postgresql性能优化3:分区表
一、分区表产生的背景
随着使用时间的增加,数据库中的数据量也不断增加,因此数据库查询越来越慢。
加速数据库的方法很多,如添加特定的索引,将日志目录换到单独的磁盘分区,调整数据库引擎的参数等。这些方法都能将数据库的查询性能提高到一定程度。
对于许多应用数据库来说,许多数据是历史数据并且随着时间的推移它们的重要性逐渐降低。如果能找到一个办法将这些可能不太重要的数据隐藏,数据库查询速度将会大幅提高。可以通过DELETE来达到此目的,但同时这些数据就永远不可用了。
因此,需要一个高效的把历史数据从当前查询中隐藏起来并且不造成数据丢失的方法。本文即将介绍的数据库表分区即能达到此效果。
二、分区表结构图
数据库表分区把一个大的物理表分成若干个小的物理表,并使得这些小物理表在逻辑上可以被当成一张表来使用。
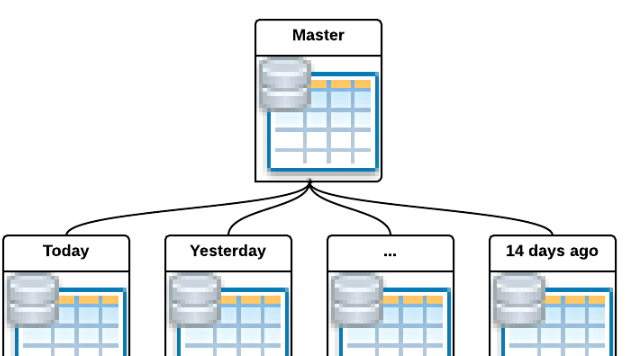
主表/父表/Master Table该表是创建子表的模板。它是一个正常的普通表,但正常情况下它并不储存任何数据。子表/分区表/Child Table/Partition Table这些表继承并属于一个主表。子表中存储所有的数据。主表与分区表属于一对多的关系,也就是说,一个主表包含多个分区表,而一个分区表只从属于一个主表
三、PostgreSQL各个版本 的分区表功能
分区表在不同的文档描述中使用了多个名词:原生分区 = 内置分区表 = 分区表。
PostgreSQL 9.x 之前的版本提供了一种“手动”方式使用分区表的方式,需要使用继承 + 触发器的来实现分区表,使用继承关键字INHERITS,步骤较为繁琐,需要定义附表、子表、子表的约束、创建子表索引,创建分区删除、修改,触发器等。
PostgreSQL 10.x 开始提供了内置分区表(内置是相对于 10.x 之前的手动方式)。内置分区简化了操作,将部分操作内置,最终简单三步就能够创建分区表。但是只支持范围分区(RANGE)和列表分区(LIST),
PostgreSQL 11.x 版本添加了对 HASH 分区。
本文将使用 PostgreSQL 10.x 版本及后续版本中的的内置分区表的使用方式,通过三步来创建分区表
1,创建父表------------指定分区键、分区策略(RANGE | LIST | HASH(11.x 才提供HASH策略))
2,创建分区表----------指定父表,分区键范围(分区键范围重叠之后会直接报错)
3,在分区上创建索引-----通常分区键上的索引是必须的
四、几种分区策略
PostgreSQL内置支持以下3种方式的分区:
1、范围(Range )分区:表被划分为由键列或列集定义的“范围”,分配给不同分区的值的范围之间没有重叠。例如:可以按日期范围或特定业务对象的标识符范围,来进行分区。
2、列表(List)分区:通过显式列出哪些键值出现在每个分区中来对表进行分区。
3、哈希(Hash)分区:(自PG11才提供HASH策略)通过为每个分区指定模数和余数来对表进行分区。每个分区将保存行,分区键的哈希值除以指定的模数将产生指定的余数。
五、建立分区实例
1、创建父表
CREATE TABLE measurement ( city_id int not null, logdate date not null, peaktemp int, unitsales int ) PARTITION BY RANGE (logdate);
2、创建分区表
CREATE TABLE measurement_200711 PARTITION OF measurement FOR VALUES FROM ('2007-11-01') TO ('2007-12-01'); CREATE TABLE measurement_200712 PARTITION OF measurement FOR VALUES FROM ('2007-12-01') TO ('2008-01-01') TABLESPACE fasttablespace; CREATE TABLE measurement_200801 PARTITION OF measurement FOR VALUES FROM ('2008-01-01') TO ('2008-02-01')
3、创建索引
CREATE INDEX index_measurement ON measurement USING btree(logdate);
4、 postgresql.conf配置
(1) enable_partition_pruning=on (分区修剪)启用,否则,查询将不会被优化。
如果不进行分区修剪,上述查询将扫描父表 measurement 的每个分区。启用分区修剪后,计划器将检查每个分区的定义并证明不需要扫描该分区,因为该分区不能包含满足查询的WHERE子句的任何行。当计划器可以证明这一点时,它将从查询计划中排除(修剪)该分区。
(2)constraint_exclusion=partition ,配置项没有被disable 。这一点非常重要,如果该参数项被disable,则基于分区表的查询性能无法得到优化,甚至比不使用分区表直接使用索引性能更低。
5、维护分区
Analyze measurement
六、要建立默认分区
默认分区,用于处理没有分区表的异常插入情况,用于存储无法匹配其他任何分区表的数据。显然,只有 RANGE 分区表和 LIST 分区表需要默认分区。
创建默认分区时,使用 DEFAULT 子句替代 FOR VALUES 子句。
CREATE TABLE measurement_default PARTITION OF measurement DEFAULT;
七、分区表不能自动建,怎么办?
