
cuda中用cublas库做矩阵乘法
这里矩阵C=A*B,原始文档给的公式是C=alpha*A*B+beta*C,所以这里alpha=1,beta=0。
主要使用cublasSgemm这个函数,这个函数的第二个参数有三种类型,这里CUBLAS_OP_N求出来矩阵结果是按行排列,所以不需要转置了。
如果用CUBLAS_OP_T参数求得的结果是按列排列,做成C形式的矩阵应该还需要转置一下,并且后面跟的参数也不太一样,这个参数我就没再尝试了。
代码如下:

#include "cuda_runtime.h" #include "cublas_v2.h" #include <stdio.h> #include <stdlib.h> #include <iostream> #include <ctime> using namespace std; int main() { srand(time(0)); int M = 2; //矩阵A的行,矩阵C的行 int N = 3; //矩阵A的列,矩阵B的行 int K = 4; //矩阵B的列,矩阵C的列 float *h_A = (float*)malloc(sizeof(float)*M*N); float *h_B = (float*)malloc(sizeof(float)*N*K); float *h_C = (float*)malloc(sizeof(float)*M*K); for (int i = 0; i < M*N; i++) { h_A[i] = rand() % 10; cout << h_A[i] << " "; if ((i + 1) % N == 0) cout << endl; } cout << endl; for (int i = 0; i < N*K; i++) { h_B[i] = rand() % 10; cout << h_B[i] << " "; if ((i + 1) % K == 0) cout << endl; } cout << endl; float *d_A, *d_B, *d_C,*d_CT; cudaMalloc((void**)&d_A, sizeof(float)*M*N); cudaMalloc((void**)&d_B, sizeof(float)*N*K); cudaMalloc((void**)&d_C, sizeof(float)*M*K); cudaMemcpy(d_A, h_A, M*N * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, N*K * sizeof(float), cudaMemcpyHostToDevice); float alpha = 1; float beta = 0; //C=A*B cublasHandle_t handle; cublasCreate(&handle); cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, K, //矩阵B的列数 M, //矩阵A的行数 N, //矩阵A的列数 &alpha, d_B, K, d_A, N, &beta, d_C, K); cudaMemcpy(h_C, d_C, M*K * sizeof(float), cudaMemcpyDeviceToHost); for (int i = 0; i < M*K; i++) { cout << h_C[i] << " "; if ((i+1)%K==0) cout << endl; } cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); free(h_A); free(h_B); free(h_C); return 0; }
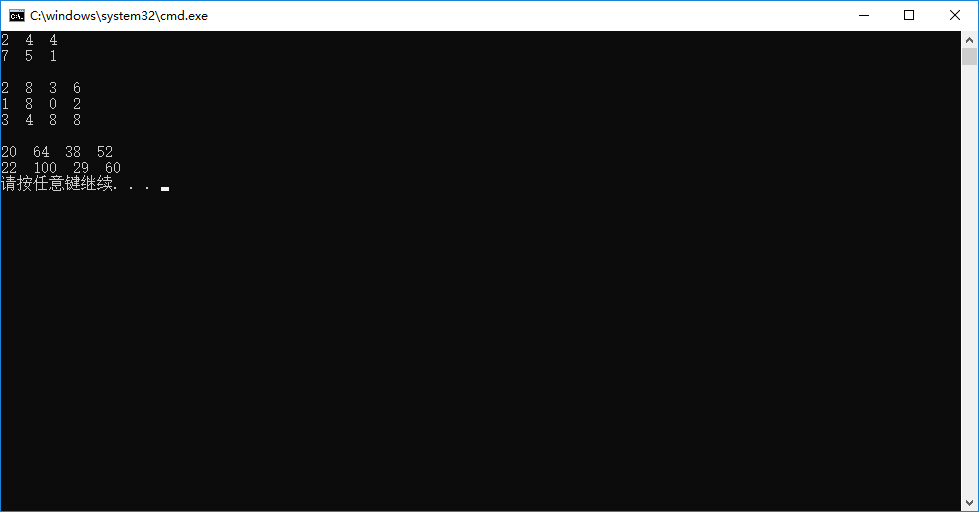
结果:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构