

LockSupport工具
1. LockSupport简介
在之前介绍AQS的底层实现,已经在介绍java中的Lock时,比如ReentrantLock,ReentReadWriteLocks,已经在介绍线程间等待/通知机制使用的Condition时都会调用LockSupport.park()方法和LockSupport.unpark()方法。而这个在同步组件的实现中被频繁使用的LockSupport到底是何方神圣,现在就来看看。LockSupport位于java.util.concurrent.locks包下,有兴趣的可以直接去看源码,该类的方法并不是很多。LockSupprot是线程的阻塞原语,用来阻塞线程和唤醒线程。每个使用LockSupport的线程都会与一个许可关联,如果该许可可用,并且可在线程中使用,则调用park()将会立即返回,否则可能阻塞。如果许可尚不可用,则可以调用 unpark 使其可用。但是注意许可不可重入,也就是说只能调用一次park()方法,否则会一直阻塞。
2. LockSupport方法介绍
LockSupport中的方法不多,这里将这些方法做一个总结:
阻塞线程
- void park():阻塞当前线程,如果调用unpark方法或者当前线程被中断,从能从park()方法中返回
- void park(Object blocker):功能同方法1,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
- void parkNanos(long nanos):阻塞当前线程,最长不超过nanos纳秒,增加了超时返回的特性;
- void parkNanos(Object blocker, long nanos):功能同方法3,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
- void parkUntil(long deadline):阻塞当前线程,知道deadline;
- void parkUntil(Object blocker, long deadline):功能同方法5,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
唤醒线程
void unpark(Thread thread):唤醒处于阻塞状态的指定线程
实际上LockSupport阻塞和唤醒线程的功能是依赖于sun.misc.Unsafe,这是一个很底层的类,有兴趣的可以去查阅资料,比如park()方法的功能实现则是靠unsafe.park()方法。另外在阻塞线程这一系列方法中还有一个很有意思的现象就是,每个方法都会新增一个带有Object的阻塞对象的重载方法。那么增加了一个Object对象的入参会有什么不同的地方了?示例代码很简单就不说了,直接看dump线程的信息。
调用park()方法dump线程:
"main" #1 prio=5 os_prio=0 tid=0x02cdcc00 nid=0x2b48 waiting on condition [0x00d6f000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:304)
at learn.LockSupportDemo.main(LockSupportDemo.java:7)
调用park(Object blocker)方法dump线程
"main" #1 prio=5 os_prio=0 tid=0x0069cc00 nid=0x6c0 waiting on condition [0x00dcf000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x048c2d18> (a java.lang.String)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at learn.LockSupportDemo.main(LockSupportDemo.java:7)
