

mysql 链接
group by
group by ,分组,顾名思义,把数据按什么来分组,每一组都有什么特点。
1、我们先从最简单的开始:
select count(*) from tb1 group by tb1.sex;
查询所有数据的条数,按性别来分组。这样查询到的结果集只有一列count(*)。
2、然后我们来分析一下,这个分组,我们能在select 和 from 之间放一些什么呢?
当数据分组之后,数据的大部分字段都将失去它存在的意义,大家想想,多条数据的同一列,只显示一个值,那到底显示谁的,这个值有用吗?
通过思考,不难发现,只有by的那些列可以放进去,然后就是sql的函数操作了,比如count(),sum()……(包含在by后面作为分组的依据,包含在聚合函数中作为结果)
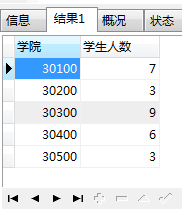
例:查询每个学院的学生有多少人:(学院的值是学院的id)
SELECT a.COLLEGE AS 学院,COUNT(*) AS 学生人数 FROM base_alumni a GROUP BY a.COLLEGE;
3、where,having,和group by联合使用
在最初学习group by的时候,我就陷入了一个误区,那就是group by不能和where一起使用,只能用having……
看书不认真啊,其实它们都是可以一起使用的,只不过是where只能在group by 的前面,having只能在group by 的后面。
where,过滤条件的关键字,但是它只能对group by之前的数据进行过滤筛选;
having,也是过滤条件的关键字作用和where是一样的,但是它过滤的是分组后的数据,就是对分组后得到的结果集进行过滤筛选。
出现having其实我觉得就是为了解决一条语句出现两个where的问题,把它们区分开来
例:
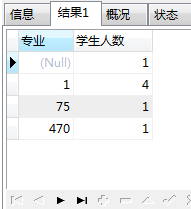
查询 30100学院的每个专业的学生有多少人。
SELECT a.MAJOR AS 专业, COUNT(*) AS 学生人数 FROM base_alumni a WHERE a.COLLEGE = 30100 GROUP BY a.MAJOR;
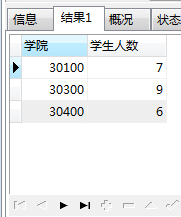
查询每个学院的学生有多少人,并且只要学生人数大于3的。
SELECT a.COLLEGE AS 学院,COUNT(*) AS 学生人数 FROM base_alumni a GROUP BY a.COLLEGE HAVING COUNT(*)>3;
滤清执行顺序:①先对*进行筛选,②对筛选的结果进行分组,③对分组的结果进行筛选
二、深入学习 连接
连接分4种,内连接,全连接,左外连接,右外连接
https://www.cnblogs.com/afirefly/archive/2010/10/08/1845906.html
1、连接出现的地方
①from和where之间,做表和表的连接
②where和having之间,having是对group by的结果集进行筛选,就是把group by的结果集作为一张表,然后可以再和别的表做连接,再进一步筛选
2、连接类型解读
把表看成是一个集合,连接看成是映射,那么它们的结果
内连接:一一映射;全连接:笛卡尔乘积;左外连接:一一映射+左表对应右表的null;右外连接:一一映射+右表对应左表的null。
关键字:
内连接:inner join;全连接:cross join;左外连接:left join;右外连接:right join 。
语法:
表a left join 表b on a.列1 = b.列2
3、连接的使用
例:查询每个学院的学生有多少人:(学院的值是学院的id),在没有连接的时候,学院人数为0的是显示不出来的,因为当前表中就没有这个学院的信息
那么我们在这里做一下左连接(左外连接):
SELECT c.ID, a.COLLEGE, COUNT(a.COLLEGE) FROM (SELECT ID FROM dic_college) c LEFT JOIN ( SELECT COLLEGE FROM base_alumni ) a ON c.ID = a.COLLEGE GROUP BY c.ID
我这里是一个完整的语句了。我在写出这条语句之前遇到了许多的磕磕碰碰。
解读它:
我们先把学院表和校友信息表(学生表)做左连接
因为我们要的是学院,所以学院作为主表,放left join的前面 c LEFT JOIN a ON ...
然后我们发现有很多字段,于是我们去掉多余的字段,这样既方便我们观察,也提高了sql的执行效率
①把学院表变成只有一个字段(SELECT ID FROM dic_college) c
②把学生表变成只有一个字段( SELECT COLLEGE FROM base_alumni ) a
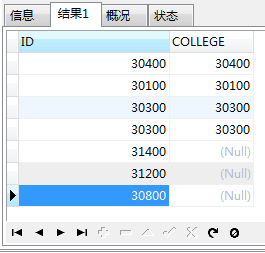
这时,查询结果是这样的
SELECT * FROM (SELECT ID FROM dic_college) c LEFT JOIN ( SELECT COLLEGE FROM base_alumni ) a ON c.ID = a.COLLEGE
这时候,对这个结果集进行分组:GROUP BY c.ID,并且查询字段要做更改
在上边那个结果集中,c.ID和a.COLLEGE是一一对应的,此时,count(*)的数据是总行数,因为我们的主表是学院表,所以这个数据和count(c.ID)的数据是一样的。
但是a.COLLEGE为空的行的数据中值都是1,这不是我们想要的,所以我们把count(*)改成count(a.COLLEGE),这样数据就出来了。
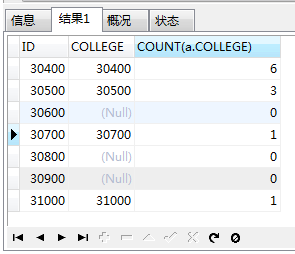
这才是查询所有学院中每个学院的学生人数的正确答案!当然,上边的截图只是数据的前几行,后面还有数据的
左连接和右连接……
SELECT * FROM a LEFT JOIN b ON b.ID = a.FK_ID;
SELECT * FROM b RIGHT JOIN a ON b.ID = a.FK_ID;
这两个语句的结果相同,它两并没有发现别的区别。
全连接就是交叉连接,和不使用连接……
SELECT * FROM c,a WHERE c.ID = a.FK_ID;
SELECT * FROM c CROSS JOIN a ON c.ID = a.FK_ID;
这两个语句也没有区别。

