python爬虫
Python爬虫
爬虫步骤:
爬取步骤
step1. download Web html code :requests.get/post
step2. parse the html code from step1. lxml.etree.HTML()
step3. save the parsed data witch from step2
保存到数据库:
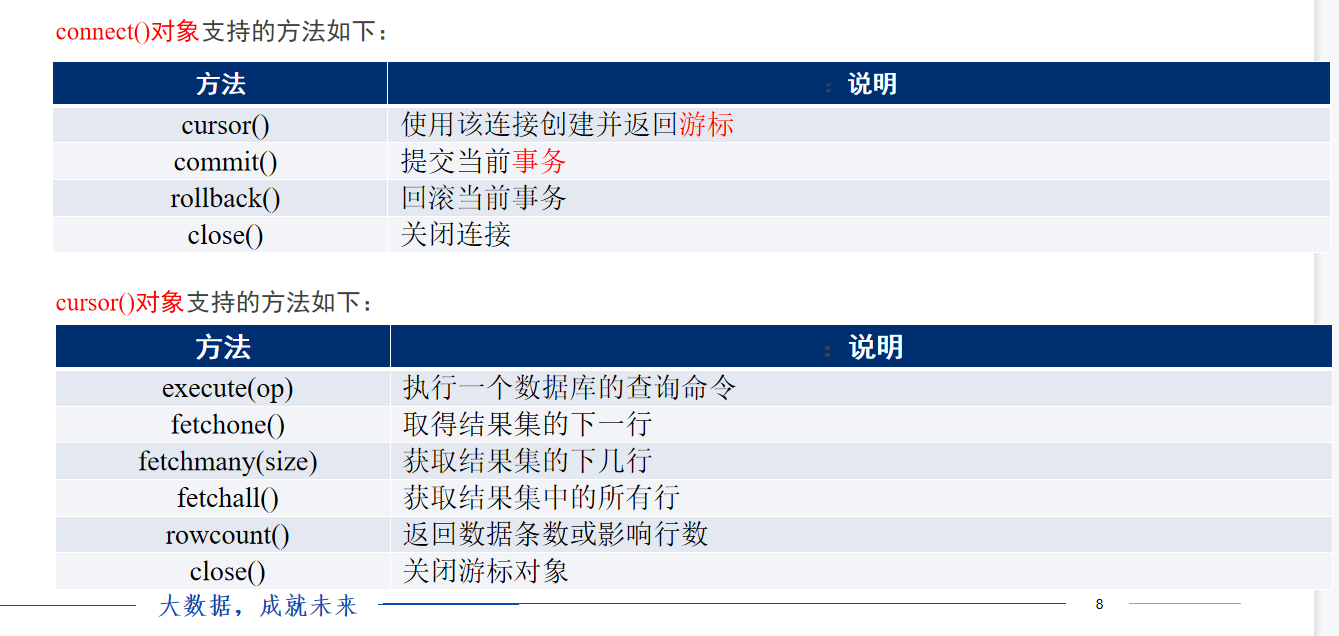
pymysql connect to mysql database steps:
1.to get connect object
2.get cursor object from connect
3.execute query string from cursor
4.commit transaction and close resource(connect,cursor)/rollback
环境
cmd 窗口
python --version
pip --version
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install pymysql
pip list | find "requests"python -m pip install pip -U (更新)
vscode
安装python , kite , jupyter
第一个程序
from os import write
from typing import Text
import requests
#请求百度的结果 r 代表响应
try:
r = requests.get("http://www.baidu.com")
# r.request.headers 请求的头部
r.encoding = 'utf-8'
r.raise_for_ststus()
r.history
r.content #这是二进制内容
except:
print("error")
print(r.text)
# 存入txt
with open("1.txt","w",encoding="utf-8") as f:
f.write(r.text)
#运行单元|运行本单元上方|调试单元
#with可以自动关闭
汉字字符集编码查询;中文字符集编码:GB2312、BIG5、GBK、GB18030、Unicode (qqxiuzi.cn)
html状态码(需要记住)
导包的路径
安装路径下的lib路径下的site里
*参数
一个 * : 元组方式
两个 ** : 字典方式
XHR
xml http requests
登录校园网
payload = {"username":"11",
"password":"xN94pkdfNwM=",
"authCode":"",
"It":"abcd1234",
"execution":"e3s2",
"_eventId":"submit",
"isQrSubmit":"false",
"qrValue":"",
"isMobileLogin":"false"}
url="http://a.cqie.edu.cn/cas/login?service=http://i.cqie.edu.cn/portal_main/toPortalPage"
r = requests.post(url,data=payload,timeout=3)
r.status_code
实验2
1
import requests
from lxml import etree
def down_html(url):#获取网页内容
try:
r=requests.get(url)#发送请求
r.raise_for_status() #非正常返回爬出异常
r.encoding=r.apparent_encoding#设置返回内容的字符集编码
return r.text
except Exception:
print("download page error")
#网页解析
def parse_html(html):
data=etree.HTML(html)
title=data.xpath('//div[@id="u1"]/a/text()')
url=data.xpath('//div[@id="u1"]/a/@href')
result=dict()
for i in range(0,len(title)):
result[title[i]]=url[i]
return result
if __name__=='__main__':
url="http://www.baidu.com"
for k,v in parse_html(down_html(url)).items():
print(k+"-->"+v)
2
import requests
import csv
from lxml import etree
#下载网页
def download_page(url):
try:
r=requests.get(url)#发送请求
r.raise_for_status() #非正常返回爬出异常
r.encoding=r.apparent_encoding #设置返回内容的字符集编码
return r.text #返回网页的文本内容
except Exception:
pass
#解析网页
def parse_html(html):
data=etree.HTML(html)
books=[]
for book in data.xpath('//*[@id="tag-book"]/div/ul/li'):
name=book.xpath("div[2]/h4/a/text()")[0].strip() #书名
author=book.xpath('div[2]/div/span/text()')[0].strip()#作者
price=book.xpath("div[2]/span/span/text()")[0].strip()#价格
details_url=book.xpath("div[2]/h4/a/@href")[0].strip()#详情页地址
book=[name,author,price,details_url]
books.append(book)
return books
#保存数据
def save_data(file,data): #path文件保存路径,item数据列表
with open(file,"w+") as f:
writer = csv.writer(f)
for row in data:
writer.writerow(row)
print("data saved successfully")
if __name__ == '__main__':
url="https://www.ryjiaoyu.com/tag/details/7"
save_data("book4.csv",parse_html(download_page(url)))
静态网页爬取
robots协议
文件存储
txt文本存储

csv文件存储
import requests
from lxml import etree
#下载网页
def download_html(url):
try:
r= requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except Exception as e:
print(e)
#解析网页
def parse_html(html):
data=etree.HTML(html)
titles=data.xpath("//*[@id=\"colR\"]/div[2]/dl/dd/ul/li/a/text()")
dates=data.xpath("//*[@id=\"colR\"]/div[2]/dl/dd/ul/li/span/text()")
print(list(zip(titles,dates)))
return list(zip(titles,dates))
#保存数据
def save_data(data):
with open("news1.txt","w",encoding="utf-8") as f:
for item in data:
f.write(",".join(item)+"\n")
print("news title already saved successfully")
if __name__ == '__main__':
url="http://www.cqie.edu.cn/html/2/xydt/"
print(save_data(parse_html(download_html(url))))
PyMySQL
4个步骤
- 创建数据库链接对象 con
- 获取游标对象 cursor
- 执行SQL语句
- 提交事务,关闭链接
爬取内容存入到数据库
实验
import requests
from lxml import etree
import pymysql
import xlwt
#定义下载网页内容的函数
def download (url):
#伪装浏览
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36' }
#使用get方法获取网页内容
response=requests.get(url=url,headers=headers)
if response.status_code == 200:
#将获取的网页内容设置为“utf-8”编码格式
response.encoding='utf-8'
#返回下载网页内容
return response
# 解析网页
def analysisHtml(html_text):
# 使用XPath进行解析
html= etree.HTML(html_text)
# 获取
all_li =html.xpath("//div[@id='content']//li")
# print(all_li)
result=[]
for li in all_li[0:20]:
# /html/body/div[3]/div[1]/div/div[1]/ul/li[1]/div[2]/h2/a
bookname = li.xpath(".//div[2]/h2/a/text()")[0].strip()
href = li.xpath(".//h2/a/@href")[0].strip()
# print(bookname)
# /html/body/div[3]/div[1]/div/div[1]/ul/li[1]/div[2]/p[2]/span[2]
score=li.xpath(".//div[2]/p[2]/span[2]/text()")[0].strip()
# print(score)
bookstr=li.xpath(".//div[2]/p[1]/text()")[0].strip()
# /html/body/div[3]/div[1]/div/div[1]/ul/li[1]/div[2]/p[1]
author=bookstr.split("/")[0]
press=bookstr.split("/")[2] #出版社
pubdate=bookstr.split("/")[1] #出版日期
# /html/body/div[3]/div[2]/div/div[1]/div[3]/div[1]/span[1]/div/p[1]
# print(press)
# describ=li.xpath(".//p[3]/text()")[0].strip()
# result.append([bookname, score, author, press, pubdate, describ])
# print(li)
describ=parse_desPage(download(href).text)[0:50]
result.append([bookname, score, author, press, pubdate,describ[0:50]])
# print(result)
return result
# 获取描述的信息
def parse_desPage(html):
html = etree.HTML(html)
list = []
ps = html.xpath('//*[@id="link-report"]/span[1]/div/p')