通过分别调用这两个方法然后dump线程信息可以看出,带Object的park方法相较于无参的park方法会增加 parking to wait for <0x048c2d18> (a java.lang.String)的信息,这种信息就类似于记录“案发现场”,有助于工程人员能够迅速发现问题解决问题。有个有意思的事情是,我们都知道如果使用synchronzed阻塞了线程dump线程时都会有阻塞对象的描述,在java 5推出LockSupport时遗漏了这一点,在java 6时进行了补充。还有一点需要需要的是:synchronzed致使线程阻塞,线程会进入到BLOCKED状态,而调用LockSupprt方法阻塞线程会致使线程进入到WAITING状态。
3. 一个例子
用一个很简单的例子说说这些方法怎么用。
public class LockSupportDemo {
public static void main(String[] args) {
Thread thread = new Thread(() -> {
LockSupport.park();
System.out.println(Thread.currentThread().getName() + "被唤醒");
});
thread.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
LockSupport.unpark(thread);
}
}
thread线程调用LockSupport.park()致使thread阻塞,当mian线程睡眠3秒结束后通过LockSupport.unpark(thread)方法唤醒thread线程,thread线程被唤醒执行后续操作。另外,还有一点值得关注的是,LockSupport.unpark(thread)可以指定线程对象唤醒指定的线程。
转载链接:https://www.jianshu.com/p/9677a754cf60
LockSupport详解
前言
LockSupport是concurrent包中一个工具类,不支持构造,提供了一堆static方法,比如park(),unpark()等。
LockSupport中的主要成员及其加载时的初始化: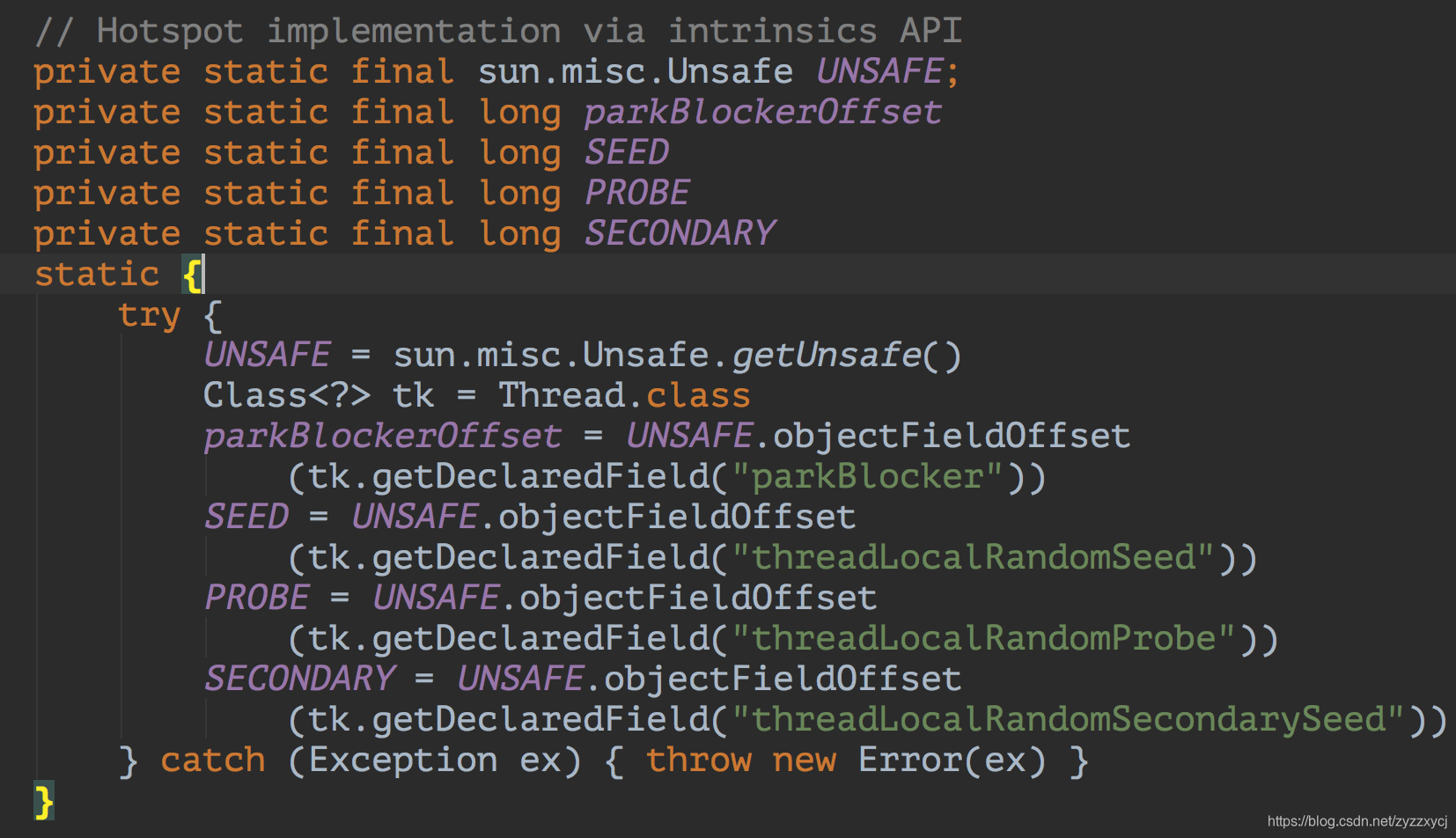
不难发现,他们在初始化的时候都是通过Unsafe去获得他们的内存地址,这里也可以理解为C中的指针。
Unsafe
Unsafe类可以参考我之前写的文章:深入理解sun.misc.Unsafe原理
parkBlockerOffset

提供给setBlocker和getBlocker使用。
由于Unsafe.putObject是无视java访问限制,直接修改目标内存地址的值。即使对象被volatile修饰,也是不需要写屏障的。关于屏障概念,可以参考 CyclicBarrier和CountDownLatch的用法与区别
这边的偏移量就算Thread这个类里面变量parkBlocker在内存中的偏移量:
JVM的实现可以自由选择如何实现Java对象的“布局“,也就是在内存里Java对象的各个部分放在哪里,包括对象的实例字段和一些元数据之类。
sun.misc.Unsafe里关于对象字段访问的方法把对象布局抽象出来,它提供了objectFieldOffset()方法用于获取某个字段相对
Java对象的“起始地址”的偏移量,也提供了getInt、getLong、getObject之类的方法可以使用前面获取的偏移量来访问某个Java
对象的某个字段。
为什么要用偏移量来获取对象?干吗不要直接写个get,set方法?
