深度学习(UNet)
和FCN类似,UNet是另一个做语义分割的网络,网络从输入到输出中间呈一个U型而得名。
相比于FCN,UNet增加了更多的中间连接,能够更好处理不同尺度上的特征。
网络结构如下:
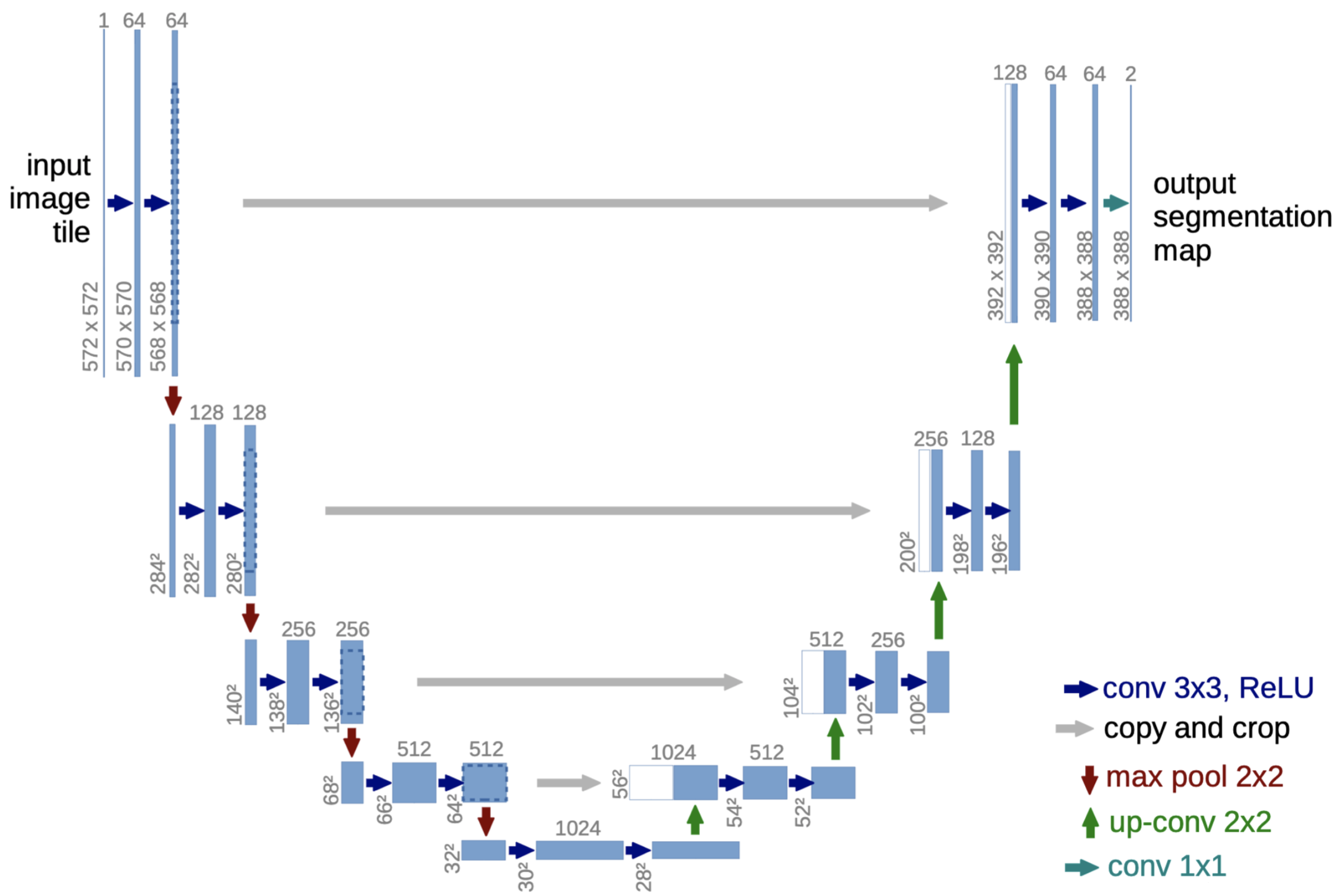
下面代码是用UNet对VOC数据集做的语义分割。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import Dataset,DataLoader from torchvision import transforms import os from PIL import Image import numpy as np transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") colormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128], [128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0], [64,128,0],[192,128,0],[64,0,128],[192,0,128], [64,128,128],[192,128,128],[0,64,0],[128,64,0], [0,192,0],[128,192,0],[0,64,128]] class VOCData(Dataset): def __init__(self, root): super(VOCData, self).__init__() self.lab_path = root + 'VOC2012/SegmentationClass/' self.img_path = root + 'VOC2012/JPEGImages/' self.lab_names = self.get_file_names(self.lab_path) self.img_names=[] for file in self.lab_names: self.img_names.append(file.replace('.png', '.jpg')) self.cm2lbl = np.zeros(256**3) for i,cm in enumerate(colormap): self.cm2lbl[cm[0]*256*256+cm[1]*256+cm[2]] = i self.image = [] self.label = [] for i in range(len(self.lab_names)): image = Image.open(self.img_path+self.img_names[i]).convert('RGB') image = transform(image) label = Image.open(self.lab_path+self.lab_names[i]).convert('RGB').resize((256,256)) label = torch.from_numpy(self.image2label(label)) self.image.append(image) self.label.append(label) def __len__(self): return len(self.image) def __getitem__(self, idx): return self.image[idx], self.label[idx] def get_file_names(self,directory): file_names = [] for file_name in os.listdir(directory): if os.path.isfile(os.path.join(directory, file_name)): file_names.append(file_name) return file_names def image2label(self,im): data = np.array(im, dtype='int32') idx = data[:, :, 0] * 256 * 256 + data[:, :, 1] * 256 + data[:, :, 2] return np.array(self.cm2lbl[idx], dtype='int64') class convblock(nn.Module): def __init__(self, in_channels, out_channels): super(convblock, self).__init__() self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1) self.bn1 = nn.BatchNorm2d(out_channels) self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1) self.bn2 = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU(inplace=True) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.conv2(x) x = self.bn2(x) x = self.relu(x) return x class Unet(nn.Module): def __init__(self, num_classes): super(Unet, self).