for p in ps[0:-1]:
s=p.xpath('.//text()')
list=list+s
str = ','.join(list)
return str
#获取连接数据库配置信息
def get_config(host,user,password,db):
db_config = {
#注意:安装MySQL服务器的IP,请以实际IP为主
'host':host,
#注意:root为登录MySQL数据库的用户名
'user':user,
#注意:root为用root用户登录MySQL数据库的登录密码
'password':password,
#注意:python为访问的MySQL数据库
'db':db
}
return db_config
def getConn(contents):
#连接数据库
db_config=get_config('localhost','root','tcx119','python3')
conn = pymysql.Connect(**db_config)
cur = conn.cursor()
sql="insert into book(bookname,score,author,press,pubdate,describ) values(%s,%s,%s,%s,%s,%s)"
for item in contents:
cur.execute(sql,tuple(item))
# for content in contents:
# # href=content['href']
# # title=content['title']
# # 拼接sql语句
# sql = "INSERT INTO book VALUES("+"'"+content[0]+"'"+","+"'"+content[1]+"'"+")"
# # 执行sql语句
# cur.execute(sql)
conn.commit()
#关闭数据库
cur.close()
conn.close()
# def saveTxt(contents):
# #将解析后的数据保存到txt文件
# with open('content.txt', 'w', encoding = 'utf-8') as f:
# for content in contents:
# href=content[0]
# title=content[1]
# f.writelines(title +" :" + href + '\n')
if __name__ == "__main__":
html_text=download('https://book.douban.com/latest?icn=index-latestbook-all').text
# contents=analysisHtml(html_text)
getConn(analysisHtml(html_text))
# saveTxt(analysisHtml(html_text))
#saveExcel(contents)
BS4
code
# %%
from _typeshed import StrPath
import requests
from bs4 import BeautifulSoup
r=requests.get("http://www.baidu.com")
r.encoding = r.apparent_encoding
soup=BeautifulSoup(r.text,"lxml")
# %%
soup
# %%
soup.a
# %%
soup("a")
# %%
soup.find_all("a")
# %%
soup.a["href11"]
# %%
soup.a.get("href11")
# %%
soup("a")[-1].get("class")
# %%
soup("a")[-1].string
# %%
soup("a")[-1].get_text()
# %%
# 嵌套的文本要用 get_text 才能拿到
soup.div.get_text
# %%
soup.select("*")
# %%
soup.select("#cp")
# %%
soup.select("#cp,input")
# %%
# 有多个class 的 继续 . 就是
soup.select("#cp,input.bg.s_btn")
# %%
soup.select_one("input")
# %%
soup.a.attrs["href"]
# %%
爬取http://ccgp-shaanxi.gov.cn/上的公告
#http://ccgp-shaanxi.gov.cn/
from os import write
import requests
import csv
from bs4 import BeautifulSoup
r=requests.get("http://ccgp-shaanxi.gov.cn/")
r.encoding = r.apparent_encoding
soup=BeautifulSoup(r.text,"lxml")
soup
# %%
# soup.select("div.list-box")
# %%
rows=soup.select("#jdglprovincenotice > tr")
data = [[row.td.a.string,row.findAll("td")[-1].string] for row in rows]
# %%
print(data)
# %%
#保存data到csv
with open("bs1.csv","w") as file:
writer=csv.writer(file)
writer.writerows(data)
print("data hava been saved compeletly")
# %%
本文来自博客园,作者:后端小知识,转载请注明原文链接:https://www.cnblogs.com/tiancx/p/15371028.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号