结合工程实践选题调研分析同类软件产品
我的工程实践选题是《针对领域知识的中文知识图谱自动化》。
知识图谱的应用涉及很多行业,包括搜索引擎、聊天机器人、大数据风控、智能医疗、个性化推荐、地图等等,以下给出几个例子。
(一)基于知识图谱的搜索引擎
以前在百度搜索引擎上搜索“地球的质量”,百度会将“地球的质量”这个字符串与其抓取的大规模网页作比对,根据网页与该查询词的相关程度以及网页本身的重要性,对网页进行排序,并作为搜索结果返回给用户,但是用户需要自己动手去访问这些网页来找自己所需的信息。这种传统搜索引擎的工作方式只是机械地比对查询词和网页之间的匹配关系,不能真正理解用户要查询的到底是什么。
知识图谱包含大量实体,以及各种实体之间丰富的关系。 基于知识图谱的搜索引擎相对于传统搜索引擎的工作方式大大改善了搜索结果,能够精确理解用户的问题,并能给出个性化结果。如图1所示,在百度搜索引擎上搜索“地球的质量”,百度精确给出了地球质量是“5.965*1024kg”,并在右侧给出该查询词其他相关实体。
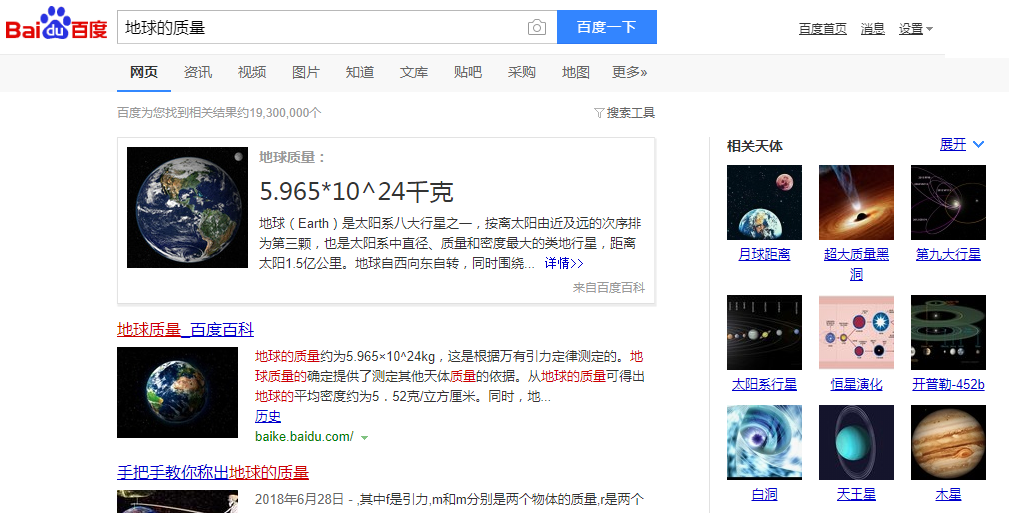 |
| 图1 - 百度搜索“地球的质量” |
(二)知识图谱在金融领域的应用
以信用卡申请反欺诈为例。
银行信用卡申请欺诈是指申请者使用本人或他人身份,来伪造虚假身份进行信用卡申请、贷款申请、恶意透支等欺诈行为。欺诈者一般会共用合法联系人的一部分信息,如电话号码、联系地址、联系人手机号等,并通过它们的不同组合构建多个合成身份。比如,假设3个人共用电话、地址两个信息,那么可以合成9个假身份,假设每个合成身份分别有5个账户,总共就有45个账户,假设每个账户的信用等级为20,000元,那么银行的损失高达900,000元。也即,欺诈者通过共用的信息构成欺诈环。
采用传统关系数据库来揭露欺诈环需要技术人员执行一系列的复杂连接,而且查询构建非常复杂,查询效率低、速度慢且成本高。
通过融合来自不同数据源的信息构成知识图谱,同时引入金融领域专家建立业务专家规则,能使银行在贷前预防风险,在贷中进行关联分析找出可疑点,控制风险,在贷后风险把关,将损失降到最低。具体操作是将银行欺诈环节可能涉及的信息,如“申请号”、“账户”、“身份证”、“手机号”、“地址”、“联系人”等设计成知识图谱的节点,并定义这些节点的属性以及节点之间的关系。用户在这种基于知识图谱的平台上输入某节点值,查询该节点的关联信息,比如输入某借款人姓名UserA,查看该借款人的同事有UserB,但UserA和UserB填写的公司名不一样,再比如输入一个电话号码,发现该电话号码属于两个借款人,这些不一致行为很可能存在欺诈行为。
(三)其他
智能问答
智能问答是指用户与机器之间像人一样交流,机器根据用户的问话给出答案。比如,聊天机器人依赖开放领域的知识图谱为用户提供日常知识;某行业使用的智能问答系统依赖该行业知识图谱,知识集中在该领域,为用户提供有针对性的专业领域知识。
个性化推荐
个性化推荐是代替用户评估其从未看过、接触过和使用过的物品。传统推荐系统分为两类,一类是评分预测,如电影类应用根据用户对电影的评分,推送其可能喜欢的电影,另一类是点击率预测,如新闻类应用根据用户点击某新闻的概率来优化推荐。传统推荐系统存在两个问题,一是可能会使用少量的已观测数据来预测大量的未知信息,极大地增加算法过拟合风险,二是系统中没有新用户或新物品的历史交互信息,因此无法准确地推荐。为了解决这两个问题,需要在推荐算法中额外引入一些辅助信息作为输入,从各种辅助信息中提取有效的特征。在众多辅助信息中,知识图谱包含了实体之间丰富的语义关联,能为推荐系统更好的、更精确的提供潜在辅助信息来源。