方法1:利用java的定时器,定时某段时间创建分区表。
日分区表创建:tablepartitionsquartz_day
CREATE OR REPLACE FUNCTION "public"."tablepartitionsquartz_day"("p_tablename" varchar, "p_time" timestamp) RETURNS "pg_catalog"."void" AS $BODY$ declare target_day date; next_day date; table_names text; start_date text; end_date text; exists_flag boolean; begin -- 获取插入数据的日期(每天1号) target_day := date_trunc('day', p_time)::date; next_day := target_day + '1 day'::interval; -- 生成分区表名(格式:mpdata_YYYYMMDD) table_names := p_tablename|| '_' || to_char(target_day, 'YYYYMMDD'); start_date := to_char(target_day, 'YYYY-MM-DD'); end_date := to_char(next_day, 'YYYY-MM-DD'); -- 检查分区表是否已存在 SELECT EXISTS ( SELECT 1 FROM information_schema.tables WHERE table_name = table_names ) INTO exists_flag; -- 如果分区表不存在,则创建它 IF NOT exists_flag THEN -- 创建分区表 EXECUTE format(' CREATE TABLE %I PARTITION OF %I FOR VALUES FROM (%L) TO (%L); ', table_names,p_tablename, start_date, end_date); RAISE NOTICE '自动创建分区表: %', table_names; END IF; end; $BODY$ LANGUAGE plpgsql VOLATILE COST 100;
月分区表创建:tablepartitionsquartz_month
CREATE OR REPLACE FUNCTION "public"."tablepartitionsquartz_month"("p_tablename" varchar, "p_time" timestamp) RETURNS "pg_catalog"."void" AS $BODY$ declare target_month date; next_month date; table_names text; start_date text; end_date text; exists_flag boolean; begin -- 获取插入数据的月份(每月1号) target_month := date_trunc('month', p_time)::date; next_month := target_month + '1 month'::interval; -- 生成分区表名(格式:mpdata_YYYYMM) table_names := p_tablename|| '_' || to_char(target_month, 'YYYYMM'); start_date := to_char(target_month, 'YYYY-MM-DD'); end_date := to_char(next_month, 'YYYY-MM-DD'); -- 检查分区表是否已存在 SELECT EXISTS ( SELECT 1 FROM information_schema.tables WHERE table_name = table_names ) INTO exists_flag; -- 如果分区表不存在,则创建它 IF NOT exists_flag THEN -- 创建分区表 EXECUTE format(' CREATE TABLE %I PARTITION OF %I FOR VALUES FROM (%L) TO (%L); ', table_names,p_tablename, start_date, end_date); RAISE NOTICE '自动创建分区表: %', table_names; END IF; end; $BODY$ LANGUAGE plpgsql VOLATILE COST 100;
年分区表创建:tablepartitionsquartz_year
CREATE OR REPLACE FUNCTION "public"."tablepartitionsquartz_year"("p_tablename" varchar, "p_time" timestamp) RETURNS "pg_catalog"."void" AS $BODY$ declare target_year date; next_year date; table_names text; start_date text; end_date text; exists_flag boolean; begin -- 获取插入数据的年份(每年1号) target_year := date_trunc('year', p_time)::date; next_year := target_year + '1 year'::interval; -- 生成分区表名(格式:mpdata_YYYY) table_names := p_tablename|| '_' || to_char(target_year, 'YYYY'); start_date := to_char(target_year, 'YYYY-MM-DD'); end_date := to_char(next_year, 'YYYY-MM-DD'); -- 检查分区表是否已存在 SELECT EXISTS ( SELECT 1 FROM information_schema.tables WHERE table_name = table_names ) INTO exists_flag; -- 如果分区表不存在,则创建它 IF NOT exists_flag THEN -- 创建分区表 EXECUTE format(' CREATE TABLE %I PARTITION OF %I FOR VALUES FROM (%L) TO (%L); ', table_names,p_tablename, start_date, end_date); RAISE NOTICE '自动创建分区表: %', table_names; END IF; end; $BODY$ LANGUAGE plpgsql VOLATILE COST 100;
方法2:编写存储过程脚本,一次性生成未来3年,未来10年的多个分区表,下面给出存储过程的脚本。
tablepartitionsadd_day,按天生成分区表,一天一个分区表