parkBlocker就是在线程处于阻塞的情况下才被赋值。线程都已经被阻塞了,如果不通过这种内存的方法,而是直接调用线程内的方法,线程是不会回应调用的。
SEED, PROBE, SECONDARY
 都是Thread类中的内存偏移地址,主要用于ThreadLocalRandom类进行随机数生成,它要比Random性能好很多,可以看jdk源码ThreadLocalRandom.java了解详情,这儿就不贴了。
都是Thread类中的内存偏移地址,主要用于ThreadLocalRandom类进行随机数生成,它要比Random性能好很多,可以看jdk源码ThreadLocalRandom.java了解详情,这儿就不贴了。
wait和notify/notifyAll
在看park()和unpark()之前,不妨来看下在没有LockSupport之前,是怎么实现让线程等待/唤醒的。
在没有LockSupport之前,线程的挂起和唤醒咱们都是通过Object的wait和notify/notifyAll方法实现。
写一段例子代码,线程A执行一段业务逻辑后调用wait阻塞住自己。主线程调用notify方法唤醒线程A,线程A然后打印自己执行的结果。
public static void main(String[] args) throws Exception {
final Object obj = new Object();
Thread A = new Thread(() -> {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
try {
obj.wait();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(sum);
});
A.start();
//睡眠一秒钟,保证线程A已经计算完成,阻塞在wait方法
Thread.sleep(1000);
obj.notify();
}执行这段代码,不难发现这个错误:
原因很简单,wait和notify/notifyAll方法只能在同步代码块里用(这个有的面试官也会考察)。所以将代码修改为如下就可正常运行了:
public static void main(String[] args) throws Exception {
final Object obj = new Object();
Thread A = new Thread(() -> {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
try {
synchronized (obj) {
obj.wait();
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(sum);
});
A.start();
//睡眠一秒钟,保证线程A已经计算完成,阻塞在wait方法
Thread.sleep(1000);
synchronized (obj) {
obj.notify();
}
}那如果咱们换成LockSupport呢?简单得很,看代码:
public static void main(String[] args) throws Exception {
Thread A = new Thread(() -> {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
LockSupport.park();
System.out.println(sum);
});
A.start();
//睡眠一秒钟,保证线程A已经计算完成,阻塞在wait方法
Thread.sleep(1000);
LockSupport.unpark(A);
}LockSupport灵活性
如果只是LockSupport在使用起来比Object的wait/notify简单,那还真没必要专门讲解下LockSupport。最主要的是灵活性。
上边的例子代码中,主线程调用了Thread.sleep(1000)方法来等待线程A计算完成进入wait状态。如果去掉Thread.sleep()调用:
public static void main(String[] args) throws Exception {
final Object obj = new Object();
Thread A = new Thread(() -> {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
try {
synchronized (obj) {
obj.wait();
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(sum);
});
A.start();
//睡眠一秒钟,保证线程A已经计算完成,阻塞在wait方法
// Thread.sleep(1000);
synchronized (obj) {
obj.notify();
}
}多次执行后,我们会发现:有的时候能够正常打印结果并退出程序,但有的时候线程无法打印结果阻塞住了。原因就在于主线程调用完notify后,线程A才进入wait方法,导致线程A一直阻塞住。由于线程A不是后台线程,所以整个程序无法退出。
那如果换做LockSupport呢?LockSupport就支持主线程先调用unpark后,线程A再调用park而不被阻塞吗?是的,没错。代码如下:
public static void main(String[] args) throws Exception {
Thread A = new Thread(() -> {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
LockSupport.park();
System.out.println(sum);
});
A.start();
//睡眠一秒钟,保证线程A已经计算完成,阻塞在wait方法
// Thread.sleep(1000);
LockSupport.unpark(A);
