深度学习(VGGNet)
VGGNet也是一个比较经典的深度学习网络模型。
模型结构如下:
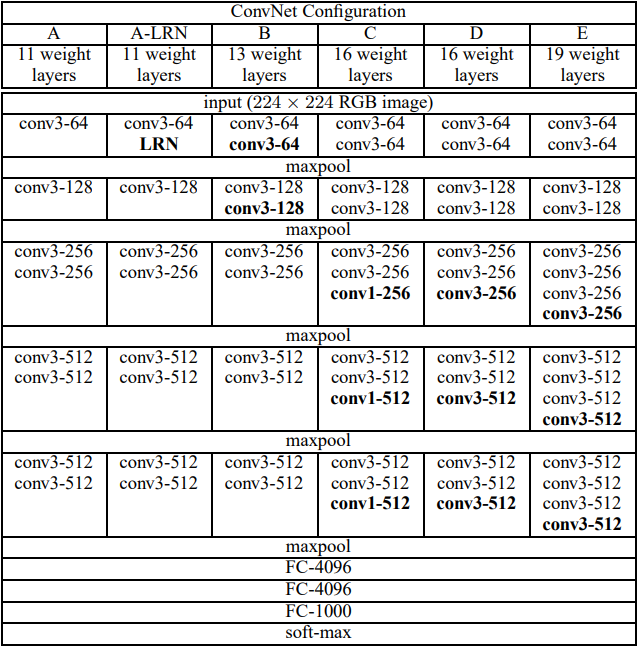
这里选用了D模型,同样用该模型做个了个猫狗大战的训练,不过为了提高速度,我把图像resize为112*112了,相应的flatten之后就成56*3*3了,所以和原始模型有点不一样。
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import Dataset, DataLoader import torchvision.transforms as transforms from PIL import Image # 定义VGGNet模型 class VGGNet(nn.Module): def __init__(self, num_classes=2): super(VGGNet, self).__init__() # VGGNet的卷积层部分由多个卷积块组成 self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2) ) # VGGNet的全连接层部分 self.classifier = nn.Sequential( nn.Flatten(), nn.Linear(512 * 3 * 3, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, num_classes) ) def forward(self, x): x = self.features(x) x = self.classifier(x) return x class CustomDataset(Dataset): def __init__(self, image_folder, transform=None): self.image_folder = image_folder self.transform = transform def __len__(self): return 25000 def __getitem__(self, index): image_name = str(index+1)+".jpg" image = Image.open(self.image_folder + '/' + image_name).convert('RGB') image = self.transform(image) if index < 12500: return image, 0 # cat else: return image, 1 # dog num_epochs = 10 # 创建VGGNet模型和优化器 model = VGGNet() # 加入L2正则化操作 regularization = 0.001 for param in model.parameters(): param.data = param.data + regularization * torch.randn_like(param) optimizer = optim.Adam(model.parameters(), lr=0.0001) criterion = nn.CrossEntropyLoss() # 定义训练和测试数据集的转换方式 transform = transforms.Compose([ transforms.Resize((112, 112)), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) # 加载数据集并进行训练 train_dataset = CustomDataset('./cat_vs_dog/train', transform) train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device) for epoch in range(num_epochs): model.train() running_loss = 0.0 correct = 0 total = 0 for images, labels in train_loader: images = images.to(device) labels = labels.to(device) # 前向传播 outputs = model(images) loss = criterion(outputs, labels) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}, Accuracy: {(100 * correct / total):.2f}%") print('Training finished.') # 保存模型 torch.save(model.state_dict(), 'vggnet.pth')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号