
如何设计Kafka?
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:Sugar Su
链接:http://zhuanlan.zhihu.com/ms15213/20545422
来源:知乎
此文稿来源于太阁实验室每周三晚上的weekly tech show,活动注册链接:https://attendee.gotowebinar.com/register/1150708559813755649
下期活动为:Spark内核架构设计与实现原理
Kafka是一个分布式的消息系统,以可水平扩展和高吞吐量和准实时性而被广泛使用。我们从三个方面来引出和介绍Kafka。
1. How to design Google Analytics?
2. What is Kafka?
3. How to scale and survive?
1. How to design Google Analytics?
1) what is Google Analytics?
Google Analytics是统计网站数据的服务。如下图:
from: Top 20 Google Analytics Blogs in 2015
2) can we understand it with an easier case?
网站的统计服务较为复杂,我们先看一下如何统计一个短链接的访问数据?
如用户地区分布、用户浏览器类型等等,如下图。
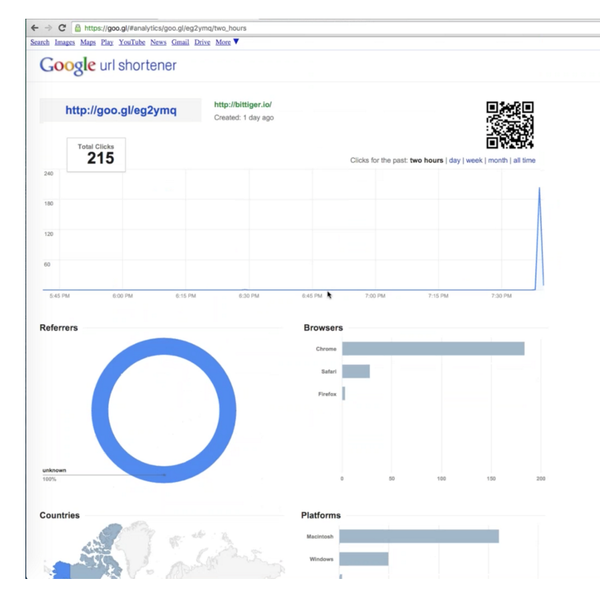
3) how to calculate the distribution of countries in the last hour?
统计的基础是log。web server的log是访问短链接的用户的信息。
4) where is data?
一个典型的Kafka集群包含若干Producer,若干broker,若干Consumer Group,以及一个Zookeeper集群。其中producer负责收集log信息(如web服务器的PageView,服务器CPU状态日志等),并且发送给broker,broker将log发送到相关的consumers。
这是经典的生产者消费者模型
5) how to calculate the last minute/hour/day/month/year?
Producer产生每个log,传给broker,broker可以分给多个consumer,它们分别计算过去每分钟,小时,天的数据。
在设计一个Consumer的处理逻辑的时候,可以使用buckets的方案。比如要存每分钟的数据,可以使用两个buckets A和B。一个分钟使用bucker A,一分钟使用bucket B。将这个方案扩展,如果我们需要的是过去两小时内每分钟的数据,那么针对这个consumer,我们需要121个bucket(120mins),我们可以使用环形链表或者queue的数据结构来存储。我们每分钟轮换一个bucket来存储信息。。
6) how to do it in real time?
假设每秒有一百万的日志需要处理,就轮到Kafka登场了
2. What is Kafka?
1) what is Kafka?
Kafka是一种分布式的,基于发布/订阅的消息系统。它的大体框架由producer,broker和consumer构成,producer传message给broker,broker传message给consumer。
2) push or pull?
在producer和broker之间,可以选择push或者pull两种模式。如果broker每次都从producer pull数据的话,往往需要在producer的本地维持一个较大的log缓存,保存broker pull之前需要存储的数据,这会增加很多复杂度。如果是从producer push的话,broker的设计会相对简单。因此Kafka使用了push模式。
push也会引入阻塞的问题。如果producer用的流量太多,会阻碍其他producer的数据传输。因此在最新版的Kafka中引入了限流。
Kafka的设计包括两部分:
-
监控:使用30个buckets,每个bucket记录1秒的流量
-
限制。当broker监控到一个producer超过限值的时候,延迟response消息的发送时间来减缓producer的流量
由于Kafka的设计基于良性环境(假设所有P都是好人),所以不会出现producer故意忽略response的事情。
我们这里留下一个思考题?在broker和consumer之间,是push还是pull呢?
3) is message the same as log?
log更强调行为记录,message强调消息传输,在使用的时候这两个词常常互换。
4) what is the format of messages?
message一定要有ID吗?不一定。message核心是binary content,broker不需要知道它是什么。
message的属性主要有length,CRC,state数据(记录是否为特殊message,比如0指无特殊意义的message,1,2,3...对应不同的特殊message)。
CRC是校验和,用来验证数据是否出现错误。,它性能好、校验率高,广泛应用于各类文件系统中,如Google File System。如果CRC自己传错了怎么办?CRC错了就认为整个包是错的,不需要区分具体是谁错的,不用overthinking。
5) how to identify the message to be read now?
broker里存了很多message,consumer用offset就可以知道读到哪个消息了。
Kafka最早的做法是将所有consumer的offset存在zookeeper里。此时zookeeper类似于一个分布式的database。每个用户读之前,可以从database里找到对应的读取位置。这样即使consumer失败了,offset数据也不会丢失
当consumer很多的时候,zookeeper会成为性能瓶颈。因此最新版的Kafka中会专门将offset存储于一个特定的compacted topic里面。这个topic有50个partition,每个partition的Leader Broker会做为一些consumer group的coordinator。因此这些coordinator会取代zookeeper来协调consumer group。
当然,我们也可以将offset存储于consumer处,进行进一步的定制。
6) do we need index for log?
不需要。因为message是自然排序。如果它们在内存里,只需要二叉查找。Kafka不关心message发送时的顺序,而是使用接收到的时间来排序。但是message里面可以有timestamp等信息,如LogAppendTime。
3. How to scale and survive
1) how to deal with the failure of a consumer?
当consumer失败时,可能会造成broker overflow。因为短时间内message依旧源源不断从producer传给broker。
在Kafka里log是持久化的,也就是把message写入disk中。因此能够应对大多数message overflow的问题。
2) how to save message into disk?
因为message是序列写在disk,用时相对较短。虽然memory速度至少是disk的十倍以上,但是因为Kafka可以通过一些优化让硬盘达到和内存相匹敌的速度。例如使用磁盘阵列,同时有5个列,每个阵列都是4块硬盘。把一个数据拆成不部分,比如C1, C2, C3和Cp。不同部分可以同时写入阵列中,也就是让几十块硬盘同时运转,从而大大缩短了速度。
此外,Kafka也复用了OS的Page Cache,因此很多写也是首先在内存中完成的。
在消息存储上,Kafka会构建虚拟地址,每个消息记录它的offset,并且将offset做为该消息的ID,从而通过ID能够快速找到硬盘的相应位置。
进一步来说,对于一个topic的整个消息,Kafka会存放在硬盘上的多个文件中,每个文件的文件名就是存于该文件的第一个message的offset。Kafka同时会在内存中构建所有文件的offset的列表,因此能够基于一个message的offset,在内存中快速定位到相应的文件,并且进一步得知在该文件内的偏移量。
为什么disk上不能存成一个文件?因为在disk上无法开出一片足够大的连续区域。即使开出足够大的连续区域,也会造成空间的浪费。
3) how to transfer message from disk into consumer?
传统的方法是将数据首先拷贝到kernel的空间,然后拷贝到用户空间,之后再拷贝回kernel空间,最后再送到网卡。在这个过程中需要四步拷贝,浪费了大量的时间和CPU资源。
因此Kafka往往借用OS提供的Zero Copy来一步将数据从硬盘拷贝到网卡。
4) how to deal with a huge amount of messages?
如果producer个数很多,可以使用多个broker。producer可以向多个broker里写数据。
如何决定某个producer写向哪个broker呢?最简单的方法就是round robin。还有种方法是利用key的hash来写入对应的broker。
一个topic也可以分配为多个不同的partition,在partition内部的消息是有序的,但是在partition之间的消息是无序的。当然我们也可以通过在message中加入timestamp的方式来维持消息的序列。
在Kafka中,topic指的是消息的一个集合。我们通过在发送消息和接收消息的时候指定topic来让每个consumer只是接收和处理属于自己的消息子集。
5) should we sync among partitions?
为了防止broker崩溃时引起的消息丢失,我们引入了primary(P)和slave(S)的概念。。P收到的每一条message都会同步给所有的S。因此在Kafka中,Primary被称为Leader,Slave被称为Follower。
为了提高性能,我们可能会动态添加新的broker。这是还需要手动的启动Partition Reassignment来迁移数据。
6) how to select the new leader after a failures?
如果之前的Leader失败,在剩下的followers中,谁的数据最全,就选这个broker做为新的P。
7) how to log the logs?
如果想统计在Kafka中,过去一分钟内收到了多少message。可以启动一个consumer接受所有的消息,并且每分钟将统计结果重新放回到Kafka的broker中。另外再启动一个consumer收集这些统计信息,从而给出报表。
8) how to compact the log?
对于key, value型log,可以删除历史信息,对log去冗余。比如log信息为K1=3, K1=7, K2=9, K1=5,前两个log都可以删掉,因为K1的终值是5。
时间关系无法将所有技术细节都涵盖,这里提供一些进一步学习的参考资料:

