

分布式事务常见解决方案
首先大家想过没:既然有了事务,并且使用 spring 的@Transactional 注解来控制事务是如此的方便,那为啥还要搞一个分布式事务的概念出来啊? 更进一步,分布式事务和普通事务到底是啥关系?有什么区别?分布式事务又是为了解决什么问题出现的?
各种疑问接踵而至,别着急,带着这些思考,咱们接下来就详细聊聊分布式事务。
既然叫分布式事务,那么必然和分布式有点关系啦!简单来说,分布式事务指的就是分布式系统中的事务。
首先来看看下面的图:
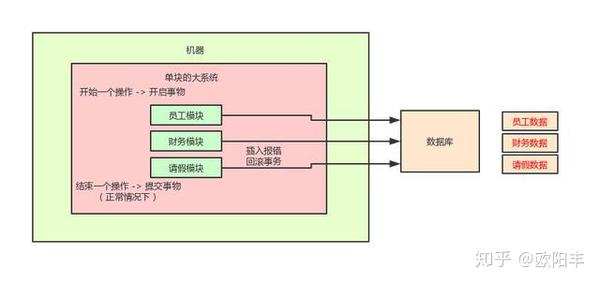
如上图所示,一个单块系统有 3 个模块:员工模块、财务模块和请假模块。我们现在有一个操作需要按顺序去调用完成这 3 个模块中的接口。
这个操作是一个整体,包含在一个事务中,要么同时成功要么同时失败回滚。不成功便成仁,这个都没有问题。
但是当我们把单块系统拆分成分布式系统或者微服务架构,事务就不是上面那么玩儿了。
首先我们来看看拆分成分布式系统之后的架构图,如下所示:
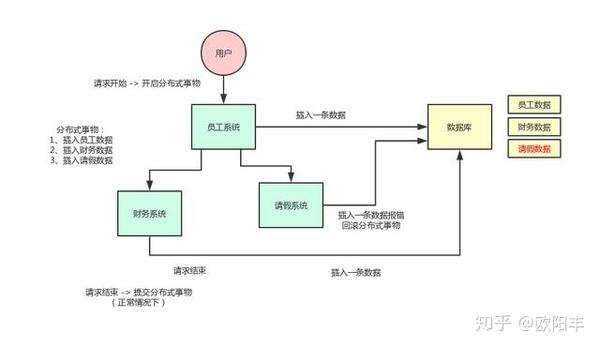
上图是同一个操作在分布式系统中的执行情况。员工模块、财务模块和请假模块分别给拆分成员工系统、财务系统和请假系统。
比如一个用户进行一个操作,这个操作需要先调用员工系统预先处理一下,然后通过 http 或者 rpc 的方式分别调用财务系统和请假系统的接口做进一步的处理,它们的操作都需要分别落地到数据库中。
这 3 个系统的一系列操作其实是需要全部被包裹在同一个分布式事务中的,此时这 3 个系统的操作,要么同时成功要么同时失败。
分布式系统中完成一个操作通常需要多个系统间协同调用和通信,比如上面的例子。
三个子系统:员工系统、财务系统、请假系统之间就通过 http 或者 rpc 进行通信,而不再是一个单块系统中不同模块之间的调用,这就是分布式系统和单块系统最大的区别。
一些平时不太关注分布式架构的同学,看到这里可能会说:我直接用 spring 的@Transactional 注解就 OK 了啊,管那么多干嘛!
但是这里极其重要的一点:单块系统是运行在同一个 JVM 进程中的,但是分布式系统中的各个系统运行在各自的 JVM 进程中。
因此你直接加@Transactional 注解是不行的,因为它只能控制同一个 JVM 进程中的事务,但是对于这种跨多个 JVM 进程的事务无能无力。
分布式事务的几种实现思路
搞清楚了啥是分布式事务,那么分布式事务到底是怎么玩儿的呢? 下边就来给大家介绍几种分布式事务的实现方案。
可靠消息最终一致性方案
整个流程图如下所示:
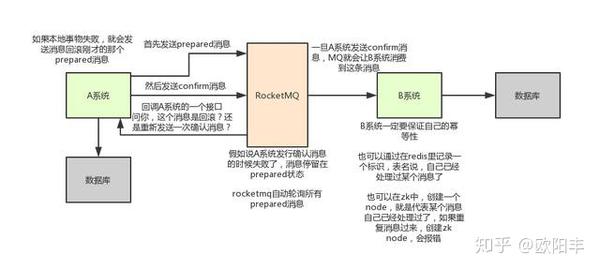
我们来解释一下这个方案的大概流程:
- A 系统先发送一个 prepared 消息到 mq,如果这个 prepared 消息发送失败那么就直接取消操作别执行了,后续操作都不再执行。
- 如果这个消息发送成功过了,那么接着执行 A 系统的本地事务,如果执行失败就告诉 mq 回滚消息,后续操作都不再执行。
- 如果 A 系统本地事务执行成功,就告诉 mq 发送确认消息。
- 那如果 A 系统迟迟不发送确认消息呢? 此时 mq 会自动定时轮询所有 prepared 消息,然后调用 A 系统事先提供的接口,通过这个接口反查 A 系统的上次本地事务是否执行成功 如果成功,就发送确认消息给 mq;失败则告诉 mq 回滚消息(后续操作都不再执行)。
- 此时 B 系统会接收到确认消息,然后执行本地的事务,如果本地事务执行成功则事务正常完成。
- 如果系统 B 的本地事务执行失败了咋办? 基于 mq 重试咯,mq 会自动不断重试直到成功,如果实在是不行,可以发送报警由人工来手工回滚和补偿。 这种方案的要点就是可以基于 mq 来进行不断重试,最终一定会执行成功的。 因为一般执行失败的原因是网络抖动或者数据库瞬间负载太高,都是暂时性问题。 通过这种方案,99.9%的情况都是可以保证数据最终一致性的,剩下的 0.1%出问题的时候,就人工修复数据呗。
适用场景: 这个方案的使用还是比较广,目前国内互联网公司大都是基于这种思路玩儿的。
最大努力通知方案
整个流程图如下所示:
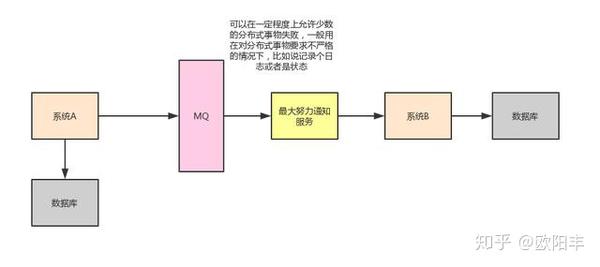
这个方案的大致流程:
- 系统 A 本地事务执行完之后,发送个消息到 MQ。
- 这里会有个专门消费 MQ 的最大努力通知服务,这个服务会消费 MQ,然后写入数据库中记录下来,或者是放入个内存队列。接着调用系统 B 的接口。
- 假如系统 B 执行成功就万事 ok 了,但是如果系统 B 执行失败了呢? 那么此时最大努力通知服务就定时尝试重新调用系统 B,反复 N 次,最后还是不行就放弃。
这套方案和上面的可靠消息最终一致性方案的区别:
可靠消息最终一致性方案可以保证的是只要系统 A 的事务完成,通过不停(无限次)重试来保证系统 B 的事务总会完成。
但是最大努力方案就不同,如果系统 B 本地事务执行失败了,那么它会重试 N 次后就不再重试,系统 B 的本地事务可能就不会完成了。
至于你想控制它究竟有“多努力”,这个需要结合自己的业务来配置。
比如对于电商系统,在下完订单后发短信通知用户下单成功的业务场景中,下单正常完成,但是到了发短信的这个环节由于短信服务暂时有点问题,导致重试了 3 次还是失败。
