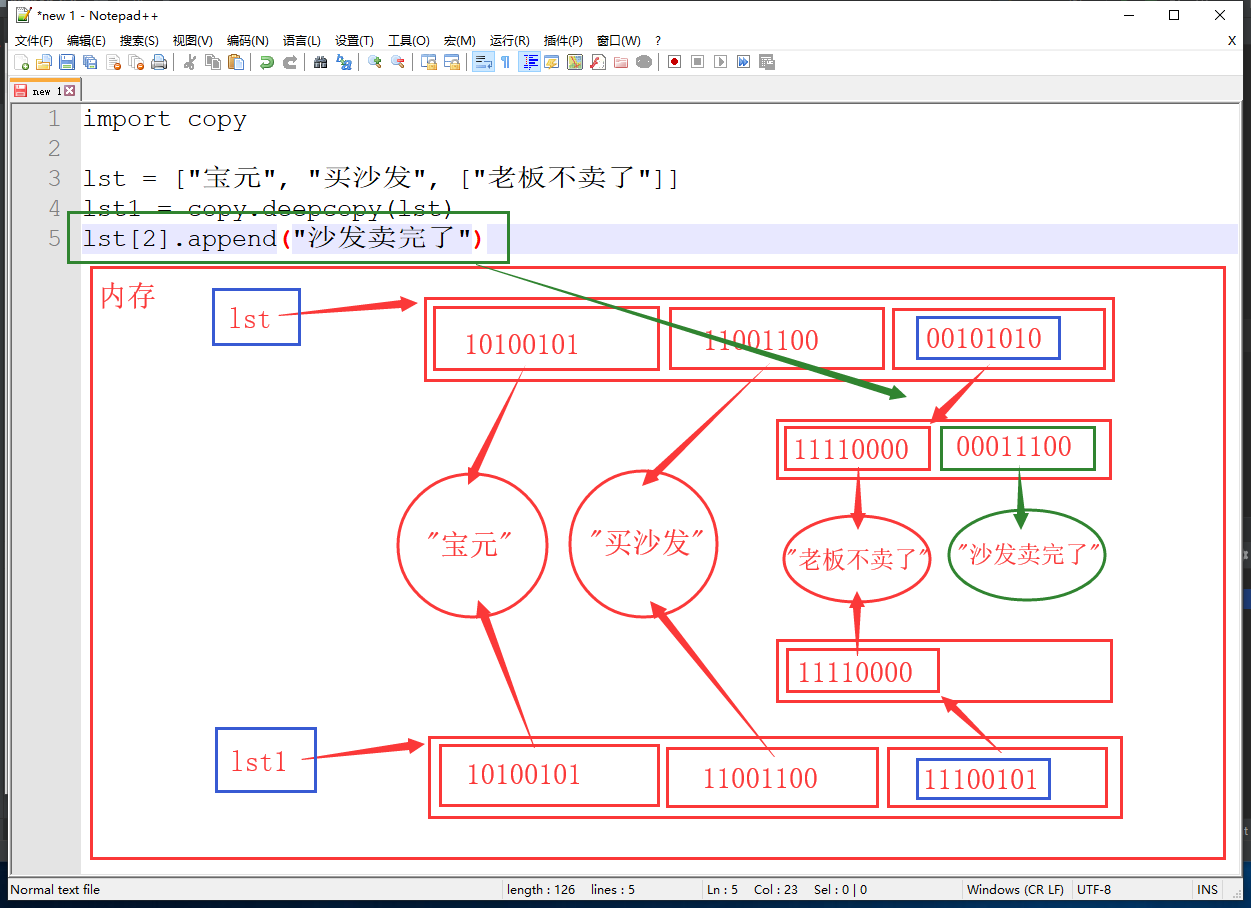
import copy lst = ["宝元", "买沙发", ["老板不卖了"]] lst1 = copy.deepcopy(lst) lst[2].append("沙发卖完了") print(lst) # ['宝元', '买沙发', ['老板不卖了', '沙发卖完了']] print(lst1) # ['宝元', '买沙发', ['老板不卖了']]
-
-
深拷贝,对内层数据修改后的内存变化
- 内层列表新增元素
![]()
- 内层列表修改元素
![]()
-
总结:
- 通过深拷贝得到的列表,无论内嵌多少个可变类型数据,只要数据是可变的,就会被copy一份,他们的内存地址就不相同(如上图蓝框)
- 而列表中不可变类型数据内存地址相同,指向同一个内存空间,换句话说不可变类型数据两个列表共用
- 换个说法,可以理解成通过深拷贝之后只要是可变类型数据就被复制了一份,而不可变类型数据是共用的

三、集合
(一)什么是集合
- 集合是一种可变类型数据、可迭代数据类型、无序数据结构
- 集合中的元素必须是可哈希的(不可变数据类型)
- 集合的一个重要应用:去重
- 空集合表示:
set()
(二)集合的增
-
set.add() 增加元素 set.update() 迭代增加
-
set.add()
- 向集合中添加元素
st = {"粪", "涂"} st.add("宝元") print(st) # {'粪', '涂', '宝元'} -
set.update()
- 向集合中迭代添加元素,重复的不添加
st = {"粪", "涂"} st.update("粪涂宝元") print(st) # {'宝', '粪', '涂', '元'}
(三)集合的删
-
set.pop() 随机删除 set.remove() 指定元素删除 set.clear() 清空集合
-
set.pop()
- 随机删除集合元素
- 此方法有返回值,返回的是删除的元素
st = {"粪", "涂", "宝元"} det = st.pop() print(det) # 涂 print(st) # {'宝元', '粪'} -
set.remove()
- 指定元素删除
st = {"粪", "涂", "宝元"} st.remove("涂") print(st) # {'宝元', '粪'} -
set.clear()
- 清空字典
st = {"粪", "涂", "宝元"} st.clear() print(st) # set()
(四)集合的改
-
先删除后添加
st = {"粪", "涂", "宝元"} st.remove("宝元") st.add("老郭") print(st) # {"粪", "涂", "老郭"} -
