

ClickHouse创建分布式表1
clickhouse集群主要有两个作用,一是数据副本,也就是将数据冗余到另外的机器上,用于保证高可用;二是分布表,就是将一个表的数据分散到多个节点上保存,然后再通过Distributed表引擎将数据拼接起来作为一个完整的表使用。
创建分布式表:
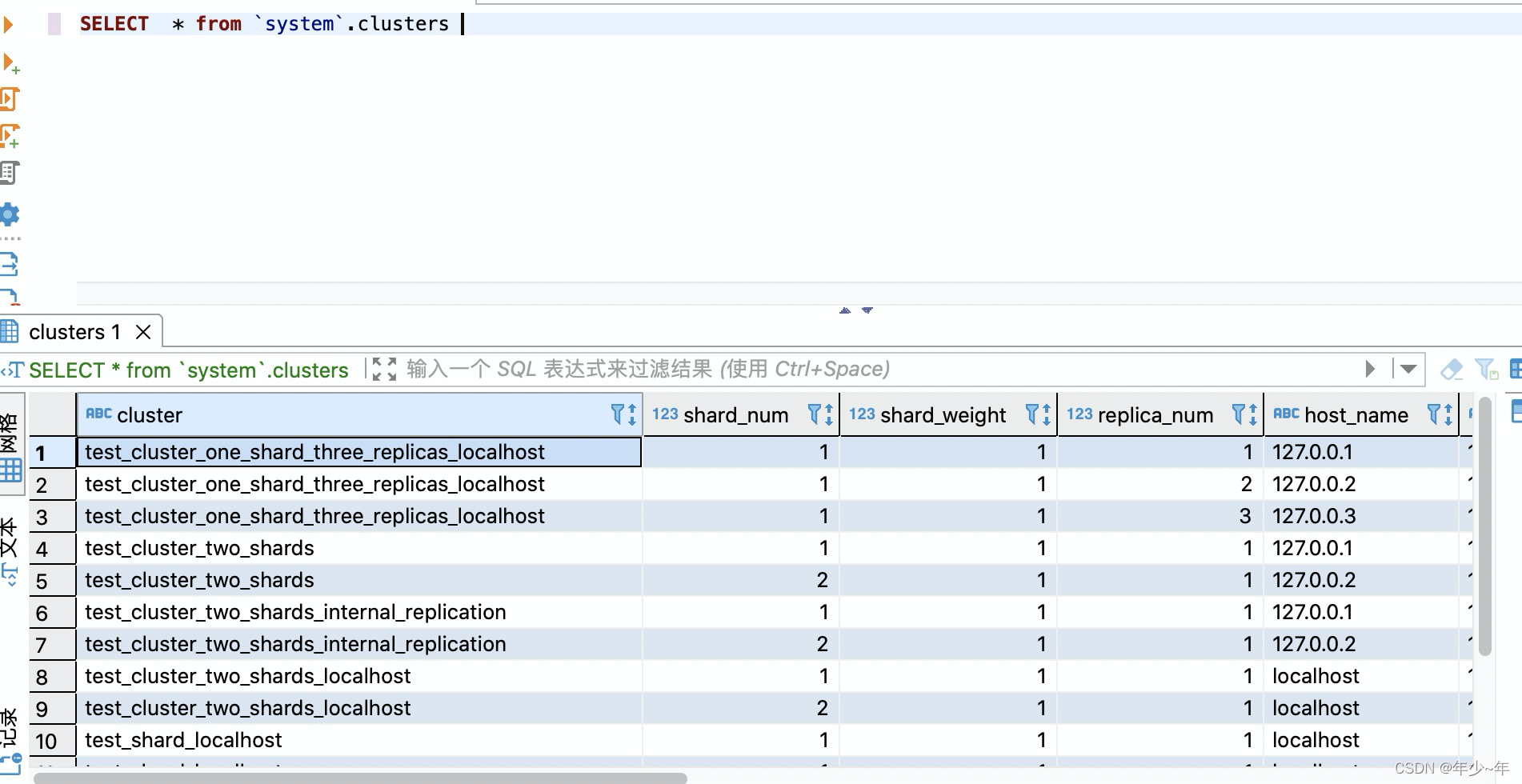
1.查看clickhouse 默认的集群配置
SELECT * from `system`.clusters
随便拿一个cluster 的值测试- 1
- 2
2. 创建本地表
CREATE TABLE default.test_list_local on cluster test_cluster_two_shards
(
`uuid` UUID,
`creat_datetime` DateTime COMMENT '创建时间'
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(creat_datetime)
ORDER BY (creat_datetime);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3. 使用Distributed表引擎创建分布式表
CREATE TABLE default.test_list on cluster test_cluster_two_shards
(
`uuid` UUID,
`creat_datetime` DateTime COMMENT '创建时间'
)
engine = Distributed(test_cluster_two_shards,default,test_list_local, rand());
Distributed(test_cluster_two_shards,default,test_list_local, rand()) 中部分解释
test_cluster_two_shards 表示服务器集群配置
default 远程数据库名
test_list_local 远程数据表名,对应的本地表名
rand() 分片key- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4. 查询 与 写入 都是使用 test_list 表
clickhouse 分布式引擎文档 https://clickhouse.com/docs/zh/engines/table-engines/special/distributed/
转自:https://blog.csdn.net/weixin_46124208/article/details/123705318