__init__() self.conv_block1 = convblock(3,64) self.conv_block2 = convblock(64,128) self.conv_block3 = convblock(128,256) self.conv_block4 = convblock(256,512) self.conv_block5 = convblock(512,1024) self.upsample1 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2, padding=0) self.upsample2 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2, padding=0) self.upsample3 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2, padding=0) self.upsample4 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2, padding=0) self.conv_block6 = convblock(1024,512) self.conv_block7 = convblock(512,256) self.conv_block8 = convblock(256,128) self.conv_block9 = convblock(128,64) self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2) self.conv_out = convblock(64,num_classes) def forward(self, x): x1 = self.conv_block1(x) x = self.maxpool(x1) x2 = self.conv_block2(x) x = self.maxpool(x2) x3 = self.conv_block3(x) x = self.maxpool(x3) x4 = self.conv_block4(x) x = self.maxpool(x4) x = self.conv_block5(x) x = self.upsample1(x) x = torch.cat([x4,x],dim=1) x = self.conv_block6(x) x = self.upsample2(x) x = torch.cat([x3,x],dim=1) x = self.conv_block7(x) x = self.upsample3(x) x = torch.cat([x2,x],dim=1) x = self.conv_block8(x) x = self.upsample4(x) x = torch.cat([x1,x],dim=1) x = self.conv_block9(x) x = self.conv_out(x) return x def train(): train_dataset = VOCData(root='./VOCdevkit/') train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True) net = Unet(21) optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) criterion = nn.CrossEntropyLoss() net.to(device) net.train() num_epochs = 100 for epoch in range(num_epochs): loss_sum = 0 img_sum = 0 for inputs, labels in train_loader: inputs = inputs.to(device) labels = labels.to(device) outputs = net(inputs) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() loss_sum += loss.item() img_sum += inputs.shape[0] print('epochs:',epoch,loss_sum / img_sum ) torch.save(net.state_dict(), 'unet.pth') def val(): net = Unet(21) net.load_state_dict(torch.load('unet.pth')) net.to(device) net.eval() image = Image.open('./VOCdevkit/VOC2012/JPEGImages/2012_001064.jpg').convert('RGB') image = transform(image).unsqueeze(0).to(device) out = net(image).squeeze(0) ToPIL= transforms.ToPILImage() maxind = torch.argmax(out,dim=0) outimg = torch.zeros([3,256,256]) for y in range(256): for x in range(256): outimg[:,x,y] = torch.from_numpy(np.array(colormap[maxind[x,y]])) re = ToPIL(outimg) re.show() if __name__ == "__main__": train() #val()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号