转换数据类型进行修改
st = {"粪", "涂", "宝元"} lst = list(st) index = lst.index("宝元") # 利用查看列表元素索引 lst[index] = "老郭" # 准确更改元素 st = set(lst) # 转回集合 print(st) # {'老郭', '涂', '粪'}
(五)集合的查
-
利用for循环查看集合元素
st = {"粪", "涂", "宝元"} for el in st: print(el, end=" ") # 粪 涂 宝元
(六)集合关系
-
set1 | set2 并集 set1 & set2 交集 set1 - set2 差集 set1 ^ set2 补集 set1 < set2 子集 set1 > set2 超集
-
set1 | set2
- 求 set1 和 set2 的的并集
set1 = {"DNF", "LOL"} set2 = {"DNF", "WOW"} print(set1 | set2) # {'DNF', 'LOL', 'WOW'} -
set1 & set2
- 求 set1 和 set2 的的交集
set1 = {"DNF", "LOL"} set2 = {"DNF", "WOW"} print(set1 & set2) # {'DNF'} -
set1 - set2
- 求 set1 和 set2 的的差集
set1 = {"DNF", "LOL"} set2 = {"DNF", "WOW"} print(set1 - set2) # {'LOL'} print(set2 - set1) # {'WOW'} -
set1 ^ set2
- 求 set1 和 set2 的的补集
set1 = {"DNF", "LOL"} set2 = {"DNF", "WOW"} print(set1 ^ set2) # {'LOL', 'WOW'} -
set1 < set2
- 判断 set1 是不是 set2 的子集
set1 = {"DNF"} set2 = {"DNF", "WOW"} print(set1 < set2) # True print(set1 > set2) # False -
set1 > set2
- 判断 set1 是不是 set2 的超集
set1 = {"DNF", "LOL"} set2 = {"DNF"} print(set1 < set2) # False print(set1 > set2) # True

 浙公网安备 33010602011771号
浙公网安备 33010602011771号