那么此时就不再尝试发送短信,因为在这个场景中我们认为 3 次就已经算是尽了“最大努力”了。
简单总结:就是在指定的重试次数内,如果能执行成功那么皆大欢喜,如果超过了最大重试次数就放弃,不再进行重试。
适用场景: 一般用在不太重要的业务操作中,就是那种完成的话是锦上添花,但失败的话对我也没有什么坏影响的场景。
比如上边提到的电商中的部分通知短信,就比较适合使用这种最大努力通知方案来做分布式事务的保证。
tcc 强一致性方案
TCC 的全称是:
- Try(尝试)
- Confirm(确认/提交)
- Cancel(回滚)。
这个其实是用到了补偿的概念,分为了三个阶段:
- Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行锁定或者预留;
- Confirm 阶段:这个阶段说的是在各个服务中执行实际的操作;
- Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作。
还是给大家举个例子:
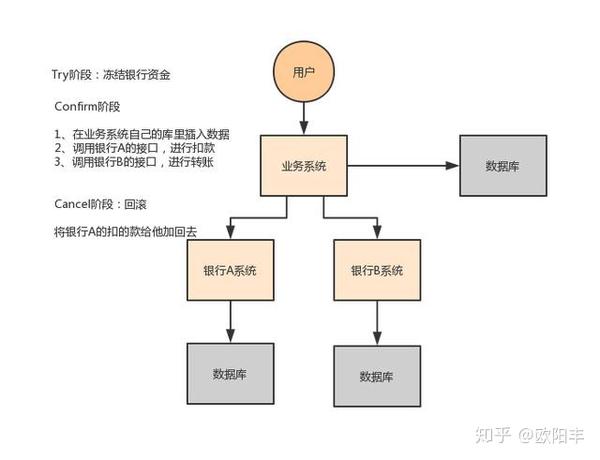
比如跨银行转账的时候,要涉及到两个银行的分布式事务,如果用 TCC 方案来实现,思路是这样的:
- Try 阶段:先把两个银行账户中的资金给它冻结住就不让操作了;
- Confirm 阶段:执行实际的转账操作,A 银行账户的资金扣减,B 银行账户的资金增加;
- Cancel 阶段:如果任何一个银行的操作执行失败,那么就需要回滚进行补偿,就是比如 A 银行账户如果已经扣减了,但是 B 银行账户资金增加失败了,那么就得把 A 银行账户资金给加回去。
适用场景:这种方案说实话几乎很少有人使用,我们用的也比较少,但是也有使用的场景。
因为这个事务回滚实际上是严重依赖于你自己写代码来回滚和补偿了,会造成补偿代码巨大,非常之恶心。
比如说我们,一般来说跟钱相关的,跟钱打交道的,支付、交易相关的场景,我们会用 TCC,严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性,在资金上不允许出现问题。
比较适合的场景:除非你是真的一致性要求太高,是你系统中核心之核心的场景,比如常见的就是资金类的场景,那你可以用 TCC 方案了。 你需要自己编写大量的业务逻辑,自己判断一个事务中的各个环节是否 ok,不 ok 就执行补偿/回滚代码。
而且最好是你的各个业务执行的时间都比较短。
但是说实话,一般尽量别这么搞,自己手写回滚逻辑,或者是补偿逻辑,实在太恶心了,那个业务代码很难维护。
总结
本篇介绍了什么是分布式事务,然后还介绍了最常用的 3 种分布式事务方案。但除了上边的方案外,其实还有两阶段提交方案(XA 方案)和本地消息表等方案。但是说实话极少有公司使用这些方案,鉴于篇幅所限,不做介绍。
链接:https://zhuanlan.zhihu.com/p/85790242


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2018-07-13 Java - web.xml文件中可以配置哪些内容?
2018-07-13 一个web项目web.xml的配置中<context-param>配置作用
2017-07-13 sqlserver常用函数