【Python】强化学习SARSA走迷宫
之前有实现Q-Learning走迷宫,本篇实现SARSA走迷宫。
Q-Learning是一种off-policy算法,当前步采取的决策action不直接作用于环境生成下一次state,而是选择最优的奖励来更新Q表。
更新公式:
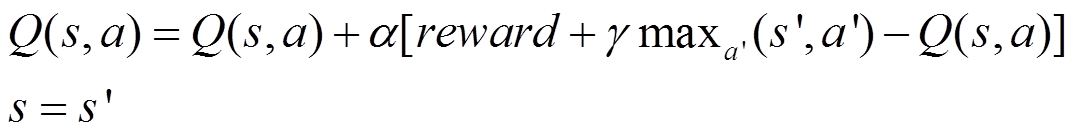
SARSA是一种on-policy算法,当前步采取的策略action既直接作用于环境生成新的state,也用来更新Q表。
更新公式:
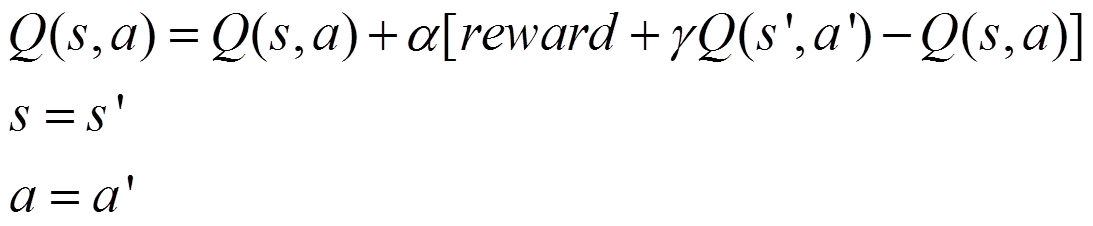
其中s是当前状态,a是当前动作,s’是下次状态,a'是下次动作。
代码如下:
import numpy as np import random import matplotlib.pyplot as plt from PIL import Image import imageio import io H = 30 W = 40 start = (0, random.randint(0, H-1)) goal = (W-1, random.randint(0, H-1)) img = Image.new('RGB', (W, H), (255, 255, 255)) pixels = img.load() maze = np.zeros((W, H)) for h in range(H): for w in range(W): if random.random() < 0.1: maze[w, h] = -1 actions_num = 4 actions = [0, 1, 2, 3] q_table = np.zeros((W, H, actions_num)) rate = 0.5 factor = 0.9 images = [] for i in range(2000): state = start path = [start] action = np.random.choice(actions) while(True): next_state = None #执行该动作 if action == 0 and state[0] > 0: next_state = (state[0]-1, state[1]) elif action == 1 and state[0] < W-1: next_state = (state[0]+1, state[1]) elif action == 2 and state[1] > 0: next_state = (state[0], state[1]-1) elif action == 3 and state[1] < H-1: next_state = (state[0], state[1]+1) else: next_state = state if next_state == goal: #得到reward,到目标给大正反馈 reward = 100 elif maze[next_state] == -1: reward = -100 #遇见障碍物给大负反馈 else: reward = -1 #走一步给小负反馈,走的步数越小,负反馈越小 done = (next_state == goal) if np.random.rand() < 1.0/(i+1): #随机或者下一个状态最大q值对应的动作 next_action = np.random.choice(actions) else: next_action = np.argmax(q_table[next_state]) current_q = q_table[state][action] #根据公式更新qtable q_table[state][action] += rate * (reward + factor * q_table[next_state][next_action] - current_q) state = next_state action = next_action path.append(state) if done: break if i % 10 == 0: #每10次看结果 for h in range(H): for w in range(W): if maze[w,h]==-1: pixels[w, h] = (0, 0, 0) else: pixels[w, h] = (255, 255, 255) for x, y in path: pixels[x, y] = (0, 0, 255) pixels[start] = (255, 0, 0) pixels[goal] = (0, 255, 0) plt.clf() # 清除当前图形 plt.imshow(img) plt.pause(0.1) # 暂停0.1秒,显示动态效果 buf = io.BytesIO() plt.savefig(buf, format='png') # 保存图像到内存中 buf.seek(0) # 将文件指针移动到文件开头 images.append(imageio.imread(buf)) # 从内存中读取图像并添加到列表中 plt.show() imageio.mimsave('result.gif', images, fps=3) # 保存为 GIF 图像,帧率为3
效果似乎没有Q-Learning好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号