}不管你执行多少次,这段代码都能正常打印结果并退出。这就是LockSupport最大的灵活所在。
小结一下,LockSupport比Object的wait/notify有两大优势:
- LockSupport不需要在同步代码块里 。所以线程间也不需要维护一个共享的同步对象了,实现了线程间的解耦。
- unpark函数可以先于park调用,所以不需要担心线程间的执行的先后顺序。
LockSupport原理
看源码,park和unpark都是直接调用了Unsafe的方法:深入理解sun.misc.Unsafe原理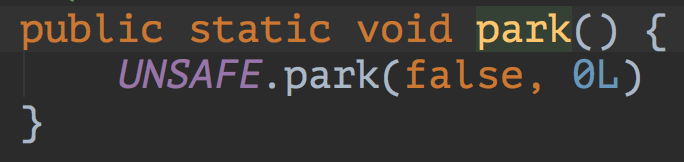

Unsafe源码也相对简单,看下就行了:
void
sun::misc::Unsafe::unpark (::java::lang::Thread *thread)
{
natThread *nt = (natThread *) thread->data;
nt->park_helper.unpark ();
}
void
sun::misc::Unsafe::park (jboolean isAbsolute, jlong time)
{
using namespace ::java::lang;
Thread *thread = Thread::currentThread();
natThread *nt = (natThread *) thread->data;
nt->park_helper.park (isAbsolute, time);
}LockSupport应用广泛
Future的get方法
LockSupport在Java的工具类用应用很广泛,咱们这里找几个例子感受感受。以Java里最常用的类ThreadPoolExecutor(线程池可参考ThreadPoolExecutor详解及线程池优化)。先看如下代码: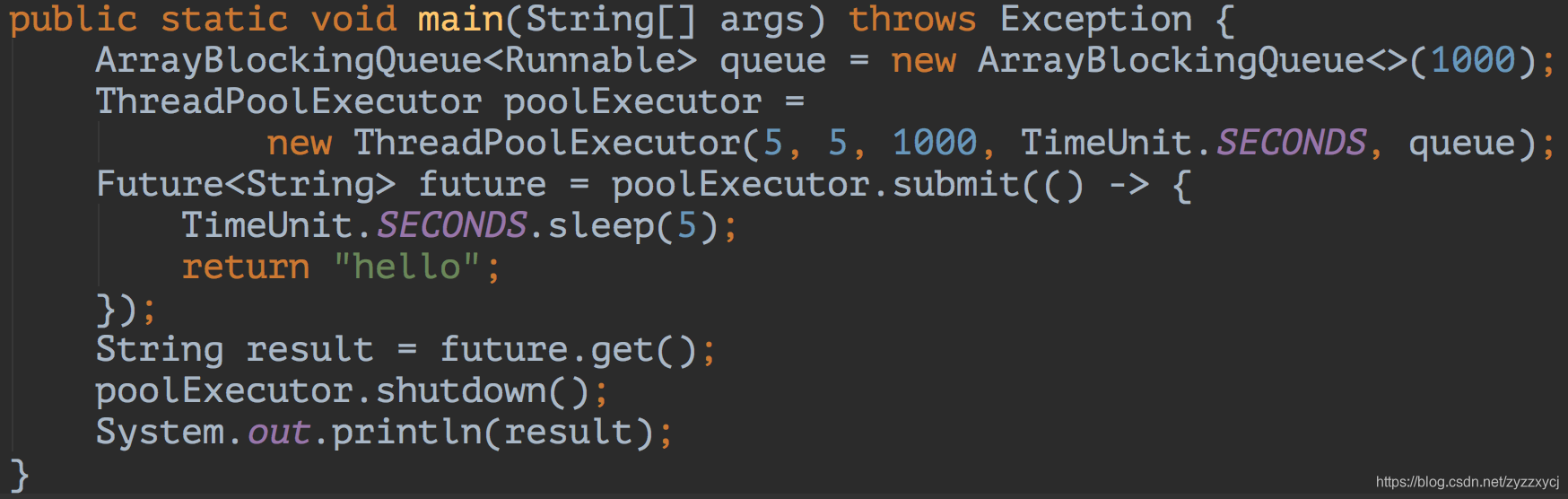
代码中我们向线程池中扔了一个任务,然后调用Future的get方法,同步阻塞等待线程池的执行结果。
