

什么是K-均值算法
K-均值算法是一种常用的聚类算法,用于将数据集划分为若干个互不重叠的簇。在无监督学习中,聚类旨在发现数据的内在结构和模式,而不需要事先标记的类别信息。K-均值算法的目标是将数据点划分到K个簇中,使得簇内的点距离最小,而簇间的距离最大。
算法的原理很直观,首先需要确定簇的数量K。然后随机选择K个初始质心点,质心点可以看作是簇的代表。接下来,将所有数据点与这些质心点计算距离,并选择最近的质心点进行分类。完成分类后,计算每个簇内数据点的平均值,并将这些平均值作为新的质心点。不断重复以上步骤,直到质心点不再发生变化或变化很小,即达到收敛。
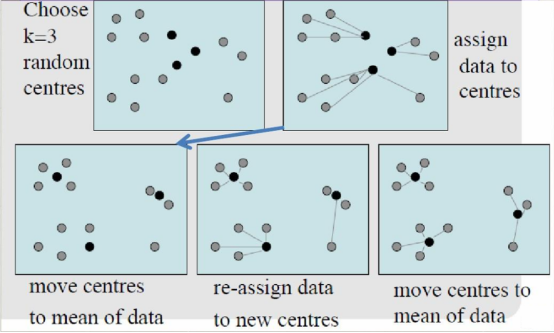
K-均值算法的优化目标是最小化目标函数,该函数是所有簇内各点到其质心点的距离之和。通过不断迭代,算法会不断优化质心点的位置,使得簇内距离最小化。
然而,K-均值算法也存在一些局限性。首先,它对簇的大小、密度和形状敏感。如果簇的大小不均匀,或者簇的密度不同,或者数据集包含非凸形状的簇,那么K-均值算法的效果可能不理想。其次,K-均值算法对初始质心点的选择非常敏感,不同的初始点可能导致不同的结果。
为了解决初始质心点选择的问题,可以采用K-均值算法的改进版本——K-均值++算法。该算法在初始质心点选择时考虑了点与质心点的距离,使得选择更具代表性且不易受异常值影响。
在选择K的值时,可以通过网格搜索等方法选择使目标函数值最小的K值,来确定最优的簇数量。
总而言之,可以帮助我们理解和发现数据集的内在结构和模式。通过迭代优化质心点的位置,K-均值算法能够将数据点划分为互不重叠的簇,以实现无监督学习的目标。然而,该算法对初始质心点的选择和数据集的特征敏感,需要在实际应用中进行适当调整和改进。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY