
数据采集与融合第二次作业
数据采集与融合第二次作业
任务一:爬取中国天气网
本次作业要求爬取中国天气网的天气信息,在中国天气网(http://www.weather.com.cn)中输入一个城市的名称,例如输入福州,那么会转到地址http://www.weather.com.cn/weather1d/101230101.shtml的网页显示福州的天气预报,其中101230101是福州的代码,每个城市或者地区都有一个代码。爬取我们需要的天气预报数据,并存储到sqllite数据库weathers.db中。
所以我们的程序思路大致为:
1.依然是使用request和bs4来获取网页的HTML信息并观察分析
2.确定我们需要的信息所在的标签位置,使用select提取出来
3.创建一个database,并把数据存入其中
以下是源代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
#self代表类的实例,而非类。
#self不是关键字
#self的作用主要表示这个变量是类中的公共变量
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")#该API打开一个到 SQLite数据库文件database的链接,如果给定的数据库名称filename不存在,则该调用将创建一个数据库。
self.cursor = self.con.cursor()#创建一个 cursor【光标】
try:
self.cursor.execute(#执行一个 SQL 语句。该 SQL 语句可以被参数化(即使用占位符代替 SQL 文本)。
"create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values(?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "data", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"福州": "101230101", "清流": "101230803", "厦门": "101230201", "永安": "101230810"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + "code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["福州", "清流", "厦门", "永安"])
运行结果:

小结:本次作业思路和方法基本与前一次的作业相同,只是多了一步放入数据库。本次作业的源码是copy书上的,需要注意的是格式缩进,单纯复制粘贴是跑不了的。其次本次作业加深了我对self的理解,self代表类的实例,而非类。self不是关键字,self的作用主要表示这个变量是类中的公共变量。
任务二:爬取东方财富网
本次作业要求爬取东方财富网https://www.eastmoney.com/的股票信息,通过抓包获取数据集URL如抓包链接,下载股票信息,并通过对json解析对应数据集,并展示出来。
基本思路:
开始的想法也是和前几次一样,先获取HTML信息再进行提取,但是很快发现股票信息是js动态生成的,不能使用原生url直接提取,我们又还没有学习Scrapy,通过老师发的教程,我们需要通过浏览器F12进入开发者模式,再NetWork板块找到我们需要的url。(通过读大佬的blog知道我们需要的信息一般都在jQuery里)
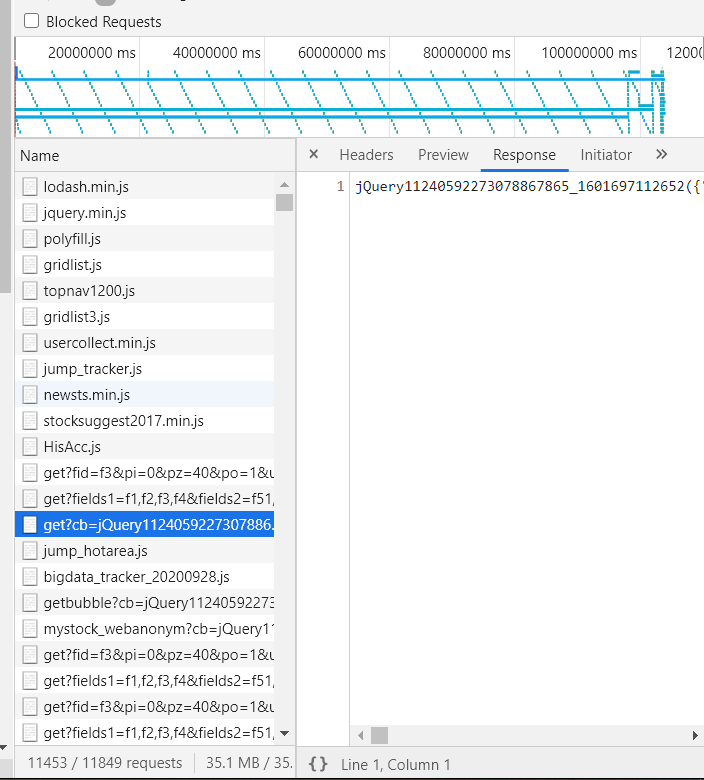
找到这条以后剩下的步骤又和前面大致相同了,只需要注意自己想要爬取的fs和页数还有F1-Fn的关键信息,根据具体情况随机应变对url进行改动。
觉得控制台输出并不是很直观,在大佬舍友的帮助下使用xlsxwriter将得到的数据存入xls表格中使输出的数据更加清晰明了。
以下是源代码:
import requests
import re
import xlsxwriter
def getHTML(fs,page):
# 通过观察我们可以发现,股票代码在f12,名称在f14,最新价f2,涨跌幅f3, 涨跌额f4,
# 成交量f5,成交额f6, 涨幅f7
pz = 20
fields = "f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
url = "http://58.push2.eastmoney.com/api/qt/clist/get?cb=" \
"jQuery112409968248217612661_1601548126340&pn=" \
+ str(page) + "&pz=" + str(pz) + "&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt" \
"=2&invt=2&fid=f3&fs=" + fs["沪深A股"] + "&fields=" + fields + "&_=1601548126345"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63"}
try:
res = requests.get(url, headers=headers)
pat = '"diff":\[(.*?)\]'
data = re.compile(pat, re.S).findall(res.text) # 对字符串进行预处理
# lst = listToJson(data)
# data_finall = json.dumps(data)
# print(data)
# print(data_finall)
datas = data[0].split("},{")
#print(datas)
return datas
except:
print('wrong url')
def create_Header(workbook):
# 创建表的基本框架
worksheet = workbook.add_worksheet() # 创建worksheet,写入数据
bold = workbook.add_format({'bold': True, 'font_color': 'red', 'align': 'center'})
worksheet.write('A1', '代码', bold)
worksheet.write('B1', '名称', bold)
worksheet.write('C1', '最新价', bold)
worksheet.write('D1', '涨跌幅', bold)
worksheet.write('E1', '涨跌额', bold)
worksheet.write('F1', '成交量', bold)
worksheet.write('G1', '成交额', bold)
worksheet.write('H1', '涨幅', bold)
# 设置列宽度
worksheet.set_column('A:A', 10)
worksheet.set_column('B:B', 10)
worksheet.set_column('C:C', 8)
worksheet.set_column('D:D', 8)
worksheet.set_column('E:E', 8)
worksheet.set_column('F:F', 10)
worksheet.set_column('G:G', 16)
worksheet.set_column('H:H', 8)
return worksheet
#得到每一页的股票数据
def getPageData(datas, row):
col = 0 # 初始列参数s
for i in range(len(datas)):
datas1 = datas[i].split(",")
#print(datas1)
Number = eval(datas1[11].split(":")[1])
Name = eval(datas1[13].split(":")[1])
Newest_price = eval(datas1[1].split(":")[1])
updownExtent = eval(datas1[2].split(":")[1])
updownValue = eval(datas1[3].split(":")[1])
Money_number = eval(datas1[4].split(":")[1])
Money = eval(datas1[5].split(":")[1])
Up_number = eval(datas1[6].split(":")[1])
#print(Number,Name,Newest_price,updownExtent,updownValue,Money_number,Money,Up_number)
worksheet.write(row, col, Number)
worksheet.write(row, col + 1, Name)
worksheet.write(row, col + 2, Newest_price)
worksheet.write(row, col + 3, updownExtent)
worksheet.write(row, col + 4, updownValue)
worksheet.write(row, col + 5, Money_number)
worksheet.write(row, col + 6, Money)
worksheet.write(row, col + 7, Up_number)
row += 1
if __name__ == '__main__':
fs = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23"
}
# 设置要爬取的页数
page = 3
row = 1 # 初始行参数
name = "沪深A股"
workbook = xlsxwriter.Workbook(name + '.xlsx') # 新建表
worksheet = create_Header(workbook)
for p in range(page):
datas = getHTML(fs, p+1)
getPageData(datas, row)
row += 20
try:
print("\n 存储成功!")
workbook.close()
print("\n ------爬取结束------")
except:
print("\n-------------------文档关闭失败----------------\n")
print("--------------请先关闭 Excel 再重新爬取--------")
运行结果:
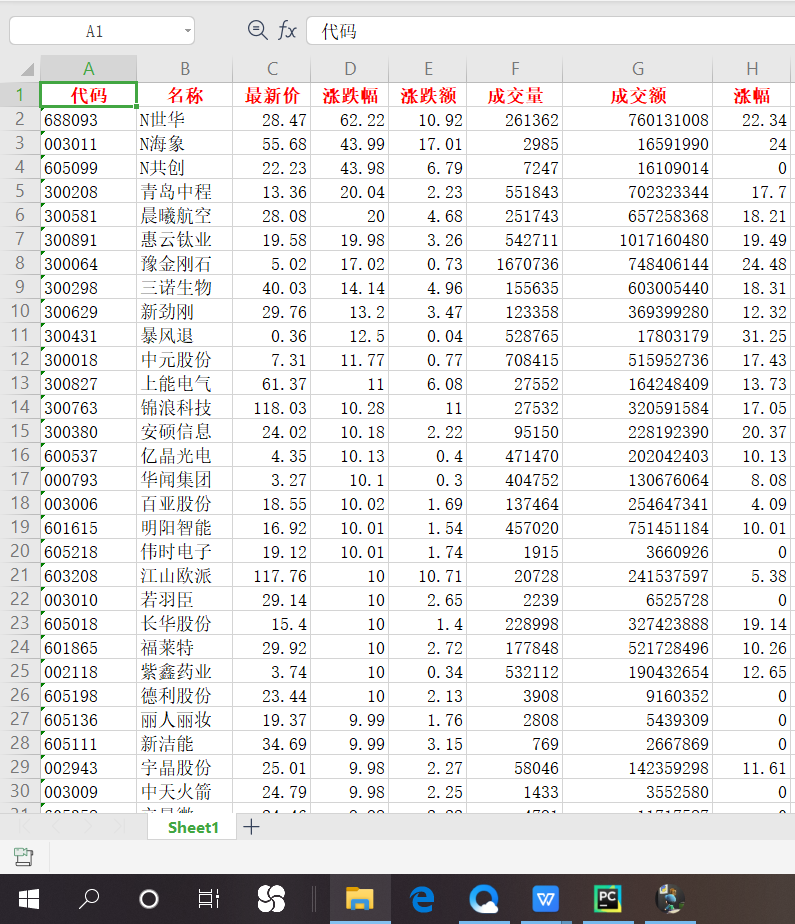
小结:这次作业的难度对我来说有点高,在参考了前面的优秀同学的blog后又在舍友的帮助下debug了一个晚上才完成,开始老是出现表格覆盖写只能输出爬取的最后一页的问题,在多次debug和“奇怪の调整”后突然就正常了,感觉还是很有趣的(...)。
任务三:根据学号后三位爬取股票信息
有了前面的成果,这个任务就变得十分简单了,只需要加一个endswith('134')(我的学号后三位就可以了)
以下是源代码:
import requests
import re
import xlsxwriter
def getHTML(fs,page):
# 通过观察我们可以发现,股票代码在f12,名称在f14,最新价f2,涨跌幅f3, 涨跌额f4,
# 成交量f5,成交额f6, 涨幅f7
pz = 20
fields = "f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
url = "http://58.push2.eastmoney.com/api/qt/clist/get?cb=" \
"jQuery112409968248217612661_1601548126340&pn=" \
+ str(page) + "&pz=" + str(pz) + "&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt" \
"=2&invt=2&fid=f3&fs=" + fs["沪深A股"] + "&fields=" + fields + "&_=1601548126345"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63"}
try:
res = requests.get(url, headers=headers)
pat = '"diff":\[(.*?)\]'
data = re.compile(pat, re.S).findall(res.text) # 对字符串进行预处理
# lst = listToJson(data)
# data_finall = json.dumps(data)
# print(data)
# print(data_finall)
datas = data[0].split("},{")
#print(datas)
return datas
except:
print('wrong url')
def create_Header(workbook):
# 创建表的基本框架
worksheet = workbook.add_worksheet() # 创建worksheet,写入数据
bold = workbook.add_format({'bold': True, 'font_color': 'red', 'align': 'center'})
worksheet.write('A1', '代码', bold)
worksheet.write('B1', '名称', bold)
worksheet.write('C1', '最新价', bold)
worksheet.write('D1', '涨跌幅', bold)
worksheet.write('E1', '涨跌额', bold)
worksheet.write('F1', '成交量', bold)
worksheet.write('G1', '成交额', bold)
worksheet.write('H1', '涨幅', bold)
# 设置列宽度
worksheet.set_column('A:A', 10)
worksheet.set_column('B:B', 10)
worksheet.set_column('C:C', 8)
worksheet.set_column('D:D', 8)
worksheet.set_column('E:E', 8)
worksheet.set_column('F:F', 10)
worksheet.set_column('G:G', 16)
worksheet.set_column('H:H', 8)
return worksheet
#得到每一页的股票数据
def getPageData(datas, row):
col = 0 # 初始列参数s
for i in range(len(datas)):
datas1 = datas[i].split(",")
#print(datas1)
Number = eval(datas1[11].split(":")[1])
Name = eval(datas1[13].split(":")[1])
Newest_price = eval(datas1[1].split(":")[1])
updownExtent = eval(datas1[2].split(":")[1])
updownValue = eval(datas1[3].split(":")[1])
Money_number = eval(datas1[4].split(":")[1])
Money = eval(datas1[5].split(":")[1])
Up_number = eval(datas1[6].split(":")[1])
#print(Number,Name,Newest_price,updownExtent,updownValue,Money_number,Money,Up_number)
if str(Number).endswith("134"):
count = 1
print('{0:4}\t{1:8}\t{2:<8}\t{3:<8}\t{4:<8}\t{5:<8}\t{6:<8}\t{7:<15}\t{8:<10}\t'.format(count, Number, Name, Newest_price,str(updownExtent)+"%", updownValue, Money_number,Money,str(Up_number)+"%"))
count +=1
worksheet.write(row, col, Number)
worksheet.write(row, col + 1, Name)
worksheet.write(row, col + 2, Newest_price)
worksheet.write(row, col + 3, updownExtent)
worksheet.write(row, col + 4, updownValue)
worksheet.write(row, col + 5, Money_number)
worksheet.write(row, col + 6, Money)
worksheet.write(row, col + 7, Up_number)
row += 1
if __name__ == '__main__':
fs = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23"
}
# 设置要爬取的页数
page = 200
row = 1 # 初始行参数
name = "沪深A股"
print('{0:4}\t{1:8}\t{2:<8}\t{3:<8}\t{4:<8}\t{5:<8}\t{6:<8}\t{7:<15}\t{8:<10}\t'.format('序号', '代码', '名称', '最新价',
'涨跌幅', '涨跌额', '成交量',
'成交额', '振幅'))
workbook = xlsxwriter.Workbook(name + '.xlsx') # 新建表
worksheet = create_Header(workbook)
for p in range(page):
datas = getHTML(fs, p+1)
getPageData(datas, row)
row += 20
try:
print("\n 存储成功!")
workbook.close()
print("\n ------爬取结束------")
except:
print("\n-------------------文档关闭失败----------------\n")
print("--------------请先关闭 Excel 再重新爬取--------")
运行结果:
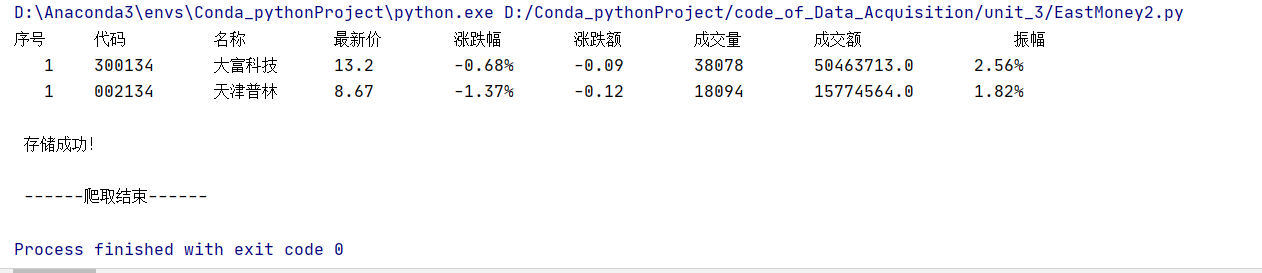
小结:爬取了200页就两支股票是我的学号后三位结尾,行情走势都还不好,真是太令人伤心了。
总结与反思
本次作业总的来说难度中上,对我这种小菜鸡具有一定的挑战,通过本次作业,使我对self,json的网页生成原理以及xlsxwriter函数的使用有了更好的认识和理解,同时也加强了一定的debug能力,同时也反应了我对代码的独自处理能力偏弱,如果没有同学的blog参考和舍友的帮助大概率是弄不出来,需要多加练习...
