redis的前世今生http://doc.redisfans.com/
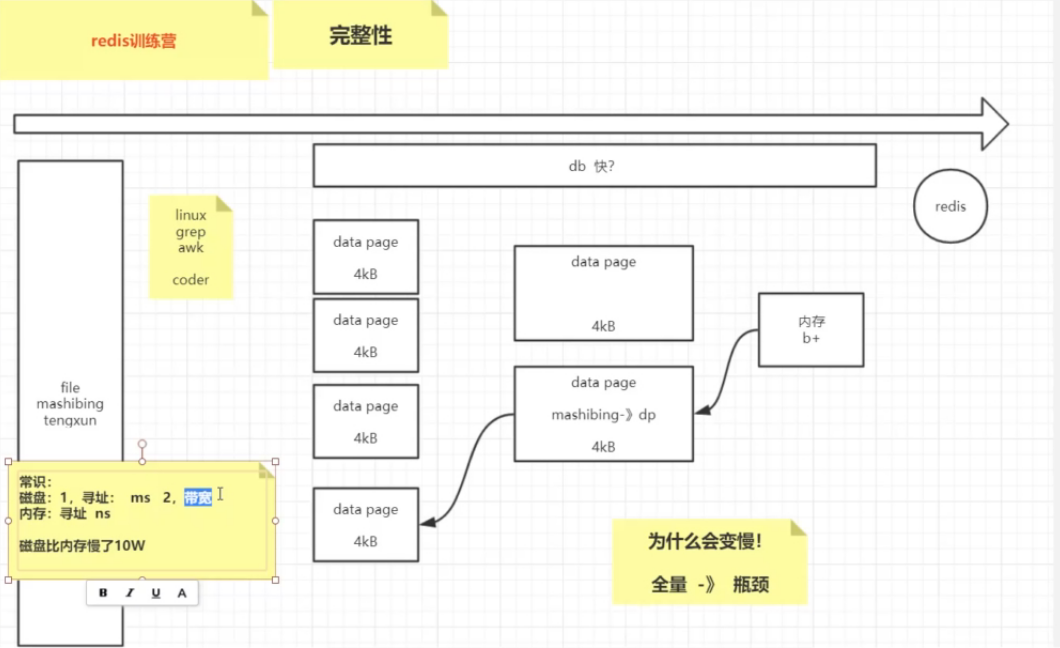
数据的存储方式
存储位置 | 磁盘 | 内存 |
存储特点 | 寻址、受带宽影响 | 寻址 |
查询时间 | ms级别,比内存满10万倍 | ns级别 |
远古时期:数据都存储在文件中,每次访问指定数据都要在文件中全量查询,一条不漏。如果文件过大,整个检索就相当耗费时间。
近古时期:为了解决"dataSource"过大的问题,提出了一个新的理论——"分制"。把一个大文件拆成很多小文件,在检索时对小文件进行查询。查到即止,也就是数据库。但是随之而来出项的问题就是,如果查询的文件恰好是10w+小文件中的最后有一个。那不就是等同于全量查询。为了解决这个问题,又提出了一个新的理论——索引。在分制之后在新建一个表,里面存储的记录小于全量
???提出问题?问什么不把全量数据全部放到内存当中?
1、虽然内存访问快,但是内存一般保存热数据,关机即毁。
2、全部放到内存中,造价高,虽然相等的容量内存可以存储的数据更多。(SAP公司的hada数据库就是在内存中,内存2T,硬盘1T,全套设备2亿)
但是,办法总比无问题多。
现在,内存和数据库决定各退一步,一起来解决这个问题,将全量数据放在磁盘,提取其中一部分热门数据放在内存中。
于是就诞生了Redis和mamcache。这两种技术都是key、Value存储结构。
而数据库是关系型结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号