这里就要问了:get方法是如何组塞住当前线程?线程池执行完任务后又是如何唤醒线程的呢?
咱们跟着源码一步步分析,先看线程池的submit方法的实现: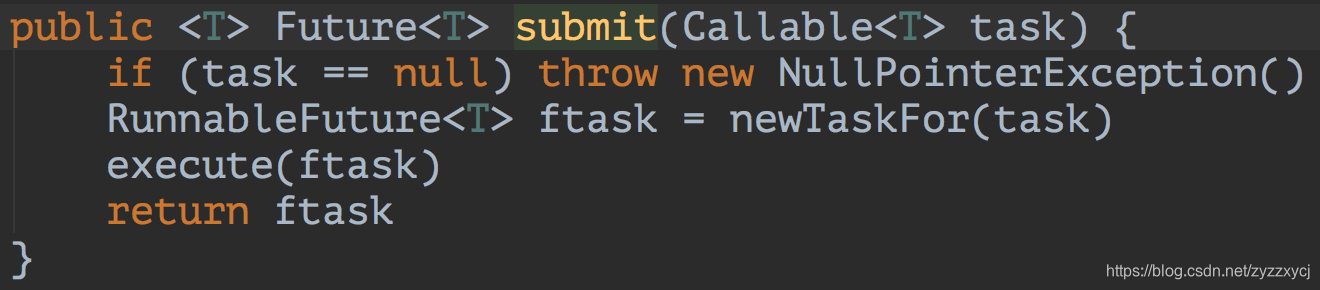
在submit方法里,线程池将我们提交的基于Callable实现的任务,封装为基于RunnableFuture实现的任务,然后将任务提交到线程池执行,并向当前线程返回RunnableFutrue。
进入newTaskFor方法,就一句话:return new FutureTask(callable);
所以,咱们主线程调用future的get方法就是FutureTask的get方法,线程池执行的任务对象也是FutureTask的实例。
接下来看看FutureTask的get方法的实现: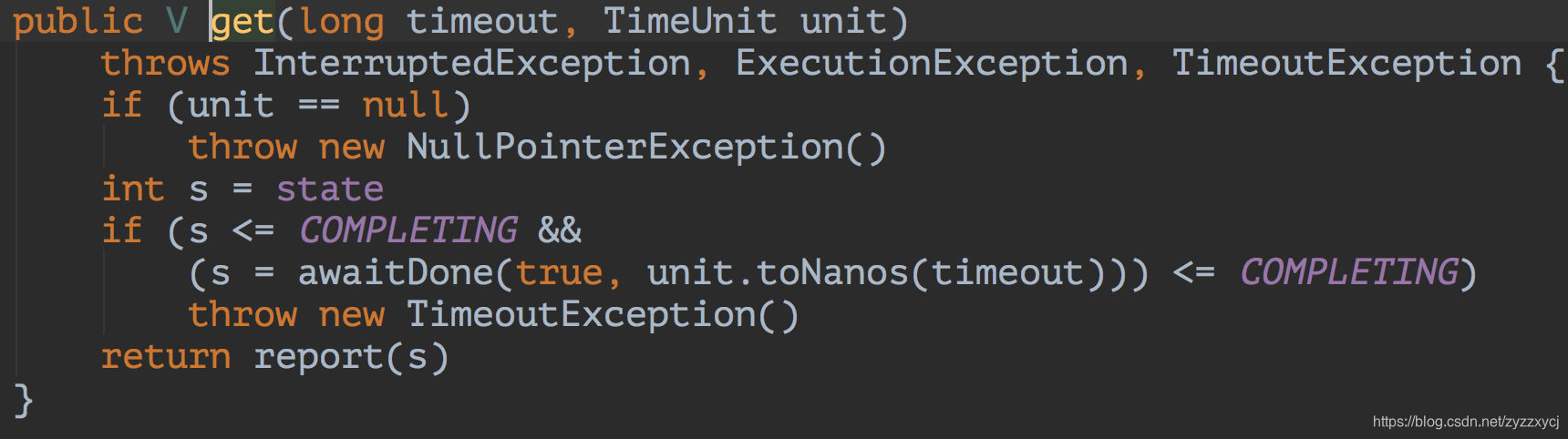
比较简单,就是判断下当前任务是否执行完毕,如果执行完毕直接返回任务结果,否则进入awaitDone方法阻塞等待。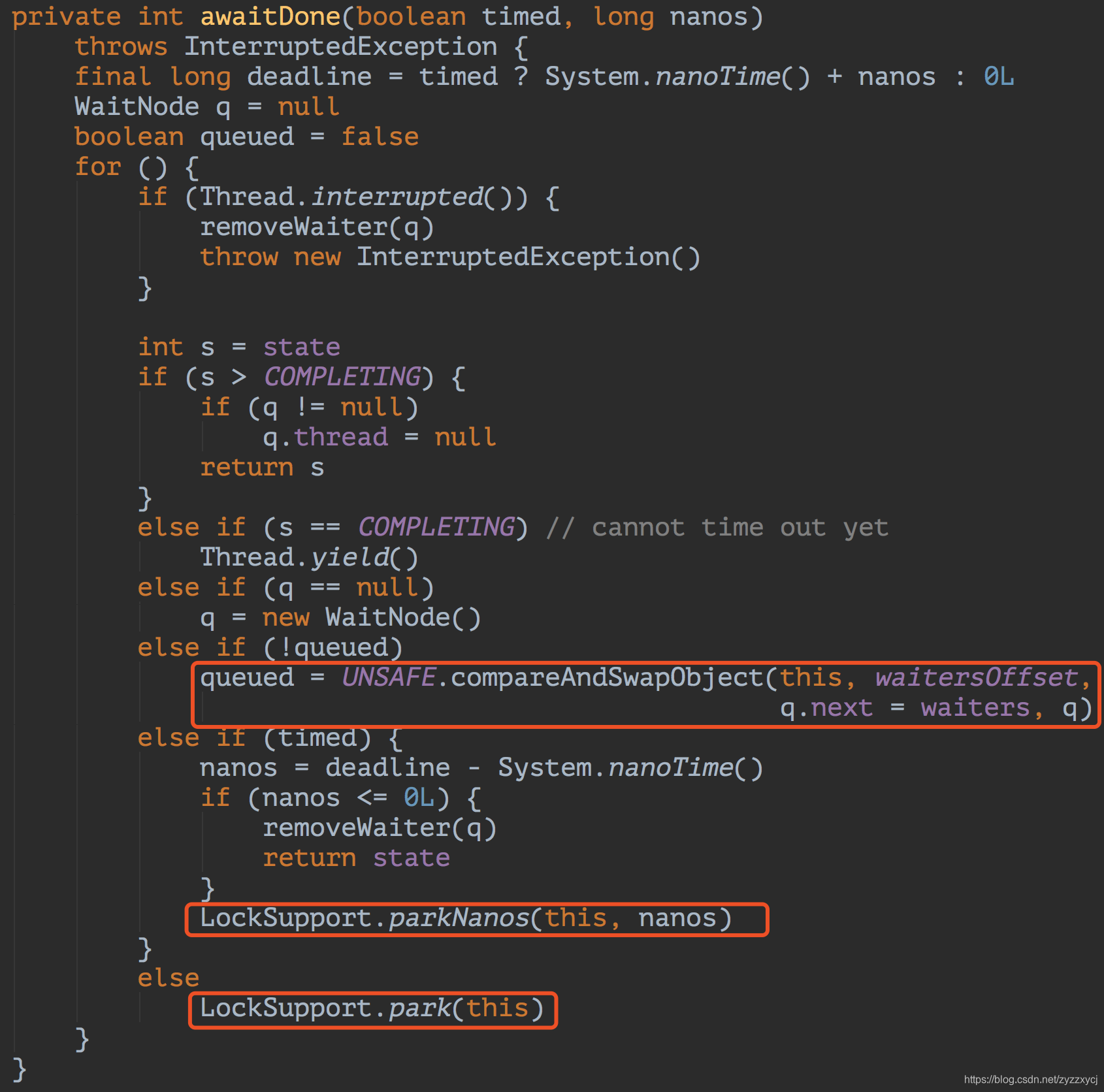
awaitDone方法里,首先会用到之前说的CAS操作(参考深入理解sun.misc.Unsafe原理),将线程封装为WaitNode,保持下来,以供后续唤醒线程时用。再就是调用了LockSupport的park/parkNanos组塞住当前线程。
上边已经说完了阻塞等待任务结果的逻辑,接下来再看看线程池执行完任务,唤醒等待线程的逻辑实现。
前边说了,咱们提交的基于Callable实现的任务,已经被封装为FutureTask任务提交给了线程池执行,任务的执行就是FutureTask的run方法执行。如下是FutureTask的run方法: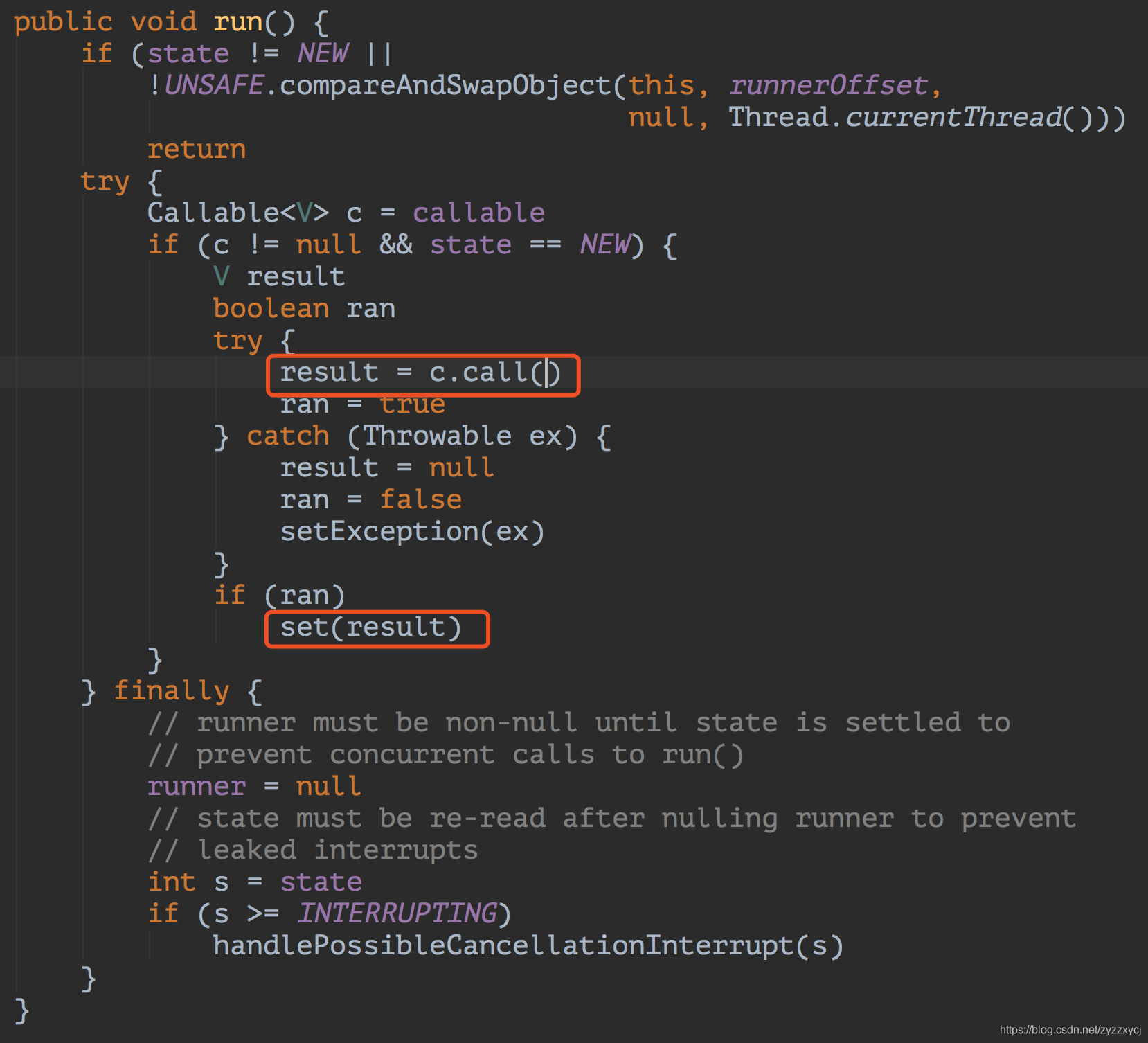
c.call()就是执行我们提交的任务,任务执行完后调用了set方法,进入set方法发现set方法调用了finishCompletion方法,想必唤醒线程的工作就在这里边了,看看代码实现吧:
这边通过CAS操作将所有等待的线程拿出来,感觉越来越接近了,再看下最后完成方法finishCompletion: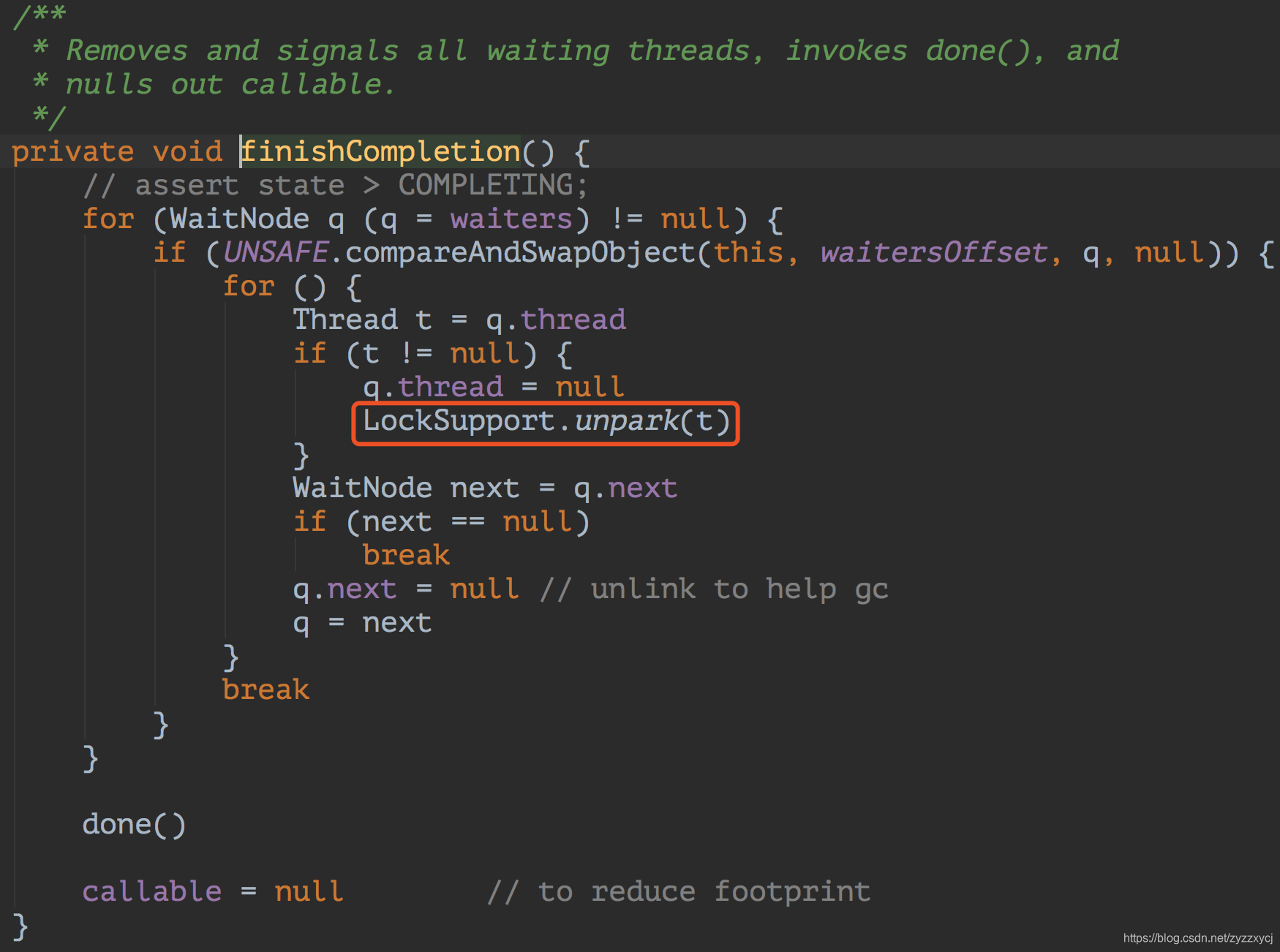
果然,这边使用LockSupport的unpark唤醒每个线程。
ps. 这边对无用变量的回收细节也是十分惊人,可以看上方的代码注释。
阻塞队列中的应用
在使用线程池的过程中,不知道你有没有这么一个疑问:线程池里没有任务时,线程池里的线程在干嘛呢?
看过我的这篇文章ThreadPoolExecutor详解及线程池优化的一定知道,线程会调用队列的take方法阻塞等待新任务。那队列的take方法是不是也跟Future的get方法实现一样呢?咱们来看看源码实现。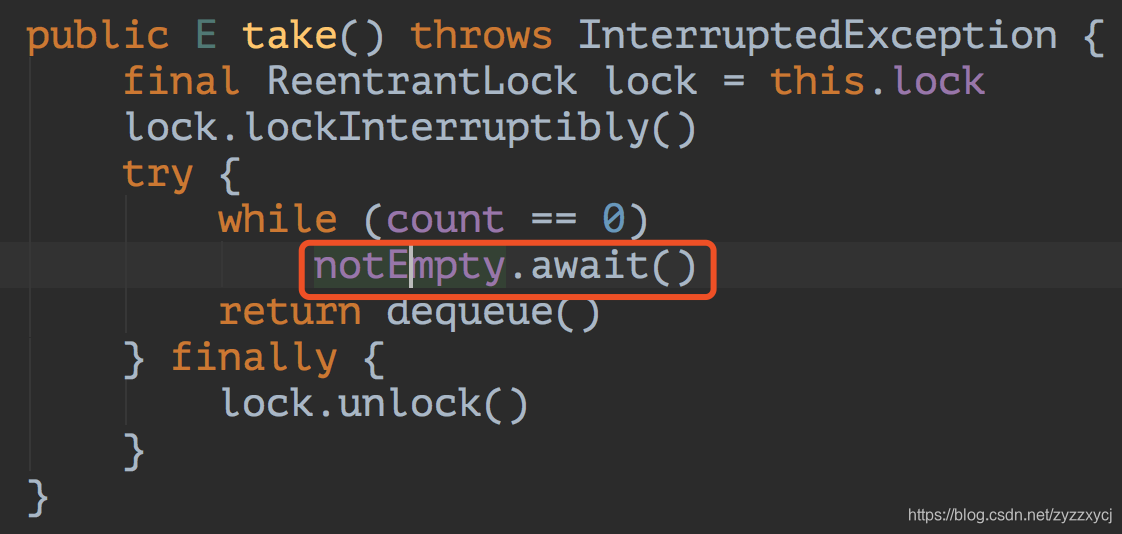
与想象的有点出入,他是使用了Lock的Condition的await方法实现线程阻塞。但当我们继续追下去进入await方法,发现是通过AQS的await方法实现的,还是使用了LockSupport: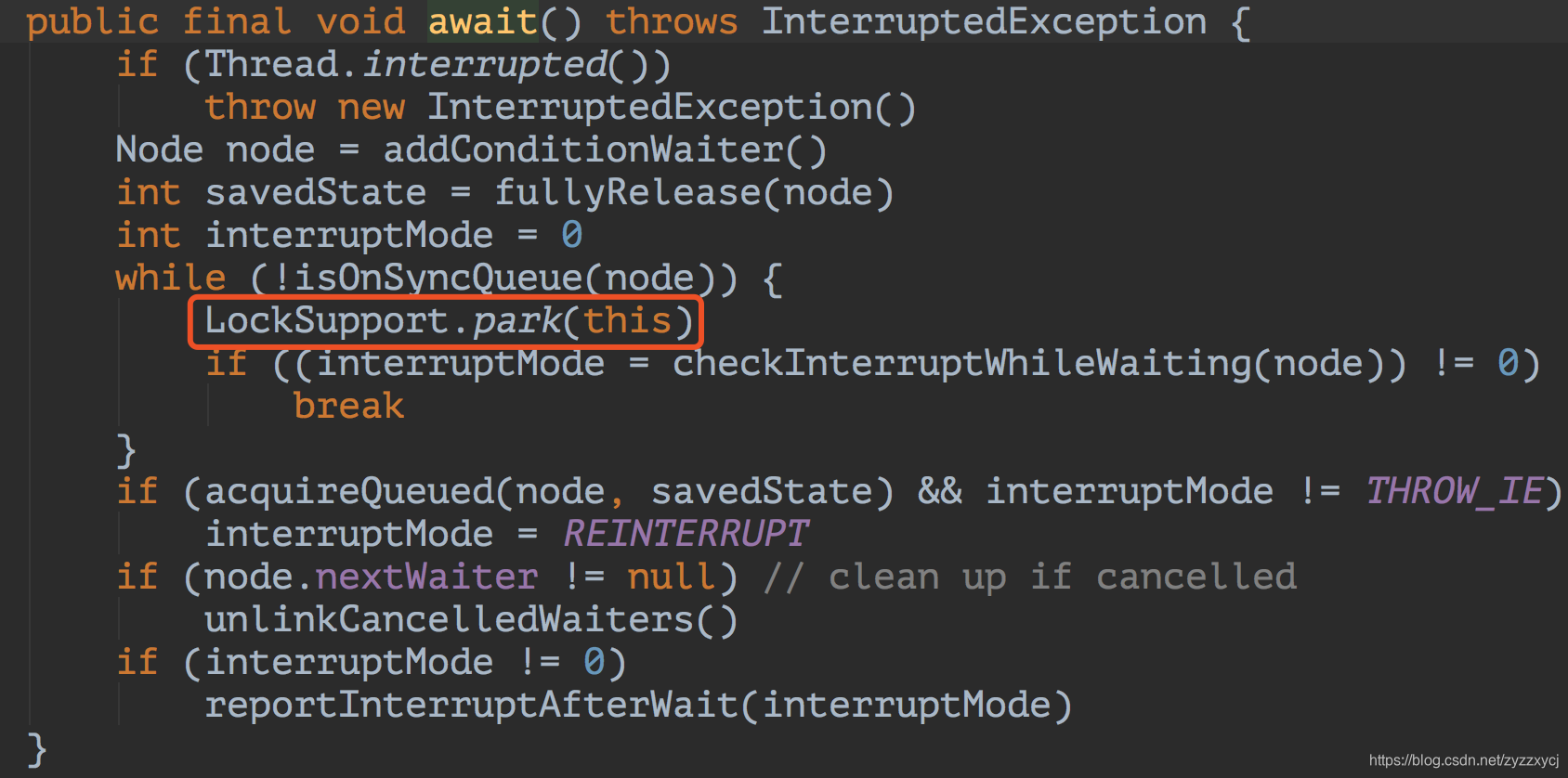
小结
多次调用unpark方法和调用一次unpark方法效果一样,因为都是直接将_counter赋值为1,而不是加1。简单说就是:线程A连续调用两次LockSupport.unpark(B)方法唤醒线程B,然后线程B调用两次LockSupport.park()方法, 线程B依旧会被阻塞。因为两次unpark调用效果跟一次调用一样,只能让线程B的第一次调用park方法不被阻塞,第二次调用依旧会阻塞。
这个比较讲的透彻一些。
转载地址:https://blog.csdn.net/zyzzxycj/article/details/90268381


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通