CREATE OR REPLACE FUNCTION public.tablepartitionsadd_day( p_tablename text, p_schema text, p_date_start text, p_step integer) RETURNS void LANGUAGE 'plpgsql' COST 100 VOLATILE PARALLEL UNSAFE AS $BODY$ declare v_cnt int; v_schema_name varchar(500); v_table_name varchar(500); v_curr_limit varchar(50); v_curr_limit1 varchar(50); v_steps int; v_exec_sql text; v_partition_name text; v_date_start text; --select tablePartitionsAdd_day('wry_gasfachourzsdata','public','2018-12-01',365),从2018-12-01的下1天开始 begin v_schema_name = p_schema; v_table_name = p_tablename; v_date_start = p_date_start; v_steps = p_step; v_exec_sql = ' '; for i in 0 .. v_steps loop v_curr_limit = to_char(to_date(v_date_start,'yyyy-mm-dd') + i,'yyyy-mm-dd'); v_curr_limit1 = to_char(to_date(v_curr_limit,'yyyy-mm-dd') + 1,'yyyy-mm-dd'); v_partition_name = to_char(to_date(v_date_start,'yyyy-mm-dd') + i, 'yyyymmdd'); SELECT count(1) into v_cnt from pg_tables where schemaname=v_schema_name and tablename = v_table_name||'_'||v_partition_name; if v_cnt = 0 then v_exec_sql = v_exec_sql||' create table '||v_schema_name||'.'||v_table_name||'_'||v_partition_name||' partition of '||v_table_name||' for values FROM ('''||v_curr_limit||' 00:00:00'||''') TO ('''||v_curr_limit1||' 00:00:00'||''');'; end if; end loop; execute v_exec_sql; end; $BODY$;
tablepartitionsadd_month,按月生成分区表,一月一个分区表
CREATE OR REPLACE FUNCTION public.tablepartitionsadd_month( p_tablename text, p_schema text, p_date_start text, p_step integer) RETURNS void LANGUAGE 'plpgsql' COST 100 VOLATILE PARALLEL UNSAFE AS $BODY$ declare v_cnt int; v_schema_name varchar(500); v_table_name varchar(500); v_curr_limit varchar(50); v_curr_limit1 varchar(50); v_steps int; v_exec_sql text; v_partition_name text; v_date_start text; --select tablePartitionsAdd_month('wry_gasfachourzsdata','public','2018-12-01',36),从2018-12-01的下个月开始 begin v_schema_name = p_schema; v_table_name = p_tablename; v_date_start = p_date_start; v_steps = p_step; v_exec_sql = ' '; v_curr_limit=v_date_start; for i in 1 .. v_steps loop v_curr_limit = to_char(to_date(v_curr_limit,'yyyy-mm-dd') +interval '1 month','yyyy-mm-dd'); v_curr_limit1 = to_char(to_date(v_curr_limit,'yyyy-mm-dd') +interval '1 month','yyyy-mm-dd'); v_partition_name = to_char(to_date(v_curr_limit,'yyyy-mm-dd'), 'yyyymm'); SELECT count(1) into v_cnt from pg_tables where schemaname=v_schema_name and tablename = v_table_name||'_'||v_partition_name; if v_cnt = 0 then v_exec_sql = v_exec_sql||' create table '||v_schema_name||'.'||v_table_name||'_'||v_partition_name||' partition of '||v_table_name||' for values FROM ('''||v_curr_limit||' 00:00:00'||''') TO ('''||v_curr_limit1||' 00:00:00'||''');'; end if; end loop; execute v_exec_sql; end; $BODY$;
tablepartitionsadd_year,按年生成分区表,一年一个分区表
CREATE OR REPLACE FUNCTION public.tablepartitionsadd_year( p_tablename text, p_schema text, p_date_start text, p_step integer) RETURNS void LANGUAGE 'plpgsql' COST 100 VOLATILE PARALLEL UNSAFE AS $BODY$ declare v_cnt int; v_schema_name varchar(500); v_table_name varchar(500); v_curr_limit varchar(50); v_curr_limit1 varchar(50); v_steps int; v_exec_sql text; v_partition_name text; v_date_start text; --select tablePartitionsAdd_month('wry_gasfachourzsdata','public','2018-01-01',36),从2018-01-01的下个年开始 begin v_schema_name = p_schema; v_table_name = p_tablename; v_date_start = p_date_start; v_steps = p_step; v_exec_sql = ' '; v_curr_limit=v_date_start; for i in 1 .. v_steps loop v_curr_limit = to_char(to_date(v_curr_limit,'yyyy-mm-dd') +interval '1 year','yyyy-mm-dd'); v_curr_limit1 = to_char(to_date(v_curr_limit,'yyyy-mm-dd') +interval '1 year','yyyy-mm-dd'); v_partition_name = to_char(to_date(v_curr_limit,'yyyy-mm-dd'), 'yyyy'); SELECT count(1) into v_cnt from pg_tables where schemaname=v_schema_name and tablename = v_table_name||'_'||v_partition_name; if v_cnt = 0 then v_exec_sql = v_exec_sql||' create table '||v_schema_name||'.'||v_table_name||'_'||v_partition_name||' partition of '||v_table_name||' for values FROM ('''||v_curr_limit||' 00:00:00'||''') TO ('''||v_curr_limit1||' 00:00:00'||''');'; end if; end loop; execute v_exec_sql; end; $BODY$;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号