
深度学习(VIT)
将Transformer引入图像领域之作,学习一下。
网络结构:
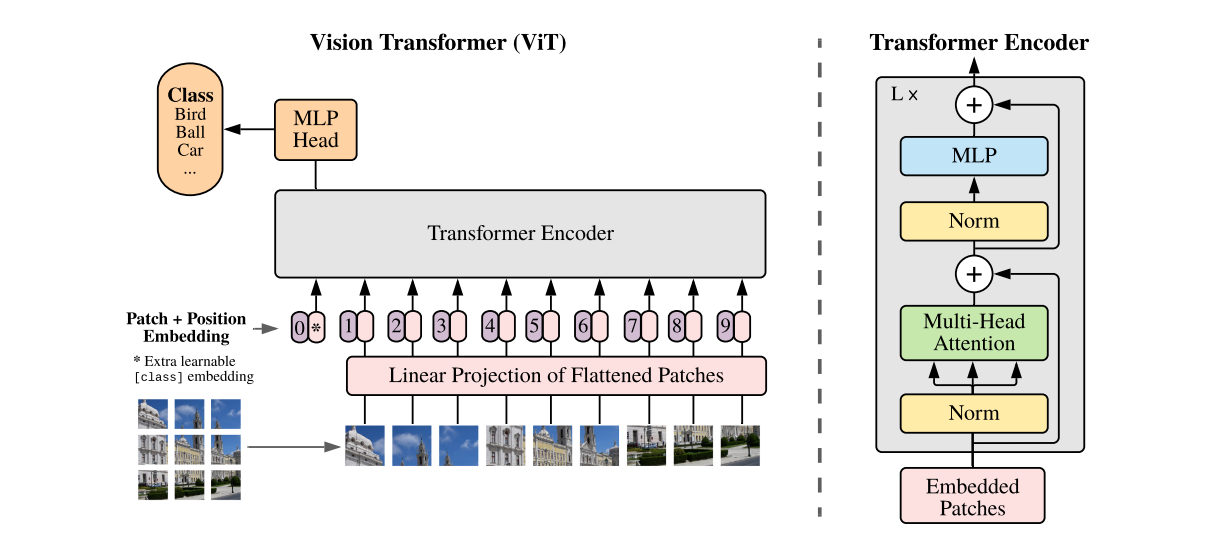
VIT结构有几个关键的地方:
1. 图像分块:输入图像被划分为固定大小的非重叠小块(patches),每个小块被展平并线性嵌入到一个固定维度的向量中。这里是将32x32的图像划分成4x4的小块,总共会有16个小块,每个小块有64维向量。
2. 位置编码:由于Transformer不具备位置敏感性,需要添加位置编码来提供位置信息。每个图像块向量都会加上一个对应的可学习的位置编码,以保留图像空间信息。
3. Transformer编码:嵌入向量连同位置编码一起被输入到Transformer编码器中,编码器由多个相同自注意力层堆叠而成。
4. MLP分类。
测试代码如下:
import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms from torchvision.datasets import CIFAR10 import torchvision.models class EmbedLayer(nn.Module): def __init__(self,channels, embed_dim,img_size,patch_size): super().__init__() self.embed_dim = embed_dim self.conv1 = nn.Conv2d(channels, embed_dim, patch_size, patch_size) self.pos_embedding = nn.Parameter(torch.zeros(1, (img_size // patch_size) ** 2,embed_dim), requires_grad=True) # Positional Embedding def forward(self, x): x = self.conv1(x) x = x.reshape([x.shape[0], self.embed_dim, -1]) x = x.transpose(1, 2) x = x + self.pos_embedding return x class SelfAttention(nn.Module): def __init__(self,embed_dim, heads): super().__init__() self.heads = heads self.embed_dim = embed_dim self.head_embed_dim = self.embed_dim // heads self.queries = nn.Linear(self.embed_dim, self.head_embed_dim * heads, bias=True) self.keys = nn.Linear(self.embed_dim, self.head_embed_dim * heads, bias=True) self.values = nn.Linear(self.embed_dim, self.head_embed_dim * heads, bias=True) def forward(self, x): m, s, e = x.shape q = self.queries(x).reshape(m, s, self.heads, self.head_embed_dim).transpose(1, 2) k = self.keys(x).reshape(m, s, self.heads, self.head_embed_dim).transpose(1, 2) v = self.values(x).reshape(m, s, self.heads, self.head_embed_dim).transpose(1, 2) q = q.reshape([-1, s, self.head_embed_dim]) k = k.reshape([-1, s, self.head_embed_dim]) v = v.reshape([-1, s, self.head_embed_dim]) k = k.transpose(1, 2) x_attention = q.bmm(k) x_attention = torch.softmax(x_attention, dim=-1) x = x_attention.bmm(v) x = x.reshape([-1, self.heads, s, self.head_embed_dim]) x = x.transpose(1, 2) x = x.reshape(m, s, e) return x class Encoder(nn.Module): def __init__(self, embed_dim,heads): super().__init__() self.attention = SelfAttention(embed_dim,heads) self.fc1 = nn.Linear(embed_dim, embed_dim * 2) self.activation = nn.GELU() self.fc2 = nn.Linear(embed_dim * 2,embed_dim) self.norm1 = nn.LayerNorm(embed_dim) self.norm2 = nn.LayerNorm(embed_dim) def forward(self, x): x = x + self.attention(self.norm1(x)) x = x + self.fc2(self.activation(self.fc1(self.norm2(x)))) return x class Classifier(nn.Module): def __init__(self, embed_dim,num_patches,classes): super().__init__() self.fc1 = nn.Linear(embed_dim*num_patches, embed_dim) self.activation = nn.Tanh() self.fc2 = nn.Linear(embed_dim, classes) def forward(self, x): x = x.view(x.shape[0],-1) x = self.fc1(x) x = self.activation(x) x = self.fc2(x) return x class VisionTransformer(nn.Module): def __init__(self,channels, embed_dim,n_layers,heads,img_size,patch_size,classes): super().__init__() self.embedding = EmbedLayer(channels,embed_dim,img_size,patch_size) self.encoder = nn.Sequential(*[Encoder(embed_dim,heads) for _ in range(n_layers)], nn.LayerNorm(embed_dim)) self.norm = nn.LayerNorm(embed_dim) self.classifier = Classifier(embed_dim,(img_size//patch_size)**2,classes) def forward(self, x): x = self.embedding(x) x = self.encoder(x) x = self.norm(x) x = self.classifier(x) return x if __name__ == '__main__': device = torch.device("cuda") trainTransforms = transforms.Compose([ transforms.ToTensor() , transforms.RandomHorizontalFlip(p=0.5) , transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) testTransforms = transforms.Compose([ transforms.ToTensor() , transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) trainset = CIFAR10(root='./data', train=True, download=True, transform=trainTransforms) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True) testset = CIFAR10(root='./data', train=False,download=False, transform=testTransforms) testLoader = torch.utils.data.DataLoader(testset, batch_size=128,shuffle=False) model = VisionTransformer(channels=3, embed_dim=128,n_layers=6,heads=8,img_size=32,patch_size=8,classes=10) # model = torchvision.models.resnet18(pretrained=True) # model.conv1 = nn.Conv2d(3, 64, 3, stride=1, padding=1, bias=False) # model.maxpool = nn.MaxPool2d(1, 1, 0) # model.fc = nn.Linear(model.fc.in_features, 10) criterion = nn.CrossEntropyLoss() optimizer = optim.AdamW(model.parameters(), lr=5e-4, weight_decay=1e-3) cos_decay = optim.lr_scheduler.CosineAnnealingLR(optimizer, 100, verbose=True) model.to(device) for epoch in range(50): print("epoch :",epoch) model.train() correct = 0 total = 0 for images, labels in trainLoader: images = images.to(device) labels = labels.to(device) outputs = model(images) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(loss.item(),f" train Accuracy: {(100 * correct / total):.2f}%") cos_decay.step() model.eval() with torch.no_grad(): correct = 0 total = 0 for images,labels in testLoader: images = images.to(device) labels = labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"test Accuracy: {(100 * correct / total):.2f}%") # 保存模型 torch.save(model.state_dict(), 'vit.pth')

