matlab练习程序(DBSCAN)
DBSCAN全称Density-Based Spatial Clustering of Applications with Noise,是一种密度聚类算法。
和Kmeans相比,不需要事先知道数据的类数。
以编程的角度来考虑,具体算法流程如下:
1.首先选择一个待处理数据。
2.寻找和待处理数据距离在设置半径内的数据。
3.将找到的半径内的数据放到一个队列中。
4.拿队列头数据作为当前待处理数据并不断执行第2步。
5.直到遍历完队列中所有数据,将这些数据记为一类。
6.选择没有处理到的数据作为一个待处理数据执行第2步。
7.直到遍历完所有数据,算法结束。
大概就是下图所示的样子:

我这里没有单独输出离群点,不过稍微改进增加离群点个数判断阈值应该就可以,比较容易修改。
代码如下:
clear all; close all; clc; theta=0:0.01:2*pi; p1=[3*cos(theta) + rand(1,length(theta))/2;3*sin(theta)+ rand(1,length(theta))/2]; %生成测试数据 p2=[2*cos(theta) + rand(1,length(theta))/2;2*sin(theta)+ rand(1,length(theta))/2]; p3=[cos(theta) + rand(1,length(theta))/2;sin(theta)+ rand(1,length(theta))/2]; p=[p1 p2 p3]'; randIndex = randperm(length(p))'; %打乱数据顺序 p=p(randIndex,:); plot(p(:,1),p(:,2),'.') flag = zeros(length(p),1); %聚类标记 clsnum = 0; %类的个数 disnear = 0.3; %聚类半径 for i=1:length(p) nxtp = p(i,:); %初始聚类半径内的邻域点队列 if flag(i)==0 clsnum = clsnum+1; pcstart = 1; %设置队列起始指针 preflag = flag; %聚类标记更新 while pcstart<=length(nxtp) %判断是否完成队列遍历 curp = nxtp(pcstart,:); %得到当前要处理的点 pcstart = pcstart+1; %队列指针更新 diffp = p-curp; %这里直接和所有数据比较了,数据量大的时候可以考虑kdtree dis = sqrt(diffp(:,1).*diffp(:,1)+diffp(:,2).*diffp(:,2)); %判断当前点与所有点之间的距离 ind = dis<disnear; %得到距离小于阈值的索引 flag(ind) = clsnum; %设置当前聚类标记 diff_flag = preflag-flag; diff_ind = (preflag-flag)<0; %判断本次循环相比上次循环增加的点 tmp = zeros(length(p),1); tmp(diff_ind) = clsnum; flag = flag + tmp; %增加的点将其标记为一类 preflag = flag; %聚类标记更新 nxtp = [nxtp;p(diff_ind,:)]; %增加聚类半径内的邻域点队列 end end end
%聚类可能不止三组,我偷懒不想判断并plot了 figure; plot(p(flag==1,1),p(flag==1,2),'r.') hold on; plot(p(flag==2,1),p(flag==2,2),'g.') plot(p(flag==3,1),p(flag==3,2),'b.')
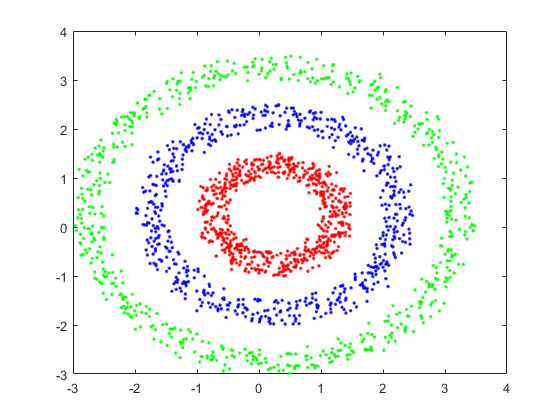
结果如下:
原始数据:
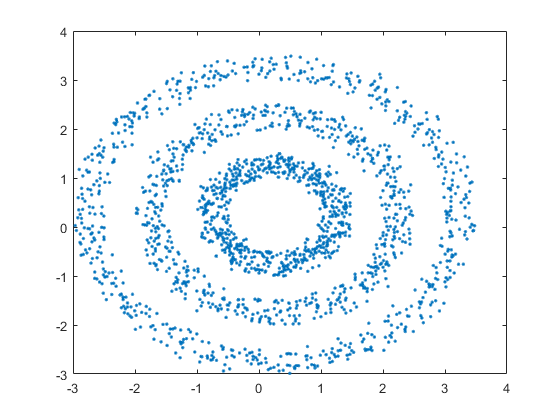
聚类结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号