

机器学习——决策树模型
谈起过年回家的年轻人最怕什么、最烦什么?无外乎就是面对那些七大姑、八大姨的催结婚、催生子、催相亲、催买房……说起这些亲戚们是如何判断催什么,不得不让我们想起经典的决策树模型。

决策树是一个用于分类和回归的机器学习模型。通过对输入对象数据特征进行一系列条件划分构建一个树状结构的决策模型。每个内部节点表示一个特征或属性,每个分支代表该特征的一个可能取值,而每个叶节点代表一个类别标签或数值输出。我们的亲戚就是通过条件分类,从而判断出“催什么”。
决策树的构建过程通常从根节点开始,根据某个特征的取值将数据集分成不同的子集。然后对每个子集递归地应用相同的步骤,直到满足某个停止条件,例如达到最大深度、子集样本数量小于某个阈值等。在构建过程中,可以使用不同的划分准则来选择最优的特征和划分点,例如信息增益、基尼指数等。
决策树的优点包括可解释性强、处理离散和连续特征都较好、对缺失值和异常值有较好的容错能力。然而,决策树容易过拟合、对于某些问题可能存在局部最优解,并且对于特征之间的关联关系不够敏感。
为了减少过拟合,可以采用剪枝操作,即通过降低模型复杂度来提高泛化能力。常见的剪枝方法有预剪枝和后剪枝。预剪枝在构建过程中进行模型评估,若划分不再有效则停止划分;后剪枝则先构建完整的决策树,然后通过剪去子树并比较泛化能力来判断是否进行剪枝操作。
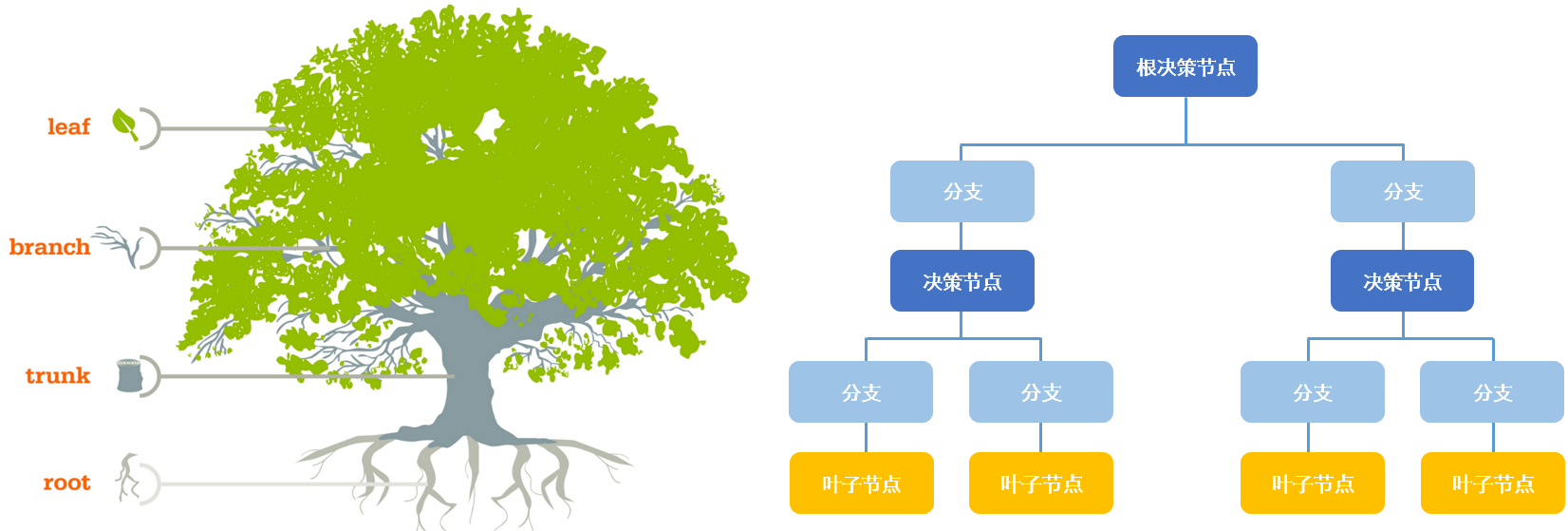
决策树模型经典的算法一般认为包含:ID3算法、C4.5算法、CART算法。
ID3算法:核心是在决策树各个节点上应用信息增益准则选择特征,递归地构建决策树。
C4.5算法:在生成决策树的过程中,改用信息增益比来选择特征。简单说是通过输入训练数据集、特征集A、阈值,从而输出:决策树T。
CART算法:由特征选择既可用于分类也可用于回归,通过构建树、修剪树、评估树来构建二叉树。当终结点是连续变量时,该树为回归树;当终结点是分类变量,该树为分类树。
如有疑问,点击链接加入群聊【信创技术交流群】:http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=EjDhISXNgJlMMemn85viUFgIqzkDY3OC&authKey=2SKLwlmvTpbqlaQtJ%2FtFXJgHVgltewcfvbIpzdA7BMjIjt2YM1h71qlJoIuWxp7K&noverify=0&group_code=721096495


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY